

Reference guide to build inventory management and forecasting solutions on AWS
AWS Big Data
APRIL 11, 2023
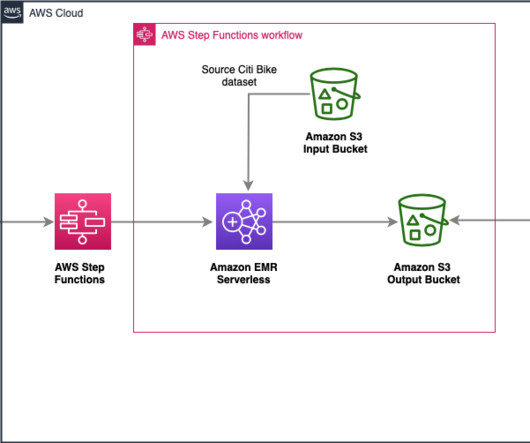
In this post, we discuss how to streamline inventory management forecasting systems with AWS managed analytics, AI/ML, and database services. Data transformation Data transformation is essential in inventory management and forecasting solutions for both data analysis around sales and inventory, as well as ML for forecasting.


















Let's personalize your content