This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Premature snapshots capture partial states, and overlapping batch windows intermingle different versions of the same data, creating temporal chaos. Customer records updated in your CRM don’t immediately reflect in your analytics warehouse. These synchronization gaps create a fragmented view of reality across your data ecosystem.
Metadata layer Contains metadata files that track table history, schema evolution, and snapshot information. In many operations (like OVERWRITE, MERGE, and DELETE), the query engine needs to know which files or rows are relevant, so it reads the current table snapshot. This is optional for operations like INSERT.
Most academic datasets pale in comparison to the complexity and volume of user interactions in real-world environments, where data is typically locked away inside companies due to privacy concerns and commercial value. Its static snapshot and lack of detailed metadata limit modern applicability. That’s beginning to change.
Iceberg provides time travel and snapshotting capabilities out of the box to manage lookahead bias that could be embedded in the data (such as delayed data delivery). Icebergs time travel capability is driven by a concept called snapshots , which are recorded in metadata files.
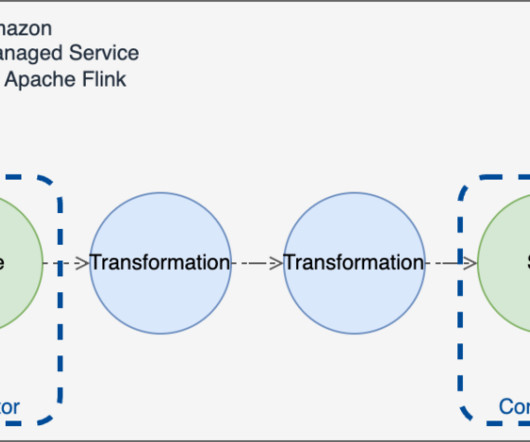
Apache Flink connectors Flink supports reading and writing data to external systems, through connectors , which are components that allow your application to interact with stream-storage message brokers, databases, or object stores. Restart from the latest snapshot (default behavior) and select allowNonRestoredState = true.
Initially, data warehouses were the go-to solution for structured data and analytical workloads but were limited by proprietary storage formats and their inability to handle unstructured data. In practice, OTFs are used in a broad range of analytical workloads, from business intelligence to machine learning.
When interacting with S3, RocksDB is designed to improve checkpointing efficiency; it does this through incremental updates and compaction to reduce the amount of data transferred to S3 during checkpoints, and by persisting fewer large state files compared to the many small files of the default state store, reducing S3 API calls and latency.
Data lakes were originally designed to store large volumes of raw, unstructured, or semi-structured data at a low cost, primarily serving big data and analytics use cases. Over time, as organizations began to explore broader applications, data lakes have become essential for various data-driven processes beyond just reporting and analytics.
Enter the host, user, and password, which are the same as those used by your Vantage instance (or ClearScape Analytics™ environment). The sample dbt project included converts raw data from an app database into a dimensional model, preparing customer and purchase data for analytics. In this example, we have used airbyte.
Common use cases include: Modular data transformation pipelines Hierarchical aggregations for progressive analysis Multi-level data validation pipelines Historical data snapshot management Optimized BI reporting with precomputed results Architecture Architectural diagram depicting Amazon Redshift’s nested materialized view structure.
The importance of publishing only high-quality data cant be overstatedits the foundation for accurate analytics, reliable machine learning (ML) models, and sound decision-making. The metadata of an Iceberg table stores a history of snapshots. The data is visualized using matplotlib for interactive data analysis.
Select Augmented Analytics with Anomaly Monitoring and Alerts! Anomaly detection in data analytics is defined as the identification of rare items, events or observations which deviate significantly from the majority of the data and do not conform to a well-defined notion of normal behavior.
Time Travel: Reproduce a query as of a given time or snapshot ID, which can be used for historical audits, validating ML models, and rollback of erroneous operations, as examples. Amazon Athena is a serverless, interactiveanalytics service that provides a simplified and flexible way to analyze petabytes of data where it lives.
