
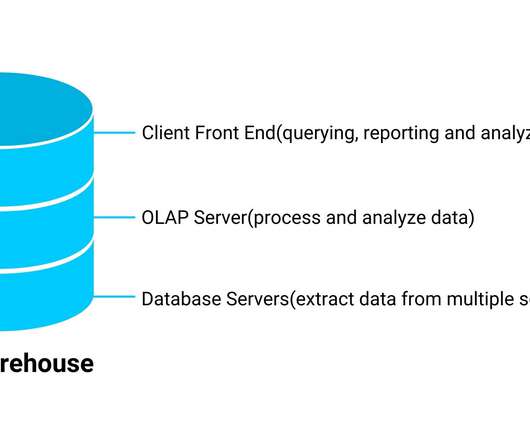
Data Warehouses, Data Marts and Data Lakes
Analytics Vidhya
JANUARY 7, 2022
By their definition, the types of data it stores and how it can be accessible to users differ. This article will discuss some of the features and applications of data warehouses, data marts, and data […]. The post Data Warehouses, Data Marts and Data Lakes appeared first on Analytics Vidhya.



















































Let's personalize your content