This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Q dataintegration , introduced in January 2024, allows you to use natural language to author extract, transform, load (ETL) jobs and operations in AWS Glue specific data abstraction DynamicFrame. In this post, we discuss how Amazon Q dataintegration transforms ETL workflow development.
Testing and Data Observability. Process Analytics. We have also included vendors for the specific use cases of ModelOps, MLOps, DataGovOps and DataSecOps which apply DataOps principles to machine learning, AI, data governance, and data security operations. . Reflow — A system for incremental data processing in the cloud.
Uncomfortable truth incoming: Most people in your organization don’t think about the quality of their data from intake to production of insights. However, as a data team member, you know how important dataintegrity (and a whole host of other aspects of data management) is. What is dataintegrity?
In a recent survey , we explored how companies were adjusting to the growing importance of machine learning and analytics, while also preparing for the explosion in the number of data sources. Data Platforms. DataIntegration and Data Pipelines. Data preparation, data governance, and data lineage.
Organizations can now streamline digital transformations with Logi Symphony on Google Cloud, utilizing BigQuery, the Vertex AI platform and Gemini models for cutting-edge analytics RALEIGH, N.C. – “insightsoftware can continue to securely scale and support customers on their digital transformation journeys.”
Customers often want to augment and enrich SAP source data with other non-SAP source data. Such analytic use cases can be enabled by building a data warehouse or data lake. Customers can now use the AWS Glue SAP OData connector to extract data from SAP. For more information see AWS Glue.
Let’s briefly describe the capabilities of the AWS services we referred above: AWS Glue is a fully managed, serverless, and scalable extract, transform, and load (ETL) service that simplifies the process of discovering, preparing, and loading data for analytics. This data platform is managed by Amazon Data Zone.
For container terminal operators, data-driven decision-making and efficient data sharing are vital to optimizing operations and boosting supply chain efficiency. Enhance agility by localizing changes within business domains and clear data contracts. Eliminate centralized bottlenecks and complex data pipelines.
As organizations increasingly rely on data stored across various platforms, such as Snowflake , Amazon Simple Storage Service (Amazon S3), and various software as a service (SaaS) applications, the challenge of bringing these disparate data sources together has never been more pressing.
Many AWS customers have integrated their data across multiple data sources using AWS Glue , a serverless dataintegration service, in order to make data-driven business decisions. Are there recommended approaches to provisioning components for dataintegration?
Third, some services require you to set up and manage compute resources used for federated connectivity, and capabilities like connection testing and data preview arent available in all services. To solve for these challenges, we launched Amazon SageMaker Lakehouse unified data connectivity. For Add data source , choose Add connection.
Amazon MSK serves as a highly scalable, and fully managed service for Apache Kafka, allowing for seamless collection and processing of vast streams of data. Integrating streaming data into Amazon Redshift brings immense value by enabling organizations to harness the potential of real-time analytics and data-driven decision-making.
It covers the essential steps for taking snapshots of your data, implementing safe transfer across different AWS Regions and accounts, and restoring them in a new domain. This guide is designed to help you maintain dataintegrity and continuity while navigating complex multi-Region and multi-account environments in OpenSearch Service.
Modern business applications rely on timely and accurate data with increasing demand for real-time analytics. There is a growing need for efficient and scalable data storage solutions. GoldenGate provides special tools called S3 event handlers to integrate with Amazon S3 for data replication.
For sectors such as industrial manufacturing and energy distribution, metering, and storage, embracing artificial intelligence (AI) and generative AI (GenAI) along with real-time dataanalytics, instrumentation, automation, and other advanced technologies is the key to meeting the demands of an evolving marketplace, but it’s not without risks.
OpenSearch is a distributed search and analytics engine, which is an open-source project. OpenSearch Service seamlessly integrates with other AWS offerings, providing a robust solution for building scalable and resilient search and analytics applications in the cloud.
However, embedding ESG into an enterprise data strategy doesnt have to start as a C-suite directive. Developers, data architects and data engineers can initiate change at the grassroots level from integrating sustainability metrics into data models to ensuring ESG dataintegrity and fostering collaboration with sustainability teams.
And the chatbot would be able to understand what you were asking, run analytics on your purchases, and give you a total. As with all financial services technologies, protecting customer data is extremely important. Dataintegration can also be challenging and should be planned for early in the project. . IT Leadership
SAP announced today a host of new AI copilot and AI governance features for SAP Datasphere and SAP Analytics Cloud (SAC). The combination enables SAP to offer a single data management system and advanced analytics for cross-organizational planning. Ventana Research’s Menninger agrees. “At
Data also needs to be sorted, annotated and labelled in order to meet the requirements of generative AI. No wonder CIO’s 2023 AI Priorities study found that dataintegration was the number one concern for IT leaders around generative AI integration, above security and privacy and the user experience.
In today’s data-driven world, seamless integration and transformation of data across diverse sources into actionable insights is paramount. With AWS Glue, you can discover and connect to hundreds of diverse data sources and manage your data in a centralized data catalog. Choose Store a new secret.
Today, customers widely use OpenSearch Service for operational analytics because of its ability to ingest high volumes of data while also providing rich and interactive analytics. As your operational analyticsdata velocity and volume of data grows, bottlenecks may emerge.
Today, in order to accelerate and scale dataanalytics, companies are looking for an approach to minimize infrastructure management and predict computing needs for different types of workloads, including spikes and ad hoc analytics. For Host , enter the Redshift Serverless endpoint’s host URL. This is optional.
In legacy analytical systems such as enterprise data warehouses, the scalability challenges of a system were primarily associated with computational scalability, i.e., the ability of a data platform to handle larger volumes of data in an agile and cost-efficient way. Introduction. CRM platforms).
