This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Enterprise data is brought into data lakes and data warehouses to carry out analytical, reporting, and data science use cases using AWS analytical services like Amazon Athena , Amazon Redshift , Amazon EMR , and so on. These data processing and analytical services support Structured Query Language (SQL) to interact with the data.
For instructions, refer to Creating a general purpose bucket. It reads metadata from your structured data store to generate SQL queries. For more information, refer to the Set up query engine for your structured data store in Amazon Bedrock Knowledge Bases. To learn more, refer to Amazon Bedrock pricing. Choose Next.
This expands data access to broader options of analytics engines. Under the hood, UniForm generates Iceberg metadata files (including metadata and manifest files) that are required for Iceberg clients to access the underlying data files in Delta Lake tables. With UniForm, you can read Delta Lake tables as Apache Iceberg tables.
Initially, data warehouses were the go-to solution for structured data and analytical workloads but were limited by proprietary storage formats and their inability to handle unstructured data. In practice, OTFs are used in a broad range of analytical workloads, from business intelligence to machine learning.
However, commits can still fail if the latest metadata is updated after the base metadata version is established. Iceberg uses a layered architecture to manage table state and data: Catalog layer Maintains a pointer to the current table metadata file, serving as the single source of truth for table state.
Amazon Redshift is a fully managed, AI-powered cloud data warehouse that delivers the best price-performance for your analytics workloads at any scale. It enables you to get insights faster without extensive knowledge of your organization’s complex database schema and metadata. Within this feature, user data is secure and private.
This week on the keynote stages at AWS re:Invent 2024, you heard from Matt Garman, CEO, AWS, and Swami Sivasubramanian, VP of AI and Data, AWS, speak about the next generation of Amazon SageMaker , the center for all of your data, analytics, and AI. The relationship between analytics and AI is rapidly evolving.
Whether youre a data analyst seeking a specific metric or a data steward validating metadata compliance, this update delivers a more precise, governed, and intuitive search experience. Refer to the product documentation to learn more about how to set up metadata rules for subscription and publishing workflows.
This is a graph of millions of edges and vertices – in enterprise data management terms it is a giant piece of master/reference data. To handle such scenarios you need a transalytical graph database – a database engine that can deal with both frequent updates (OLTP workload) as well as with graph analytics (OLAP).
Iceberg offers distinct advantages through its metadata layer over Parquet, such as improved data management, performance optimization, and integration with various query engines. Icebergs table format separates data files from metadata files, enabling efficient data modifications without full dataset rewrites.
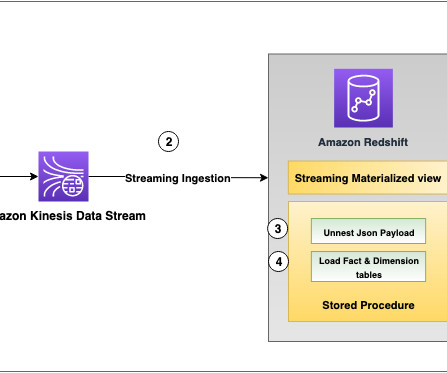
Amazon Redshift , launched in 2013, has undergone significant evolution since its inception, allowing customers to expand the horizons of data warehousing and SQL analytics. This allowed customers to scale read analytics workloads and offered isolation to help maintain SLAs for business-critical applications.
By providing a standardized framework for data representation, open table formats break down data silos, enhance data quality, and accelerate analytics at scale. For more details, refer to Iceberg Release 1.6.1. An Iceberg table’s metadata stores a history of snapshots, which are updated with each transaction.
What Is Metadata? Metadata is information about data. A clothing catalog or dictionary are both examples of metadata repositories. Indeed, a popular online catalog, like Amazon, offers rich metadata around products to guide shoppers: ratings, reviews, and product details are all examples of metadata.
The Eightfold Talent Intelligence Platform powered by Amazon Redshift and Amazon QuickSight provides a full-fledged analytics platform for Eightfold’s customers. It delivers analytics and enhanced insights about the customer’s Talent Acquisition, Talent Management pipelines, and much more.
We’re excited to announce a new feature in Amazon DataZone that offers enhanced metadata governance for your subscription approval process. With this update, domain owners can define and enforce metadata requirements for data consumers when they request access to data assets. Key benefits The feature benefits multiple stakeholders.
