This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A Drug Launch Case Study in the Amazing Efficiency of a Data Team Using DataOps How a Small Team Powered the Multi-Billion Dollar Acquisition of a Pharma Startup When launching a groundbreaking pharmaceutical product, the stakes and the rewards couldnt be higher. data engineers delivered over 100 lines of code and 1.5
This week on the keynote stages at AWS re:Invent 2024, you heard from Matt Garman, CEO, AWS, and Swami Sivasubramanian, VP of AI and Data, AWS, speak about the next generation of Amazon SageMaker , the center for all of your data, analytics, and AI. The relationship between analytics and AI is rapidly evolving.
At AWS, we are committed to empowering organizations with tools that streamline dataanalytics and transformation processes. This integration enables data teams to efficiently transform and manage data using Athena with dbt Cloud’s robust features, enhancing the overall data workflow experience.
Today, customers are embarking on data modernization programs by migrating on-premises data warehouses and datalakes to the AWS Cloud to take advantage of the scale and advanced analytical capabilities of the cloud. Some customers build custom in-house data parity frameworks to validate data during migration.
As technology and business leaders, your strategic initiatives, from AI-powered decision-making to predictive insights and personalized experiences, are all fueled by data. Yet, despite growing investments in advanced analytics and AI, organizations continue to grapple with a persistent and often underestimated challenge: poor dataquality.
Unlocking the true value of data often gets impeded by siloed information. Traditional data management—wherein each business unit ingests raw data in separate datalakes or warehouses—hinders visibility and cross-functional analysis. Amazon DataZone natively supports data sharing for Amazon Redshift data assets.
Datalakes are centralized repositories that can store all structured and unstructured data at any desired scale. The power of the datalake lies in the fact that it often is a cost-effective way to store data. The power of the datalake lies in the fact that it often is a cost-effective way to store data.
They establish dataquality rules to ensure the extracted data is of high quality for accurate business decisions. These rules assess the data based on fixed criteria reflecting current business states. We are excited to talk about how to use dynamic rules , a new capability of AWS Glue DataQuality.
When encouraging these BI best practices what we are really doing is advocating for agile business intelligence and analytics. In our opinion, both terms, agile BI and agile analytics, are interchangeable and mean the same. What Is Agile Analytics And BI? Agile Business Intelligence & Analytics Methodology.
With data becoming the driving force behind many industries today, having a modern data architecture is pivotal for organizations to be successful. In this post, we describe Orca’s journey building a transactional datalake using Amazon Simple Storage Service (Amazon S3), Apache Iceberg, and AWS Analytics.
With this new functionality, customers can create up-to-date replicas of their data from applications such as Salesforce, ServiceNow, and Zendesk in an Amazon SageMaker Lakehouse and Amazon Redshift. SageMaker Lakehouse gives you the flexibility to access and query your data in-place with all Apache Iceberg compatible tools and engines.
Data governance is the process of ensuring the integrity, availability, usability, and security of an organization’s data. Due to the volume, velocity, and variety of data being ingested in datalakes, it can get challenging to develop and maintain policies and procedures to ensure data governance at scale for your datalake.
In recent years, datalakes have become a mainstream architecture, and dataquality validation is a critical factor to improve the reusability and consistency of the data. In this post, we provide benchmark results of running increasingly complex dataquality rulesets over a predefined test dataset.
AWS Glue DataQuality allows you to measure and monitor the quality of data in your data repositories. It’s important for business users to be able to see quality scores and metrics to make confident business decisions and debug dataquality issues. An AWS Glue crawler crawls the results.
We are excited to announce the General Availability of AWS Glue DataQuality. Our journey started by working backward from our customers who create, manage, and operate datalakes and data warehouses for analytics and machine learning.
Analytics are prone to frequent data errors and deployment of analytics is slow and laborious. The strategic value of analytics is widely recognized, but the turnaround time of analytics teams typically can’t support the decision-making needs of executives coping with fast-paced market conditions.
For container terminal operators, data-driven decision-making and efficient data sharing are vital to optimizing operations and boosting supply chain efficiency. Enhance agility by localizing changes within business domains and clear data contracts. Eliminate centralized bottlenecks and complex data pipelines.
Poor-qualitydata can lead to incorrect insights, bad decisions, and lost opportunities. AWS Glue DataQuality measures and monitors the quality of your dataset. It supports both dataquality at rest and dataquality in AWS Glue extract, transform, and load (ETL) pipelines.
AWS Glue is a serverless data integration service that makes it simple to discover, prepare, and combine data for analytics, machine learning (ML), and application development. Hundreds of thousands of customers use datalakes for analytics and ML to make data-driven business decisions.
First-generation – expensive, proprietary enterprise data warehouse and business intelligence platforms maintained by a specialized team drowning in technical debt. Second-generation – gigantic, complex datalake maintained by a specialized team drowning in technical debt. See the pattern?
Talend is a data integration and management software company that offers applications for cloud computing, big data integration, application integration, dataquality and master data management.
To address the flood of data and the needs of enterprise businesses to store, sort, and analyze that data, a new storage solution has evolved: the datalake. What’s in a DataLake? Data warehouses do a great job of standardizing data from disparate sources for analysis. Taking a Dip.
Domain ownership recognizes that the teams generating the data have the deepest understanding of it and are therefore best suited to manage, govern, and share it effectively. This principle makes sure data accountability remains close to the source, fostering higher dataquality and relevance.
Applying artificial intelligence (AI) to dataanalytics for deeper, better insights and automation is a growing enterprise IT priority. But the data repository options that have been around for a while tend to fall short in their ability to serve as the foundation for big dataanalytics powered by AI.
