This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Some challenges include data infrastructure that allows scaling and optimizing for AI; data management to inform AI workflows where data lives and how it can be used; and associated data services that help data scientists protect AI workflows and keep their models clean.
Inventory management benefits from historical data for analyzing sales patterns and optimizing stock levels. Implementing such a system can be complex, requiring careful consideration of data storage, retrieval mechanisms, and query optimization. You can obtain the table snapshots by querying for db.table.snapshots.
Gartner says worldwide shipments of AI PCs – and generative AI (genAI) smartphones – are projected to total 295 million units by the end of 2024, up from 29 million units in 2023. Using Microsoft’s Recall 4 snapshotting technology, the file is safely discovered. 3 Cocreator is optimized for English text prompts.
With the launch of Amazon Redshift Serverless and the various provisioned instance deployment options , customers are looking for tools that help them determine the most optimal data warehouse configuration to support their Amazon Redshift workloads. Launch the producer warehouse by restoring the snapshot to a 32 RPU serverless namespace.
When you build your transactional data lake using Apache Iceberg to solve your functional use cases, you need to focus on operational use cases for your S3 data lake to optimize the production environment. This property is set to true by default. AIMD is supported for Amazon EMR releases 6.4.0 cluster with installed applications Hadoop 3.3.3,
Use case Consider a large company that relies heavily on data-driven insights to optimize its customer support processes. incident" For Query , enter the following statement to record initial snapshot results before CDC: SELECT number , short_description , description FROM "zero_etl_demo_db"."incident"
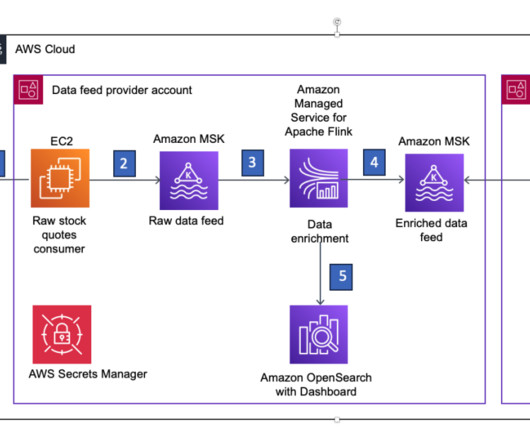
Apache Flink is an opensource distributed processing engine, offering powerful programming interfaces for both stream and batch processing, with first-class support for stateful processing, event time semantics, checkpointing, snapshots and rollback. To run the application, choose Run , select Run with latest snapshot , and choose Run.
IDC predicts that by 2023 over half of new enterprise IT infrastructure deployed will be at the edge; by 2024 the number of apps at the edge will balloon by 800%. A recent survey conducted by IDC and sponsored by Lumen Technologies and Intel Corporation indicates that two-thirds of global IT leaders are implementing edge computing.
which introduces a number of bug fixes over version 1.19.0 , released in March 2024. This flexibility optimizes job performance by reducing checkpoint frequency during backlog phases, enhancing overall throughput. AWS led the community release of the version 1.19.1, This feature only involves source connectors.
Data maintenance When working with data lake table formats such as Iceberg, its essential to engage in routine maintenance tasks to optimize table metadata file management, preventing a large number of unnecessary files from accumulating and promptly removing any unused files.
To optimize their security operations, organizations are adopting modern approaches that combine real-time monitoring with scalable data analytics. Firehose delivers streaming data with configurable buffering options that can be optimized for near-zero latency. To address this, regular table optimization is recommended.
Icebergs robust metadata layers, including snapshots and manifest files, were seamlessly updated to capture these changes, providing efficient and accurate synchronization between Hive and Iceberg tables. Iceberg-to-Hive reverse CDC pipeline Objective : Support Hive consumers while allowing ETL pipelines to transition to Iceberg.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















Let's personalize your content