This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Iceberg offers distinct advantages through its metadata layer over Parquet, such as improved data management, performance optimization, and integration with various query engines. Icebergs table format separates data files from metadata files, enabling efficient data modifications without full dataset rewrites.
Central to a transactional data lake are open table formats (OTFs) such as Apache Hudi , Apache Iceberg , and Delta Lake , which act as a metadata layer over columnar formats. Originally open sourced in November 2023 under the name OneTable, with contributions from amongst others OneHouse , it was licensed under Apache 2.0.
Since its release in January 2021, the OpenSearch project has released 14 versions through June 2023. In this post, we provide a review of all the exciting features releases in OpenSearch Service in the first half of 2023. In July 2023, we previewed support for a third collection type: vector search. in OpenSearch Service).
This means the data files in the data lake aren’t modified during the migration and all Apache Iceberg metadata files (manifests, manifest files, and table metadata files) are generated outside the purview of the data. In this method, the metadata are recreated in an isolated environment and colocated with the existing data files.
These formats enable ACID (atomicity, consistency, isolation, durability) transactions, upserts, and deletes, and advanced features such as time travel and snapshots that were previously only available in data warehouses. It will never remove files that are still required by a non-expired snapshot.
Apache Iceberg is an open table format for very large analytic datasets, which captures metadata information on the state of datasets as they evolve and change over time. Apache Iceberg addresses customer needs by capturing rich metadata information about the dataset at the time the individual data files are created.
RIO is really great",date("2023-04-06"),2023)""") You can check the new snapshot is created after this append operation by querying the Iceberg snapshot: spark.sql("""SELECT * FROM dev.db.amazon_reviews_iceberg.snapshots""").show() We expire the old snapshots from the table and keep only the last two.
Iceberg tables store metadata in manifest files. As the number of data files increase, the amount of metadata stored in these manifest files also increases, leading to longer query planning time. The query runtime also increases because it’s proportional to the number of data or metadata file read operations.
The snapshotId of the source tables involved in the materialized view are also maintained in the metadata. Subsequently, these snapshot IDs are used to determine the delta changes that should be applied to the materialized view rows. Furthermore, it is partitioned on the d_year column.
Iceberg employs internal metadata management that keeps track of data and empowers a set of rich features at scale. The Data Catalog provides a central location to govern and keep track of the schema and metadata. For example, from 2023/02/20 14:40:41 to 2023-02-20 14:40:41.000 UTC.
At a high level, the core of Langley’s architecture is based on a set of Amazon Simple Queue Service (Amazon SQS) queues and AWS Lambda functions, and a dedicated RDS database to store ETL job data and metadata. In 2023, AWS announced the upcoming deprecation of Data Pipeline , one of the core services used by Langley.
You can see the time each task spends idling while waiting for the Redshift cluster to be created, snapshotted, and paused. Airflow will cache variables and connections locally so that they can be accessed faster during DAG parsing, without having to fetch them from the secrets backend, environments variables, or metadata database.
In fact, according to the Identity Theft Resource Center (ITRC) Annual Data Breach Report , there were 2,365 cyber attacks in 2023 with more than 300 million victims, and a 72% increase in data breaches since 2021. Today, cyber defenders face an unprecedented set of challenges as they work to secure and protect their organizations.
Regulations and laws are often volatile as political influences can upend them on a moments notice: The USA Executive Order (EO) on Safe, Secure and Trustworthy Artificial Intelligence (14110) issued on October 30, 2023, was rescinded on January 20, 2025. associated with every decision made by the AI system.
We fetch the metadata of the users_xxxxxx table from Athena. The following are a few important considerations regarding how the Lambda function handles Iceberg table metadata changes: In this approach, target metadata takes precedence during DML operations. It’s imperative that the source and target metadata match.
By using features like Icebergs compaction, OTFs streamline maintenance, making it straightforward to manage object and metadata versioning at scale. Enabling automatic compaction on Iceberg tables reduces metadata overhead on your Iceberg tables and improves query performance. The Data Catalog manages the metadata for the datasets.
In fact, according to the Identity Theft Resource Center (ITRC) Annual Data Breach Report , there were 2,365 cyber attacks in 2023 with more than 300 million victims, and a 72% increase in data breaches since 2021. Today, cyber defenders face an unprecedented set of challenges as they work to secure and protect their organizations.
The first version of Talk to Your Graph (or TTYG for short) was released in 2023 and it was my baby. Use of assistant and thread metadata. So what is that metadata? The OpenAI Assistants API provides a set of custom metadata fields for both assistants and threads. Both must be strings. version Internal use only.
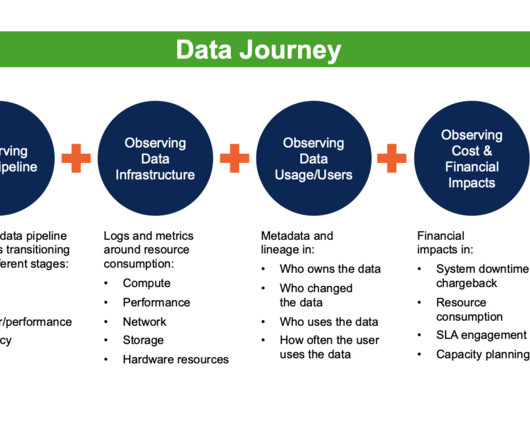
On 20 July 2023, Gartner released the article “ Innovation Insight: Data Observability Enables Proactive Data Quality ” by Melody Chien. Data Observability leverages five critical technologies to create a data awareness AI engine: data profiling, active metadata analysis, machine learning, data monitoring, and data lineage.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



























Let's personalize your content