This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This week on the keynote stages at AWS re:Invent 2024, you heard from Matt Garman, CEO, AWS, and Swami Sivasubramanian, VP of AI and Data, AWS, speak about the next generation of Amazon SageMaker , the center for all of your data, analytics, and AI. The relationship between analytics and AI is rapidly evolving.
1) What Is DataQuality Management? 4) DataQuality Best Practices. 5) How Do You Measure DataQuality? 6) DataQuality Metrics Examples. 7) DataQuality Control: Use Case. 8) The Consequences Of Bad DataQuality. 9) 3 Sources Of Low-QualityData.
Talend is a data integration and management software company that offers applications for cloud computing, big data integration, application integration, dataquality and master data management.
In fact, by putting a single label like AI on all the steps of a data-driven business process, we have effectively not only blurred the process, but we have also blurred the particular characteristics that make each step separately distinct, uniquely critical, and ultimately dependent on specialized, specific technologies at each step.
One of our key datawarehouse refreshes had failed. No new data. The refresh was long past its deadline, the projects key data engineer was on vacation, and I was playing backup. At the moment, I was flying home from a dataquality conference. The value of dataquality is often invisible.
As technology and business leaders, your strategic initiatives, from AI-powered decision-making to predictive insights and personalized experiences, are all fueled by data. Yet, despite growing investments in advanced analytics and AI, organizations continue to grapple with a persistent and often underestimated challenge: poor dataquality.
Today, customers are embarking on data modernization programs by migrating on-premises datawarehouses and data lakes to the AWS Cloud to take advantage of the scale and advanced analytical capabilities of the cloud. Some customers build custom in-house data parity frameworks to validate data during migration.
At AWS, we are committed to empowering organizations with tools that streamline dataanalytics and transformation processes. This integration enables data teams to efficiently transform and manage data using Athena with dbt Cloud’s robust features, enhancing the overall data workflow experience.
Unifying these necessitates additional data processing, requiring each business unit to provision and maintain a separate datawarehouse. This burdens business units focused solely on consuming the curated data for analysis and not concerned with data management tasks, cleansing, or comprehensive data processing.
Organizations face various challenges with analytics and business intelligence processes, including data curation and modeling across disparate sources and datawarehouses, maintaining dataquality and ensuring security and governance.
Dataquality is crucial in data pipelines because it directly impacts the validity of the business insights derived from the data. Today, many organizations use AWS Glue DataQuality to define and enforce dataquality rules on their data at rest and in transit.
Testing and Data Observability. Process Analytics. We have also included vendors for the specific use cases of ModelOps, MLOps, DataGovOps and DataSecOps which apply DataOps principles to machine learning, AI, data governance, and data security operations. . Reflow — A system for incremental data processing in the cloud.
AWS Glue DataQuality allows you to measure and monitor the quality of data in your data repositories. It’s important for business users to be able to see quality scores and metrics to make confident business decisions and debug dataquality issues. An AWS Glue crawler crawls the results.
This approach is repeatable, minimizes dependence on manual controls, harnesses technology and AI for data management and integrates seamlessly into the digital product development process. They must also select the data processing frameworks such as Spark, Beam or SQL-based processing and choose tools for ML.
We are excited to announce the General Availability of AWS Glue DataQuality. Our journey started by working backward from our customers who create, manage, and operate data lakes and datawarehouses for analytics and machine learning.
Whether the reporting is being done by an end user, a data science team, or an AI algorithm, the future of your business depends on your ability to use data to drive better quality for your customers at a lower cost. So, when it comes to collecting, storing, and analyzing data, what is the right choice for your enterprise?
generally available on May 24, Alation introduces the Open DataQuality Initiative for the modern data stack, giving customers the freedom to choose the dataquality vendor that’s best for them with the added confidence that those tools will integrate seamlessly with Alation’s Data Catalog and Data Governance application.
AWS Glue is a serverless data integration service that makes it simple to discover, prepare, and combine data for analytics, machine learning (ML), and application development. Hundreds of thousands of customers use data lakes for analytics and ML to make data-driven business decisions.
The past decades of enterprise data platform architectures can be summarized in 69 words. First-generation – expensive, proprietary enterprise datawarehouse and business intelligence platforms maintained by a specialized team drowning in technical debt. The organizational concepts behind data mesh are summarized as follows.
Based on your company’s strategy, goals, budget, and target customers you should prepare a set of questions that will smoothly walk you through the online data analysis and help you arrive at relevant insights. This genie (who we’ll call Data Dan) embodies the idea of a perfect dataanalytics platform through his magic powers.
DataOps (data operations) is an agile, process-oriented methodology for developing and delivering analytics. It brings together DevOps teams with data engineers and data scientists to provide the tools, processes, and organizational structures to support the data-focused enterprise. What is DataOps?
Domain ownership recognizes that the teams generating the data have the deepest understanding of it and are therefore best suited to manage, govern, and share it effectively. This principle makes sure data accountability remains close to the source, fostering higher dataquality and relevance.
There was a time when most CIOs would never consider putting their crown jewels — AKA customer data and associated analytics — into the cloud. But today, there is a magic quadrant for cloud databases and warehouses comprising more than 20 vendors. The cloud is no longer synonymous with risk. What do you migrate, how, and when?
Poor-qualitydata can lead to incorrect insights, bad decisions, and lost opportunities. AWS Glue DataQuality measures and monitors the quality of your dataset. It supports both dataquality at rest and dataquality in AWS Glue extract, transform, and load (ETL) pipelines.