One key component that plays a central role in modern data architectures is the data lake, which allows organizations to store and analyze large amounts of data in a cost-effective manner and run advanced analytics and machine learning (ML) at scale. To overcome these issues, Orca decided to build a data lake.
The emergence of massive data centers with exabytes in the form of transaction records, browsing habits, financial information, and social media activities are hiring software developers to write programs that can help facilitate the analytics process. Software development has made great strides in terms of saving thanks to Big Data.
Data ingestion must be done properly from the start, as mishandling it can lead to a host of new issues. The groundwork of training data in an AI model is comparable to piloting an airplane. This may also entail working with new data through methods like web scraping or uploading.
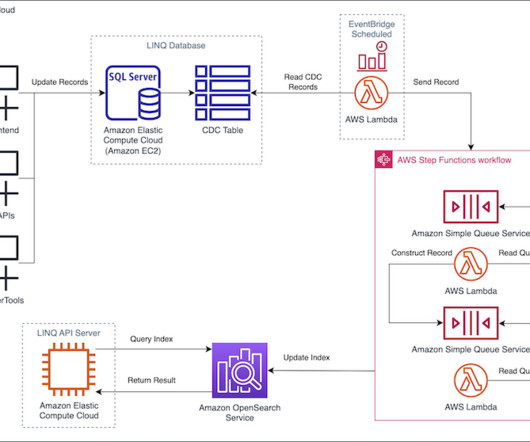
Initially, searches from Hub queried LINQ’s Microsoft SQL Server database hosted on Amazon Elastic Compute Cloud (Amazon EC2), with search times averaging 3 seconds, leading to reduced adoption and negative feedback. The LINQ team exposes access to the OpenSearch Service index through a search API hosted on Amazon EC2.
Customers have been using data warehousing solutions to perform their traditional analytics tasks. A host with the installed MySQL utility, such as an Amazon Elastic Compute Cloud (Amazon EC2) instance, AWS Cloud9 , your laptop, and so on. Create a Python file called generate-data-for-kds.py : $ python3 generate-data-for-kds.py
Data monetization strategy: Managing data as a product Every organization has the potential to monetize their data; for many organizations, it is an untapped resource for new capabilities. But few organizations have made the strategic shift to managing “data as a product.”
You can slice data by different dimensions like job name, see anomalies, and share reports securely across your organization. With these insights, teams have the visibility to make dataintegration pipelines more efficient. Typically, you have multiple accounts to manage and run resources for your data pipeline.
The reporting capabilities enable users to drill down into individual numbers for greater insight using the Analytics 360 platform. They’ve also integrated the tool with Studio, their portal for creating new advertising campaigns. It integratesdata across a wide arrange of sources to help optimize the value of ad dollar spending.
Without real-time insight into their data, businesses remain reactive, miss strategic growth opportunities, lose their competitive edge, fail to take advantage of cost savings options, don’t ensure customer satisfaction… the list goes on. Clean the data. Clean data in, clean analytics out. Ensure data literacy.
This podcast centers around data management and investigates a different aspect of this field each week. Within each episode, there are actionable insights that data teams can apply in their everyday tasks or projects. The host is Tobias Macey, an engineer with many years of experience. Agile Data.
Traditionally, customers used batch-based approaches for data movement from operational systems to analytical systems. A batch-based approach can introduce latency in data movement and reduce the value of data for analytics. usually a data warehouse) needs to reflect those changes in near real-time.
The producer account will host the EMR cluster and S3 buckets. The catalog account will host Lake Formation and AWS Glue. The consumer account will host EMR Serverless, Athena, and SageMaker notebooks. Prerequisites You need three AWS accounts with admin access to implement this solution. It is recommended to use test accounts.
No application changes are required to maintain business continuity because the Multi-AZ deployment is managed as a single data warehouse with one endpoint. Choose your hosted zone. Use the CNAME record name from the Route 53 hosted zone setup to create a custom domain in the newly created Redshift cluster or workgroup.
Consumer data: Data transmitted by customers including, banking records, banking data, stock market transactions, employee benefits, insurance claims, etc. Operations data: Data generated from a set of operations such as orders, online transactions, competitor analytics, sales data, point of sales data, pricing data, etc.
Verschuren also notes that compliance officers and chief information security officers are increasingly mindful of dataintegrity and demand the strongest levels of protection. Simultaneously, the pandemic accelerated digitization and contributed to the growing demand for innovation, analytics, and the capabilities the cloud delivers.
You can store your data as-is, without having to first structure the data and then run different types of analytics for better business insights. Analytics use cases on data lakes are always evolving. Launch the notebooks hosted under this link and unzip them on a local workstation. Open AWS Glue Studio.
Unified, governed data can also be put to use for various analytical, operational and decision-making purposes. This process is known as dataintegration, one of the key components to a strong data fabric. There are several styles of dataintegration.
On Thursday January 6th I hosted Gartner’s 2022 Leadership Vision for Data and Analytics webinar. – In the webinar and Leadership Vision deck for Data and Analytics we called out AI engineering as a big trend. – This is a question for our data security team.
Reading Time: 5 minutes Opening the specific data view within Power BI is as simple as clicking on and opening the downloaded connection file. All the server host, ports, and database connection settings are automatically made for you so you can get on with.
To be clear, data quality is one of several types of data governance as defined by Gartner and the Data Governance Institute. Quality policies for data and analytics set expectations about the “fitness for purpose” of artifacts across various dimensions. Step 4: Data Sources. Step 3: Business Impacts.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content