This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Today, Amazon Redshift is used by customers across all industries for a variety of use cases, including datawarehouse migration and modernization, near real-time analytics, self-service analytics, datalake analytics, machine learning (ML), and data monetization.
Founded as Software Development Laboratories in 1977, Oracle is a behemoth in the software industry, generating more than $50 billion in revenue in its fiscal year 2024. Exadata is Oracles engineered system for data and now artificial intelligence (AI) operations. for several years before adopting the name Oracle in 1982.
Amazon Web Services (AWS) has been recognized as a Leader in the 2024 Gartner Magic Quadrant for Data Integration Tools. This recognition, we feel, reflects our ongoing commitment to innovation and excellence in data integration, demonstrating our continued progress in providing comprehensive data management solutions.
At AWS re:Invent 2024, we announced the next generation of Amazon SageMaker , the center for all your data, analytics, and AI. Unified access to your data is provided by Amazon SageMaker Lakehouse , a unified, open, and secure data lakehouse built on Apache Iceberg open standards.
The adoption of cloud environments for analytic workloads has been a key feature of the data platforms sector in recent years. For two-thirds (66%) of participants in ISG’s DataLake Dynamic Insights Research, the primary data platform used for analytics is cloud based.
This week on the keynote stages at AWS re:Invent 2024, you heard from Matt Garman, CEO, AWS, and Swami Sivasubramanian, VP of AI and Data, AWS, speak about the next generation of Amazon SageMaker , the center for all of your data, analytics, and AI. The relationship between analytics and AI is rapidly evolving.
AWS re:Invent 2024, the flagship annual conference, took place December 26, 2024, in Las Vegas, bringing together thousands of cloud enthusiasts, innovators, and industry leaders from around the globe.
Data architecture has evolved significantly to handle growing data volumes and diverse workloads. Initially, datawarehouses were the go-to solution for structured data and analytical workloads but were limited by proprietary storage formats and their inability to handle unstructured data.
Enterprise data is brought into datalakes and datawarehouses to carry out analytical, reporting, and data science use cases using AWS analytical services like Amazon Athena , Amazon Redshift , Amazon EMR , and so on. Then, invoke the model.
With this new functionality, customers can create up-to-date replicas of their data from applications such as Salesforce, ServiceNow, and Zendesk in an Amazon SageMaker Lakehouse and Amazon Redshift. SageMaker Lakehouse gives you the flexibility to access and query your data in-place with all Apache Iceberg compatible tools and engines.
I previously wrote about the importance of open table formats to the evolution of datalakes into data lakehouses. The concept of the datalake was initially proposed as a single environment where data could be combined from multiple sources to be stored and processed to enable analysis by multiple users for multiple purposes.
Amazon Redshift is a fully managed, AI-powered cloud datawarehouse that delivers the best price-performance for your analytics workloads at any scale. With over 85,000 queries executed in preview, Amazon Redshift announced the general availability in September 2024. Choose Run all on each notebook tab.
Amazon Q data integration , introduced in January 2024, allows you to use natural language to author extract, transform, load (ETL) jobs and operations in AWS Glue specific data abstraction DynamicFrame.
This approach has been widely used in datawarehouses to track changes in various dimensions such as customer information, product details, and employee data. In the example of the previous section, heres what the SCD Type-2 looks like assuming the update operation is performed on December 11, 2024.
When you build your transactional datalake using Apache Iceberg to solve your functional use cases, you need to focus on operational use cases for your S3 datalake to optimize the production environment. availability. show() The snapshots that have expired show the latest snapshot ID as null.
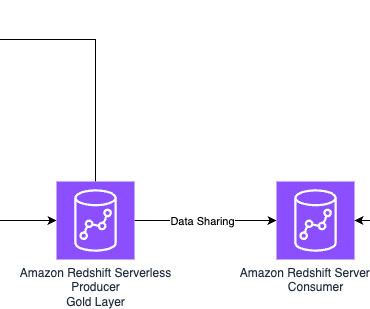
The current scaling approach of Amazon Redshift Serverless increases your compute capacity based on the query queue time and scales down when the queuing reduces on the datawarehouse. This post also includes example SQLs, which you can run on your own Redshift Serverless datawarehouse to experience the benefits of this feature.