Data lakes are a powerful architecture to organize data for analytical processing, because they let builders use efficient analytical columnar formats like Apache Parquet , while letting them continue to modify the shape of their data as their applications evolve with open table formats like Apache Iceberg. improvement in performance.
Visualizing the data and interacting on a single screen is no longer a luxury but a business necessity. That’s why we welcome you to the world of interactive dashboards. But before we delve into the bits and pieces of our topic, let’s answer the basic questions: What is an interactive dashboard, and why you need one?
This is where interactive weekly reports come into the picture. Powered by interactive visualizations, managers use these reports to outline the progress of the week and find improvement opportunities for the future. We will see these interactive reports in action throughout the post. What Is A Weekly Report?
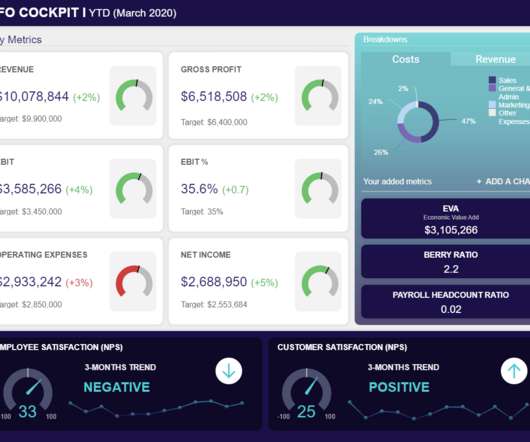
CFO dashboards exist to enhance the strategic as well as the analytical efforts related to every financial aspect of your business. In essence, a CFO dashboard is the analytical nerve center for all of your most invaluable financial data. If a CFO KPI dashboard is the analytical framework, the reports are your analytical eyes.
A CRM dashboard is a centralized hub of information that presents customer relationship management data in a way that is dynamic, interactive, and offers access to a wealth of insights that can improve your consumer-facing strategies and communications. Let’s look at this in more detail. What Is A CRM Report?
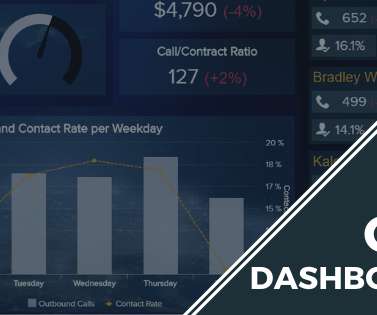
The digestible visual displays associated with call center reporting not only help to simplify analysis, thereby significantly reducing data consumption time – but the interactive nature of these reports empowers users to extract invaluable real-time data with ease. Put simply, customer service is the beating heart of your entire operation.
With touch screens, mobile devices, on-demand data, and interfaces crafted for interaction and user experience, the one-page dashboard is a relic. Trends in how we interact with information mean there isn’t a need to cram all the information together: The scrolling myth. It was the standard and the expectation.
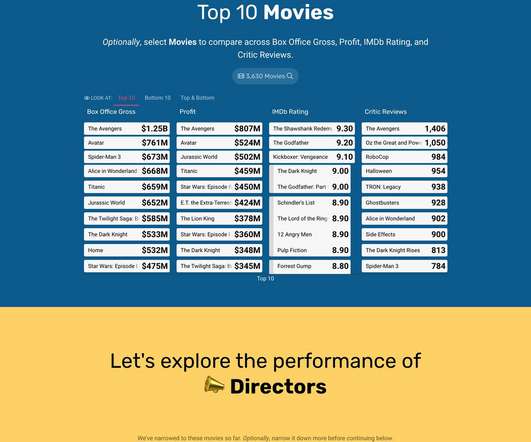
Number 6 on our list is a sales graph example that offers a detailed snapshot of sales conversion rates. 8) Revenue And Sales Interactive Management Overview. This is a really fun interactive sales graph, as it lets you see your revenue and sales according to different time periods that you select. 6) Sales Conversion.
