This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. Introduction A datalake is a centralized repository for storing, processing, and securing massive amounts of structured, semi-structured, and unstructured data. It can store data in its native format and process any type of data, regardless of size.
Introduction Today, DataLake is most commonly used to describe an ecosystem of IT tools and processes (infrastructure as a service, software as a service, etc.) that work together to make processing and storing large volumes of data easy. An ecosystem consists of […].
Introduction You can access your Azure DataLake Storage Gen1 directly with the RapidMiner Studio. This is the feature offered by the Azure DataLake Storage connector. The post Connecting and Reading Data From Azure DataLake appeared first on Analytics Vidhya.
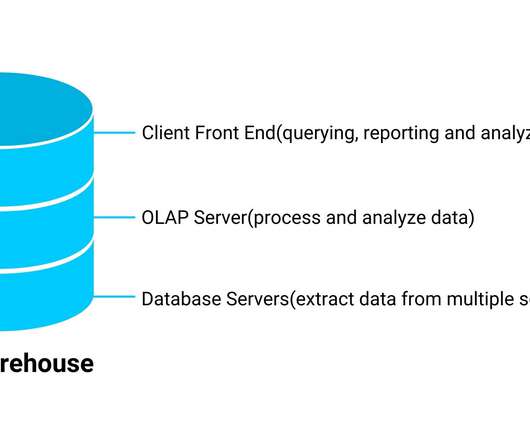
This article will discuss some of the features and applications of data warehouses, data marts, and data […]. The post Data Warehouses, Data Marts and DataLakes appeared first on Analytics Vidhya.
Increasingly, enterprises are leveraging cloud datalakes as the platform used to store data for analytics, combined with various compute engines for processing that data. Read this paper to learn about: The value of cloud datalakes as the new system of record.
Data collection is critical for businesses to make informed decisions, understand customers’ […]. The post DataLake or Data Warehouse- Which is Better? appeared first on Analytics Vidhya. We can use it to represent facts, figures, and other information that we can use to make decisions.
Azure DataLake Storage is capable of storing large quantities of structured, semi-structured, and unstructured data in […]. The post Introduction to Azure DataLake Storage Gen2 appeared first on Analytics Vidhya. It combines the capabilities of ADLS Gen1 with Azure Blob Storage.
Overview Understand the meaning of datalake and data warehouse We will see what are the key differences between Data Warehouse and DataLake. The post What are the differences between DataLake and Data Warehouse? appeared first on Analytics Vidhya.
In this analyst perspective, Dave Menninger takes a look at datalakes. He explains the term “datalake,” describes common use cases and shares his views on some of the latest market trends. He explores the relationship between data warehouses and datalakes and share some of Ventana Research’s findings on the subject.
Speaker: Anthony Roach, Director of Product Management at Tableau Software, and Jeremiah Morrow, Partner Solution Marketing Director at Dremio
As a result, these two solutions come together to deliver: Lightning-fast BI and interactive analytics directly on data wherever it is stored. A self-service platform for data exploration and visualization that broadens access to analytic insights. A seamless and efficient customer experience.
This is part two of a three-part series where we show how to build a datalake on AWS using a modern data architecture. This post shows how to load data from a legacy database (SQL Server) into a transactional datalake ( Apache Iceberg ) using AWS Glue. Delete the bucket.
ArticleVideo Book This article was published as a part of the Data Science Blogathon. Introduction DataLake architecture for different use cases – Elegant. The post A Guide to Build your DataLake in AWS appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction A datalake is a central data repository that allows us to store all of our structured and unstructured data on a large scale. The post A Detailed Introduction on DataLakes and Delta Lakes appeared first on Analytics Vidhya.
Now, businesses are looking for different types of data storage to store and manage their data effectively. Organizations can collect millions of data, but if they’re lacking in storing that data, those efforts […] The post A Comprehensive Guide to DataLake vs. Data Warehouse appeared first on Analytics Vidhya.
Before seeing the practical implementation of the use case, let’s briefly introduce Azure DataLake Storage Gen2 and the Paramiko module. Introduction to Azure DataLake Storage Gen2 Azure DataLake Storage Gen2 is a data storage solution specially designed for big data […].
Amazon Redshift is a fast, fully managed cloud data warehouse that makes it cost-effective to analyze your data using standard SQL and business intelligence tools. Customers use datalake tables to achieve cost effective storage and interoperability with other tools.
Introduction We are all pretty much familiar with the common modern cloud data warehouse model, which essentially provides a platform comprising a datalake (based on a cloud storage account such as Azure DataLake Storage Gen2) AND a data warehouse compute engine […].
In this article, we will explore the evolution of Iceberg, its key features like ACID transactions, partition evolution, and time travel, and how it integrates with modern datalakes. appeared first on Analytics Vidhya. Well also dive into […] The post How to Use Apache Iceberg Tables?
Businesses today compete on their ability to turn big data into essential business insights. To do so, modern enterprises leverage cloud datalakes as the platform used to store data for analytical purposes, combined with various compute engines for processing that data.
At AWS, we are committed to empowering organizations with tools that streamline dataanalytics and transformation processes. This integration enables data teams to efficiently transform and manage data using Athena with dbt Cloud’s robust features, enhancing the overall data workflow experience.
