

Enriching metadata for accurate text-to-SQL generation for Amazon Athena
AWS Big Data
OCTOBER 14, 2024
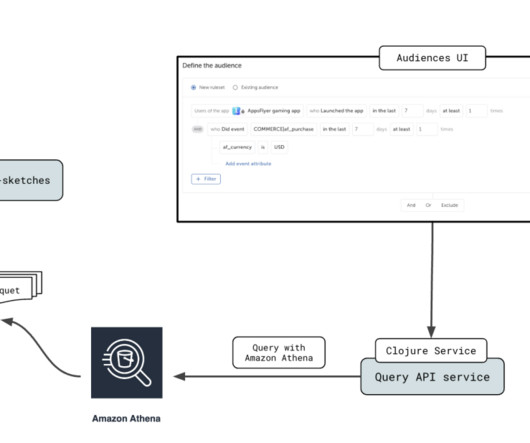
Writing SQL queries requires not just remembering the SQL syntax rules, but also knowledge of the tables metadata, which is data about table schemas, relationships among the tables, and possible column values. Although LLMs can generate syntactically correct SQL queries, they still need the table metadata for writing accurate SQL query.












































Let's personalize your content