This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Q dataintegration , introduced in January 2024, allows you to use natural language to author extract, transform, load (ETL) jobs and operations in AWS Glue specific data abstraction DynamicFrame. In this post, we discuss how Amazon Q dataintegration transforms ETL workflow development.
Data is becoming more valuable and more important to organizations. At the same time, organizations have become more disciplined about the data on which they rely to ensure it is robust, accurate and governed properly.
With the growing emphasis on data, organizations are constantly seeking more efficient and agile ways to integrate their data, especially from a wide variety of applications. SageMaker Lakehouse gives you the flexibility to access and query your data in-place with all Apache Iceberg compatible tools and engines.
At AWS re:Invent 2024, we announced the next generation of Amazon SageMaker , the center for all your data, analytics, and AI. It enables teams to securely find, prepare, and collaborate on data assets and build analytics and AI applications through a single experience, accelerating the path from data to value.
Speaker: Anthony Roach, Director of Product Management at Tableau Software, and Jeremiah Morrow, Partner Solution Marketing Director at Dremio
Tableau works with Strategic Partners like Dremio to build dataintegrations that bring the two technologies together, creating a seamless and efficient customer experience. As a result of a strategic partnership, Tableau and Dremio have built a native integration that goes well beyond a traditional connector.
Amazon Web Services (AWS) has been recognized as a Leader in the 2024 Gartner Magic Quadrant for DataIntegration Tools. This recognition, we feel, reflects our ongoing commitment to innovation and excellence in dataintegration, demonstrating our continued progress in providing comprehensive data management solutions.
This week on the keynote stages at AWS re:Invent 2024, you heard from Matt Garman, CEO, AWS, and Swami Sivasubramanian, VP of AI and Data, AWS, speak about the next generation of Amazon SageMaker , the center for all of your data, analytics, and AI. The relationship between analytics and AI is rapidly evolving.
A datalake is a centralized repository that you can use to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data and then run different types of analytics for better business insights.
In this blog post, we dive into different data aspects and how Cloudinary breaks the two concerns of vendor locking and cost efficient dataanalytics by using Apache Iceberg, Amazon Simple Storage Service (Amazon S3 ), Amazon Athena , Amazon EMR , and AWS Glue.
Today, we’re excited to announce general availability of Amazon Q dataintegration in AWS Glue. Amazon Q dataintegration, a new generative AI-powered capability of Amazon Q Developer , enables you to build dataintegration pipelines using natural language.
Amazon Redshift , launched in 2013, has undergone significant evolution since its inception, allowing customers to expand the horizons of data warehousing and SQL analytics. This allowed customers to scale read analytics workloads and offered isolation to help maintain SLAs for business-critical applications.
Without integrating mainframe data, it is likely that AI models and analytics initiatives will have blind spots. However, according to the same study, only 28% of businesses are fully tapping into the potential of mainframe data insights despite widespread acknowledgment of the datas value for AI and analytics.
Unlocking the true value of data often gets impeded by siloed information. Traditional data management—wherein each business unit ingests raw data in separate datalakes or warehouses—hinders visibility and cross-functional analysis. Amazon DataZone natively supports data sharing for Amazon Redshift data assets.
In the current industry landscape, datalakes have become a cornerstone of modern data architecture, serving as repositories for vast amounts of structured and unstructured data. However, efficiently managing and synchronizing data within these lakes presents a significant challenge.
We often see requests from customers who have started their data journey by building datalakes on Microsoft Azure, to extend access to the data to AWS services. In such scenarios, data engineers face challenges in connecting and extracting data from storage containers on Microsoft Azure.
Google Analytics 4 (GA4) provides valuable insights into user behavior across websites and apps. But what if you need to combine GA4 data with other sources or perform deeper analysis? It also helps you securely access your data in operational databases, datalakes, or third-party datasets with minimal movement or copying of data.
Migrating to the cloud does not solve the problems associated with performing analytics and business intelligence on data stored in disparate systems. Also, the computing power needed to process large volumes of data consists of clusters of servers with hundreds or thousands of nodes that can be difficult to administer.
Tens of thousands of customers today use Amazon Redshift to analyze exabytes of data and run analytical queries, making it the most widely used cloud data warehouse. With Amazon Redshift, you can query the data in your S3 datalake using a central AWS Glue metastore from your Redshift data warehouse.
They understand that a one-size-fits-all approach no longer works, and recognize the value in adopting scalable, flexible tools and open data formats to support interoperability in a modern data architecture to accelerate the delivery of new solutions.
With data becoming the driving force behind many industries today, having a modern data architecture is pivotal for organizations to be successful. In this post, we describe Orca’s journey building a transactional datalake using Amazon Simple Storage Service (Amazon S3), Apache Iceberg, and AWS Analytics.
Beyond breaking down silos, modern data architectures need to provide interfaces that make it easy for users to consume data using tools fit for their jobs. Data must be able to freely move to and from data warehouses, datalakes, and data marts, and interfaces must make it easy for users to consume that data.
The rapid adoption of software as a service (SaaS) solutions has led to data silos across various platforms, presenting challenges in consolidating insights from diverse sources. Introducing the Salesforce connector for AWS Glue To meet the demands of diverse dataintegration use cases, AWS Glue now supports SaaS connectivity for Salesforce.
Organizations need to collect, organize, and analyze their data across multi-cloud, hybrid cloud, and datalakes. In turn, enterprises are increasingly looking for machine-learning-powered integration tools to synchronize data for analytics, improve employee productivity, and prepare data for analytics.