For container terminal operators, data-driven decision-making and efficient data sharing are vital to optimizing operations and boosting supply chain efficiency. Enhance agility by localizing changes within business domains and clear data contracts. Eliminate centralized bottlenecks and complex data pipelines.
As the volume of available information continues to grow, data management will become an increasingly important factor in effective business management. Lack of proactive data management, on the other hand, can result in incompatible or inconsistent sources of information, as well as dataquality problems.
How do you introduce AI into your data and analytics infrastructure? To companies entrenched in decades-old business and IT processes, data fiefdoms, and legacy systems, the task may seem insurmountable. Another option is a datawarehouse, which stores processed and refined data. Outcomes you can expect.
Topping the list of executive priorities for 2023—a year heralded by escalating economic woes and climate risks—is the need for data driven insights to propel efficiency, resiliency, and other key initiatives. Many companies have been experimenting with advanced analytics and artificial intelligence (AI) to fill this need.
Organizations are increasingly trying to grow revenue by mining their data to quickly show insights and provide value. In the past, one option was to use open-source dataanalytics platforms to analyze data using on-premises infrastructure. Cloudera and Dell Technologies for More Data Insights.
What is a data engineer? Data engineers design, build, and optimize systems for data collection, storage, access, and analytics at scale. They create data pipelines used by data scientists, data-centric applications, and other data consumers. Data engineer job description.
Applying artificial intelligence (AI) to dataanalytics for deeper, better insights and automation is a growing enterprise IT priority. But the data repository options that have been around for a while tend to fall short in their ability to serve as the foundation for big dataanalytics powered by AI.
Business leaders, developers, data heads, and tech enthusiasts – it’s time to make some room on your business intelligence bookshelf because once again, datapine has new books for you to add. We have already given you our top data visualization books , top business intelligence books , and best dataanalytics books.
Large-scale datawarehouse migration to the cloud is a complex and challenging endeavor that many organizations undertake to modernize their data infrastructure, enhance data management capabilities, and unlock new business opportunities. This makes sure the new data platform can meet current and future business goals.
This post provides guidance on how to build scalable analytical solutions for gaming industry use cases using Amazon Redshift Serverless. Flexible and easy to use – The solutions should provide less restrictive, easy-to-access, and ready-to-use data. A datawarehouse is one of the components in a data hub.
Some of the accelerators included as part of the new platform are integrations with Salesforce, NPI data, National Patient Account Services, Workday, Oracle Fusion HCM Cloud, Orange HRM, Salesforce Health Cloud, MedPro, healthcare-focused cloud company Veeva, and HR vendor UltiPro. Analytics for faster decision making.
Poor dataquality is one of the top barriers faced by organizations aspiring to be more data-driven. Ill-timed business decisions and misinformed business processes, missed revenue opportunities, failed business initiatives and complex data systems can all stem from dataquality issues.
Data and big dataanalytics are the lifeblood of any successful business. Getting the technology right can be challenging but building the right team with the right skills to undertake data initiatives can be even harder — a challenge reflected in the rising demand for big data and analytics skills and certifications.
In the contemporary data landscape, data teams commonly utilize datawarehouses or lakes to arrange their data into L1, L2, and L3 layers. These layers help teams delineate different stages of data processing, storage, and access, offering a structured approach to data management. What is Data in Use?
Through a commitment to cutting-edge technologies and a relentless pursuit of quality, HPE Aruba designed this next-generation solution as a cloud-based cross-functional supply chain workflow and analytics tool. In addition, they use AWS Glue jobs for orchestrating validation jobs and moving data through the datawarehouse.
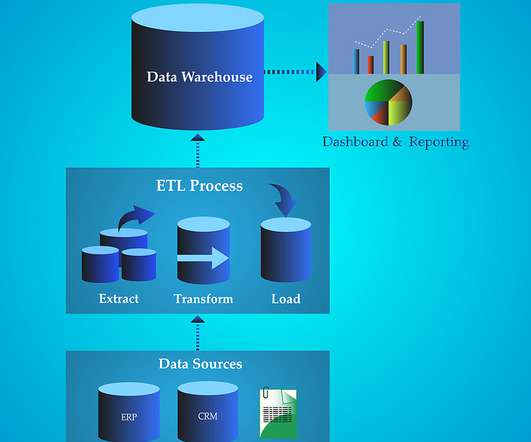
ETL (Extract, Transform, Load) is a crucial process in the world of dataanalytics and business intelligence. By understanding the power of ETL, organisations can harness the potential of their data and gain valuable insights that drive informed choices. Both approaches aim to improve dataquality and enable accurate analysis.
Centralized reporting boosts data value For more than a decade, pediatric health system Phoenix Children’s has operated a datawarehouse containing more than 120 separate data systems, providing the ability to connect data from disparate systems. Companies should also incorporate data discovery, Higginson says.
As the volume and complexity of analytics workloads continue to grow, customers are looking for more efficient and cost-effective ways to ingest and analyse data. OpenSearch Service is used for multiple purposes, such as observability, search analytics, consolidation, cost savings, compliance, and integration.
With this new functionality, customers can create up-to-date replicas of their data from applications such as Salesforce, ServiceNow, and Zendesk in an Amazon SageMaker Lakehouse and Amazon Redshift. SageMaker Lakehouse gives you the flexibility to access and query your data in-place with all Apache Iceberg compatible tools and engines.
First, many LLM use cases rely on enterprise knowledge that needs to be drawn from unstructured data such as documents, transcripts, and images, in addition to structured data from datawarehouses. Implement data privacy policies. Implement dataquality by data type and source.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content