In modern data architectures, Apache Iceberg has emerged as a popular table format for datalakes, offering key features including ACID transactions and concurrent write support. About the Authors Sotaro Hikita is an Analytics Solutions Architect.
Amazon SageMaker Unified Studio (preview) provides a unified experience for using data, analytics, and AI capabilities. You can use familiar AWS services for model development, generative AI, data processing, and analyticsall within a single, governed environment.
In the era of big data, datalakes have emerged as a cornerstone for storing vast amounts of raw data in its native format. They support structured, semi-structured, and unstructured data, offering a flexible and scalable environment for data ingestion from multiple sources.
On the agribusiness side we source, purchase, and process agricultural commodities and offer a diverse portfolio of products including grains, soybean meal, blended feed ingredients, and top-quality oils for the food industry to add value to the commodities our customers desire. The data can also help us enrich our commodity products.
How do you introduce AI into your data and analytics infrastructure? To companies entrenched in decades-old business and IT processes, data fiefdoms, and legacy systems, the task may seem insurmountable. Which type(s) of storage consolidation you use depends on the data you generate and collect. . Outcomes you can expect.
Some of the accelerators included as part of the new platform are integrations with Salesforce, NPI data, National Patient Account Services, Workday, Oracle Fusion HCM Cloud, Orange HRM, Salesforce Health Cloud, MedPro, healthcare-focused cloud company Veeva, and HR vendor UltiPro. Analytics for faster decision making.
These formats, exemplified by Apache Iceberg, Apache Hudi, and Delta Lake, addresses persistent challenges in traditional datalake structures by offering an advanced combination of flexibility, performance, and governance capabilities. About the Authors Sotaro Hikita is an Analytics Solutions Architect.
Poor dataquality is one of the top barriers faced by organizations aspiring to be more data-driven. Ill-timed business decisions and misinformed business processes, missed revenue opportunities, failed business initiatives and complex data systems can all stem from dataquality issues.
In particular, companies that were leaders at using data and analytics had three times higher improvement in revenues, were nearly three times more likely to report shorter times to market for new products and services, and were over twice as likely to report improvement in customer satisfaction, profits, and operational efficiency.
This post provides guidance on how to build scalable analytical solutions for gaming industry use cases using Amazon Redshift Serverless. Flexible and easy to use – The solutions should provide less restrictive, easy-to-access, and ready-to-use data. Data hubs and datalakes can coexist in an organization, complementing each other.
The following are the key components of the Bluestone Data Platform: Data mesh architecture – Bluestone adopted a data mesh architecture, a paradigm that distributes data ownership across different business units. This enables data-driven decision-making across the organization.
The application gets prompt templates from an S3 datalake and creates the engineered prompt. The user interaction is stored in a datalake for downstream usage and BI analysis. EMEA Data & AI PSA, based in Madrid. In his current role, Angel helps partners develop businesses centered on Data and AI.
As the volume and complexity of analytics workloads continue to grow, customers are looking for more efficient and cost-effective ways to ingest and analyse data. OpenSearch Service is used for multiple purposes, such as observability, search analytics, consolidation, cost savings, compliance, and integration.
To provide a response that includes the enterprise context, each user prompt needs to be augmented with a combination of insights from structured data from the data warehouse and unstructured data from the enterprise datalake. Implement data privacy policies. Implement dataquality by data type and source.
For the past 5 years, BMS has used a custom framework called Enterprise DataLake Services (EDLS) to create ETL jobs for business users. Dataquality check – The dataquality module enables you to perform quality checks on a huge amount of data and generate reports that describe and validate the dataquality.
AWS Lake Formation and the AWS Glue Data Catalog form an integral part of a data governance solution for datalakes built on Amazon Simple Storage Service (Amazon S3) with multiple AWS analytics services integrating with them. Other AWS analytics services also support the user identity to be propagated.
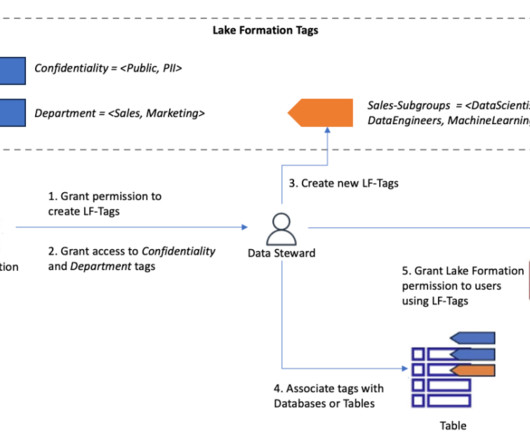
One of the core features of AWS Lake Formation is the delegation of permissions on a subset of resources such as databases, tables, and columns in AWS Glue Data Catalog to data stewards, empowering them make decisions regarding who should get access to their resources and helping you decentralize the permissions management of your datalakes.
As they continue to implement their Digital First strategy for speed, scale and the elimination of complexity, they are always seeking ways to innovate, modernize and also streamline data access control in the Cloud. BMO has accumulated sensitive financial data and needed to build an analytic environment that was secure and performant.
It’s stored in corporate data warehouses, datalakes, and a myriad of other locations – and while some of it is put to good use, it’s estimated that around 73% of this data remains unexplored. So how can organizations find data in their own universes? Improving dataquality. Data augmentation.
As organizations process vast amounts of data, maintaining an accurate historical record is crucial. History management in data systems is fundamental for compliance, business intelligence, dataquality, and time-based analysis. Hes passionate about helping customers use Apache Iceberg for their datalakes on AWS.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content