Components of Data Engineering Object Storage Object Storage MinIO Install Object Storage MinIO DataLake with Buckets Demo DataLake Management Conclusion References What is Data Engineering? The post How to Implement Data Engineering in Practice? appeared first on Analytics Vidhya.
Data warehousing, business intelligence, dataanalytics, and AI services are all coming together under one roof at Amazon Web Services. It combines SQL analytics, data processing, AI development, data streaming, business intelligence, and search analytics.
Introduction A datalake is a centralized and scalable repository storing structured and unstructured data. The need for a datalake arises from the growing volume, variety, and velocity of data companies need to manage and analyze.
Speaker: Javier Ramírez, Senior AWS Developer Advocate, AWS
Will the datalake scale when you have twice as much data? Is your data secure? In this session, we address common pitfalls of building datalakes and show how AWS can help you manage data and analytics more efficiently. Javier Ramirez will present: The typical steps for building a datalake.
At AWS re:Invent 2024, we announced the next generation of Amazon SageMaker , the center for all your data, analytics, and AI. It enables teams to securely find, prepare, and collaborate on data assets and build analytics and AI applications through a single experience, accelerating the path from data to value.
Introduction Delta Lake is an open-source storage layer that brings datalakes to the world of Apache Spark. Delta Lakes provides an ACID transaction–compliant and cloud–native platform on top of cloud object stores such as Amazon S3, Microsoft Azure Storage, and Google Cloud Storage.
This week on the keynote stages at AWS re:Invent 2024, you heard from Matt Garman, CEO, AWS, and Swami Sivasubramanian, VP of AI and Data, AWS, speak about the next generation of Amazon SageMaker , the center for all of your data, analytics, and AI. The relationship between analytics and AI is rapidly evolving.
Many organizations operate datalakes spanning multiple cloud data stores. In these cases, you may want an integrated query layer to seamlessly run analytical queries across these diverse cloud stores and streamline your dataanalytics processes. This serves as the S3 datalakedata for this post.
Our research shows that external data sources are also a routine part of data preparation processes, with 80% of organizations incorporating one or more external data sources. And a similar proportion of participants in our research (84%) include external data in their datalakes.
Introduction Most of you would know the different approaches for building a data and analytics platform. You would have already worked on systems that used traditional warehouses or Hadoop-based datalakes. The post Warehouse, Lake or a Lakehouse – What’s Right for you? Selecting one among […].
With this integration, you can now seamlessly query your governed datalake assets in Amazon DataZone using popular business intelligence (BI) and analytics tools, including partner solutions like Tableau. Choose Connect with JDBC. In the JDBC parameters dialog box, select Using IDC auth and copy the JDBC URL.
Rapidminer is a visual enterprise data science platform that includes data extraction, data mining, deep learning, artificial intelligence and machine learning (AI/ML) and predictive analytics. It can support AI/ML processes with data preparation, model validation, results visualization and model optimization.
Enterprises have slowly started adopting Lakehouses for their data ecosystems as they offer cost efficiencies of datalakes and the performance of warehouses. […]. The post Delta Lake in Action – Quick Hands-on Tutorial for Beginners appeared first on Analytics Vidhya.
A Drug Launch Case Study in the Amazing Efficiency of a Data Team Using DataOps How a Small Team Powered the Multi-Billion Dollar Acquisition of a Pharma Startup When launching a groundbreaking pharmaceutical product, the stakes and the rewards couldnt be higher. It is necessary to have more than a datalake and a database.
While this blog post helps you to get started using Amazon Redshift with Amazon S3 Tables, there are additional steps you need to consider when working with your data in production environments, including who has access to your data and with what level of permissions. This is an option in the Amazon S3 console.
Amazon Redshift has established itself as a highly scalable, fully managed cloud data warehouse trusted by tens of thousands of customers for its superior price-performance and advanced dataanalytics capabilities. This allows you to maintain a comprehensive view of your data while optimizing for cost-efficiency.
A datalake is a centralized repository that you can use to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data and then run different types of analytics for better business insights.
Amazon Redshift , launched in 2013, has undergone significant evolution since its inception, allowing customers to expand the horizons of data warehousing and SQL analytics. This allowed customers to scale read analytics workloads and offered isolation to help maintain SLAs for business-critical applications.
In this blog post, we dive into different data aspects and how Cloudinary breaks the two concerns of vendor locking and cost efficient dataanalytics by using Apache Iceberg, Amazon Simple Storage Service (Amazon S3 ), Amazon Athena , Amazon EMR , and AWS Glue.
Delta Lake allows businesses to access and break new data down in real time. Delta Lake is an open-source warehouse layer designed to run on top of datalakes analogous to […] The post A Comprehensive Guide on Delta Lake appeared first on Analytics Vidhya.
Their business unit colleagues ask an endless stream of urgent questions that require analytic insights. Business analysts must rapidly deliver value and simultaneously manage fragile and error-prone analytics production pipelines. In business analytics, fire-fighting and stress are common. Analytics Hub and Spoke.
Organizations are dealing with exponentially increasing data that ranges broadly from customer-generated information, financial transactions, edge-generated data and even operational IT server logs. A combination of complex datalake and data warehouse capabilities are required to leverage this data.
Apache Iceberg is an open table format for very large analytic datasets, which captures metadata information on the state of datasets as they evolve and change over time. Iceberg has become very popular for its support for ACID transactions in datalakes and features like schema and partition evolution, time travel, and rollback.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content