Managerial reports use a lot of the same data as financial reports, but presented in a more useful way, for example via interactive management dashboards. However, the use of dashboards, big data, and predictive analytics is changing the face of this kind of reporting. Who are my most profitable clients?
there are two answers that go hand in hand: good exploitation of your analytics, that come from the results of a market research report. On a typical market research results example, you can interact with valuable trends, gain an insight into consumer behavior, and visualizations that will empower you to conduct effective competitor analysis.
Since humans process visual information 60.000 times faster than text , the workflow can be significantly increased by utilizing smart intelligence in the form of interactive, and real-time visual data. Today there are numerous ways in which a customer can interact with a specific company. Let’s see another example.
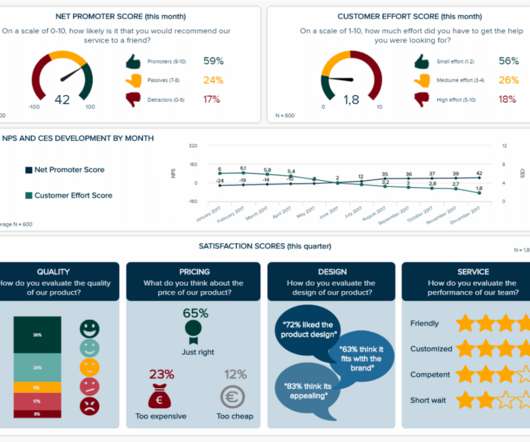
Communication: KPI reports and trackers are visual and interactive, which means that they are incredibly inclusive. In the digital age, a solid KPI tracking system is visual, interactive, customizable, and accessible via a number of mediums, including mobile and desktop.
We will discuss report examples and templates you can use to create your own report, use its features in an interactive way, and discover relevant inputs for your specific industry. In the process, we will use an online data visualization software that lets us interact with, and drill deeper into bits and pieces of relevant data.
Smarten announces the launch of SnapShot Anomaly Monitoring Alerts for Smarten Augmented Analytics. SnapShot Monitoring provides powerful data analytical features that reveal trends and anomalies and allow the enterprise to map targets and adapt to changing markets with clear, prescribed actions for continuous improvement.
Today, customers widely use OpenSearch Service for operational analytics because of its ability to ingest high volumes of data while also providing rich and interactiveanalytics. As your operational analytics data velocity and volume of data grows, bottlenecks may emerge.
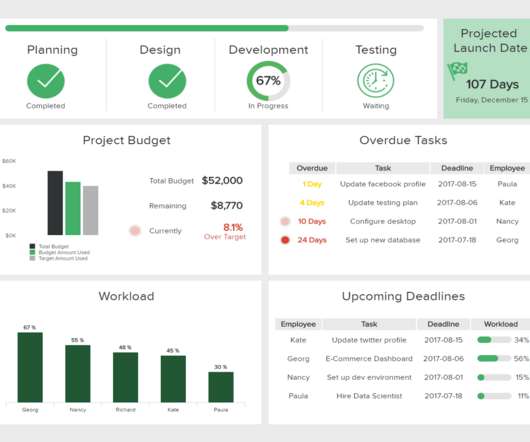
While traditional reports often include a summary, body, and conclusion in a written format, this post will focus on interactive monthly reports created with a professional dashboard creator. On the other hand, monthly performance reports can also serve as valuable tools for client reporting. What Is The Purpose Of Monthly Reporting?
This enables more informed decision-making and innovative insights through various analytics and machine learning applications. History and versioning : Iceberg’s versioning feature captures every change in table metadata as immutable snapshots, facilitating data integrity, historical views, and rollbacks.
Table of Contents 1) Benefits Of Big Data In Logistics 2) 10 Big Data In Logistics Use Cases Big data is revolutionizing many fields of business, and logistics analytics is no exception. According to studies, 92% of data leaders say their businesses saw measurable value from their data and analytics investments.