At the same time, they need to optimize operational costs to unlock the value of this data for timely insights and do so with a consistent performance. With this massive data growth, data proliferation across your data stores, datawarehouse, and datalakes can become equally challenging.
Reading Time: 3 minutes As we head into 2024, it is imperative for data management leaders to look in their rear-view mirrors to assess and, if needed, refine their data management strategies.
Reading Time: 3 minutes As we move deeper into 2024, it is imperative for data management leaders to look in their rear-view mirrors to assess and, if needed, refine their data management strategies. One thing is clear; if data-centric organizations want to succeed in.
Amazon Redshift , a warehousing service, offers a variety of options for ingesting data from diverse sources into its high-performance, scalable environment. Federated queries allow querying data across Amazon RDS for MySQL and PostgreSQL data sources without the need for extract, transform, and load (ETL) pipelines.
Amazon DataZone is a powerful data management service that empowers data engineers, data scientists, product managers, analysts, and business users to seamlessly catalog, discover, analyze, and govern data across organizational boundaries, AWS accounts, datalakes, and datawarehouses.
Reading Time: 2 minutes In 2024, generative AI (GenAI) has entered virtually every sphere of technology. However, companies are still struggling to manage data effectively, to implement GenAI applications that deliver proven business value. Gartner predicts that by the end of this year, 30%.
In February 2024, we announced the release of the Data Solutions Framework (DSF) , an opinionated open source framework for building data solutions on AWS. In this post, we demonstrate how to use the AWS CDK and DSF to create a multi-datawarehouse platform based on Amazon Redshift Serverless.
Many BusinessObjects customers now use Cloud based datawarehouses or datalakes and Snowflake is one of the most popular solutions chosen. By using the new Web Intelligence as a data source feature, you can dramatically reduce the number of times you would need to query your datawarehouse.
Il recepimento deve avvenire entro il 17 ottobre 2024 e le imprese sono chiamate, fin da ora, a verificare che i propri sistemi siano “a norma”. Per esempio, “i PoC aiutano a definire i parametri in base ai quali organizzare i datalake o i criteri per la digitalizzazione dei workflow.
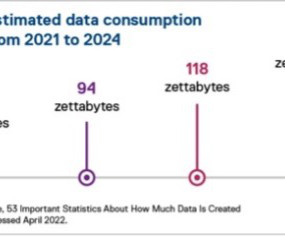
All organizations need an optimized, future-proofed data architecture to move AI forward. Complexity slows innovation Data growth is skyrocketing. One estimate 3 states that by 2024, 149 zettabytes will be created every day: that’s 1.7 MB every second. A zettabyte has 21 zeroes. What does that mean? Want to learn more?
According to Gartner’s 2021 Core Financial Magic Quadrant , over 50% of the ERP market is expected to be cloud-based by 2024. Questions to consider are: How much data do you need to import? When migrating to the cloud, there are a variety of different approaches you can take to maintain your data strategy.
These organizations have a huge demand for lakehouse solutions that combine the best of datawarehouses and datalakes to simplify data management with easy access to all data from their preferred engines. Amazon SageMaker Unified Studio , Amazon EMR 7.5.0 and higher, and AWS Glue 5.0
Many organizations turn to datalakes for the flexibility and scale needed to manage large volumes of structured and unstructured data. Recently, NI embarked on a journey to transition their legacy datalake from Apache Hive to Apache Iceberg. NIs leading brands, Top10.com
Data platforms support and enable operational applications used to run the business, as well as analytic applications used to evaluate the business, including AI, machine learning and generative AI. Regards, Matt Aslett
La segunda pata está íntimamente relacionada con el gobierno del dato, especialmente con la generación de un datawarehouse que permita al usuario interno poner el dato en el centro y generar una dinámica de autoservicio, así como desarrollar una toma de decisiones basada en la analítica mucho más eficiente.
datalakes & warehouses like Cloudera, Google Big Query, etc., Scalability: Your source systems, data volumes, and calculation complexities change as your business evolves. Organisations continuing with SAP BPC even after 2024, will incur the regular software AMC, and the high change request costs.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content