For container terminal operators, data-driven decision-making and efficient data sharing are vital to optimizing operations and boosting supply chain efficiency. Enhance agility by localizing changes within business domains and clear data contracts. Eliminate centralized bottlenecks and complex data pipelines.
Analytics are prone to frequent data errors and deployment of analytics is slow and laborious. The strategic value of analytics is widely recognized, but the turnaround time of analytics teams typically can’t support the decision-making needs of executives coping with fast-paced market conditions.
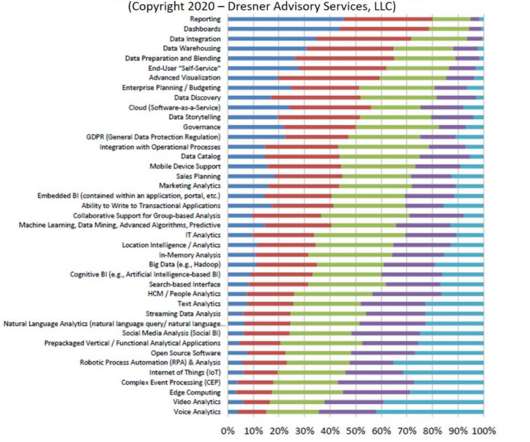
Among all the hot analytics initiatives to choose from (big data, IoT, NLP, data storytelling, cognitive BI, GDPR), plain old reporting is what is considered the most important strategic initiative. That has to be the most boring term in all of analytics. It makes me wonder: Is reporting is the dark matter of analytics?
Analytics remained one of the key focus areas this year, with significant updates and innovations aimed at helping businesses harness their data more efficiently and accelerate insights. This zero-ETL integration reduces the complexity and operational burden of data replication to let you focus on deriving insights from your data.
Talend is a dataintegration and management software company that offers applications for cloud computing, big dataintegration, application integration, data quality and master data management.
Use cases for Hive metastore federation for Amazon EMR Hive metastore federation for Amazon EMR is applicable to the following use cases: Governance of Amazon EMR-based datalakes – Producers generate data within their AWS accounts using an Amazon EMR-based datalake supported by EMRFS on Amazon Simple Storage Service (Amazon S3)and HBase.
Join the AWS Analytics team at AWS re:Invent this year, where new ideas and exciting innovations come together. For those in the data world, this post provides a curated guide for all analytics sessions that you can use to quickly schedule and build your itinerary. A shapeshifting guardian and protector of data like Data Lynx?
This cloud service was a significant leap from the traditional data warehousing solutions, which were expensive, not elastic, and required significant expertise to tune and operate. Amazon Redshift Serverless, generally available since 2021, allows you to run and scale analytics without having to provision and manage the data warehouse.
Now you can author data preparation transformations and edit them with the AWS Glue Studio visual editor. The AWS Glue Studio visual editor is a graphical interface that enables you to create, run, and monitor dataintegration jobs in AWS Glue. In this scenario, you’re a data analyst in this company.
As technology and business leaders, your strategic initiatives, from AI-powered decision-making to predictive insights and personalized experiences, are all fueled by data. Yet, despite growing investments in advanced analytics and AI, organizations continue to grapple with a persistent and often underestimated challenge: poor data quality.
Amazon Redshift is a fully managed data warehousing service that offers both provisioned and serverless options, making it more efficient to run and scale analytics without having to manage your data warehouse. These upstream data sources constitute the data producer components.
Reading Time: 3 minutes First we had data warehouses, then came datalakes, and now the new kid on the block is the data lakehouse. But what is a data lakehouse and why should we develop one? In a way, the name describes what.
With the rapid growth of technology, more and more data volume is coming in many different formats—structured, semi-structured, and unstructured. Dataanalytics on operational data at near-real time is becoming a common need. a new version of AWS Glue that accelerates dataintegration workloads in AWS.
How do you introduce AI into your data and analytics infrastructure? To companies entrenched in decades-old business and IT processes, data fiefdoms, and legacy systems, the task may seem insurmountable. Which type(s) of storage consolidation you use depends on the data you generate and collect. . Outcomes you can expect.
In the era of big data, datalakes have emerged as a cornerstone for storing vast amounts of raw data in its native format. They support structured, semi-structured, and unstructured data, offering a flexible and scalable environment for data ingestion from multiple sources.
As organizations increasingly rely on data stored across various platforms, such as Snowflake , Amazon Simple Storage Service (Amazon S3), and various software as a service (SaaS) applications, the challenge of bringing these disparate data sources together has never been more pressing. For Workgroup , choose blog-workgroup.
As the volume and complexity of analytics workloads continue to grow, customers are looking for more efficient and cost-effective ways to ingest and analyse data. OpenSearch Service is used for multiple purposes, such as observability, search analytics, consolidation, cost savings, compliance, and integration.
Dataintegration is the foundation of robust dataanalytics. It encompasses the discovery, preparation, and composition of data from diverse sources. In the modern data landscape, accessing, integrating, and transforming data from diverse sources is a vital process for data-driven decision-making.
Reading Time: 6 minutes Datalake, by combining the flexibility of object storage with the scalability and agility of cloud platforms, are becoming an increasingly popular choice as an enterprise data repository. Whether you are on Amazon Web Services (AWS) and leverage AWS S3.
Reading Time: 6 minutes Datalake, by combining the flexibility of object storage with the scalability and agility of cloud platforms, are becoming an increasingly popular choice as an enterprise data repository. Whether you are on Amazon Web Services (AWS) and leverage AWS S3.
In attempts to overcome their big data challenges, organizations are exploring datalakes as repositories where huge volumes and varieties of. The post Is Data Virtualization the Secret Behind Operationalizing DataLakes?
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content