Organizations with legacy, on-premises, near-real-time analytics solutions typically rely on self-managed relational databases as their data store for analytics workloads. Near-real-time streaming analytics captures the value of operational data and metrics to provide new insights to create business opportunities.
The Iceberg table keeps track of the snapshots. consumer_iceberg$snapshots" limit 10; We can observe that we have generated multiple snapshots. Use time travel to find the table snapshot. Rahul Sonawane is a Principal Analytics Solutions Architect at AWS with AI/ML and Analytics as his area of specialty.
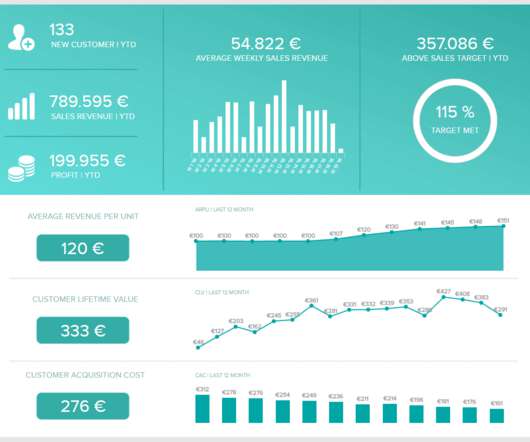
All areas of your modern-day business – from supply chain success to improved reporting processes and communications, interdepartmental collaboration, and general organization innovation – can benefit significantly from the use of analytics, structured into a live dashboard that can improve your data management efforts. Interactivity.
Storytelling through data is the process of transforming data-driven analyses into a widely-accessible visual format to influence a business decision, strategy, or action by utilizing analytical information that, ultimately, turn into actionable insights. As you’re no doubt aware—in business, time is money.
What are white-labeled reports White-label reports: Under the hood Exploring white-label dashboards Use case snapshots Horsepower under the hood. Every company is working toward harnessing data and analytics in its own way in order to stay relevant in a changing business world. Every company is becoming a data company.
You can store your data as-is, without having to first structure the data and then run different types of analytics for better business insights. Analytics use cases on data lakes are always evolving. Unlike migrate or snapshot, add_files can import files from a specific partition or partitions and doesn’t create a new Iceberg table.
Over the past decade, the successful deployment of large scale data platforms at our customers has acted as a big data flywheel driving demand to bring in even more data, apply more sophisticated analytics, and on-board many new data practitioners from business analysts to data scientists. Key Design Goals .
This is a guest post by Miguel Chin, Data Engineering Manager at OLX Group and David Greenshtein, Specialist Solutions Architect for Analytics, AWS. To do this, we required the following: A reference cluster snapshot – This ensures that we can replay any tests starting from the same state. Take snapshot from 6 x RA3.4xlarge.
Usually, these reports are considered to be financial statements which include: a balance sheet: is a snapshot of a business at a specific time and shows the ending assets, liability, and equity balances as of the balance sheet date. The balance sheet is a snapshot of your business finances at a moment in time, showing assets and liabilities.
A static report offers a snapshot of trends, data, and information over a predetermined period to provide insight and serve as a decision-making guide. As humans, we respond far more effectively to visual stimulation than text-based information, which means that interactive reporting makes data and dashboard storytelling more effective.
When analytics and dashboards are inaccurate, business leaders may not be able to solve problems and pursue opportunities. If you have been in the data profession for any length of time, you probably know what it means to face a mob of stakeholders who are angry about inaccurate or late analytics. Data errors impact decision-making.
Try our modern logistics analytics software for 14 days, completely free! Try our modern logistics analytics software for 14 days, completely free! A modern dashboard maker can help you in creating an interactive inventory KPI that will update the data automatically and you can monitor the performance in real-time.
Moreover, within just five years, the number of smart connected devices in the world will amount to more than 22 billion – all of which will produce colossal sets of collectible, curatable, and analyzable data, claimed IoT Analytics in their industry report. What does this mean? Now, let’s look at how to create a KPI report.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content