Organizations with legacy, on-premises, near-real-time analytics solutions typically rely on self-managed relational databases as their data store for analytics workloads. Near-real-time streaming analytics captures the value of operational data and metrics to provide new insights to create business opportunities.
reduces the Amazon DynamoDB cost associated with KCL by optimizing read operations on the DynamoDB table storing metadata. KCL uses DynamoDB to store metadata such as shard-worker mapping and checkpoints. x benefits, refer to Use features of the AWS SDK for Java 2.x. Refer to Step 4 of Migrating from KCL 2.x x to KCL 3.x
Best of CDH & HDP, with added analytic and platform features . All three will be quorums of Zookeepers and HDFS Journal nodes to track changes to HDFS Metadata stored on the Namenodes. The post A Reference Architecture for the Cloudera Private Cloud Base Data Platform appeared first on Cloudera Blog. Networking .
Pricing and availability Amazon MWAA pricing dimensions remains unchanged, and you only pay for what you use: The environment class Metadata database storage consumed Metadata database storage pricing remains the same. Refer to Amazon Managed Workflows for Apache Airflow Pricing for rates and more details.
Solution overview Data and metadata discovery is one of the primary requirements in data analytics, where data consumers explore what data is available and in what format, and then consume or query it for analysis. But in the case of unstructured data, metadata discovery is challenging because the raw data isn’t easily readable.
You can secure and centrally manage your data in the lakehouse by defining fine-grained permissions with Lake Formation that are consistently applied across all analytics and machine learning(ML) tools and engines. In this post, we demonstrate how to get started with ABAC in SageMaker Lakehouse and use with various analytics services.
Using business intelligence and analytics effectively is the crucial difference between companies that succeed and companies that fail in the modern environment. Your Chance: Want to try a professional BI analytics software? Experts say that BI and data analytics makes the decision-making process 5x times faster for businesses.
I recently saw an informal online survey that asked users which types of data (tabular, text, images, or “other”) are being used in their organization’s analytics applications. The results showed that (among those surveyed) approximately 90% of enterprise analytics applications are being built on tabular data.
BladeBridge offers a comprehensive suite of tools that automate much of the complex conversion work, allowing organizations to quickly and reliably transition their data analytics capabilities to the scalable Amazon Redshift data warehouse. For more details, refer to the BladeBridge Analyzer Demo.
If you’re a mystery lover, I’m sure you’ve read that classic tale: Sherlock Holmes and the Case of the Deceptive Data, and you know how a metadata catalog was a key plot element. When your CRM talks about “conversions” and your analytics suite talks about “conversions,” are they speaking the same language ? Enter the metadata catalog.
I wrote an extensive piece on the power of graph databases, linked data, graph algorithms, and various significant graph analytics applications. The book is awesome, an absolute must-have reference volume, and it is free (for now, downloadable from Neo4j ). Well, the graph analytics algorithm would notice!
After theyve been published, you can query the published assets from another AWS account using analytical tools such as Amazon Athena and the Amazon Redshift query editor , as shown in the following figure. The AWS account that needs to access or use the data from the producer account is referred to as the consumer account.
Refer to Introducing in-place version upgrades with Amazon MWAA for more details. With this approach, you create a new Amazon MWAA environment, migrate your metadata, and manage the transition between environments. The Airflow scheduler automatically populates some metadata tables (dag, dag_tag, and dag_code) in your new environment.
In these cases, you may want an integrated query layer to seamlessly run analytical queries across these diverse cloud stores and streamline your data analytics processes. You can consolidate your analytics workflows, reducing the need for extensive tooling and infrastructure management.
AWS Glue is a serverless data integration service that makes it simple to discover, prepare, move, and integrate data from multiple sources for analytics, machine learning (ML), and application development. For instructions, refer to How to Set Up a MongoDB Cluster. Choose the table to view the schema and other metadata.
Let’s briefly describe the capabilities of the AWS services we referred above: AWS Glue is a fully managed, serverless, and scalable extract, transform, and load (ETL) service that simplifies the process of discovering, preparing, and loading data for analytics. Amazon Athena is used to query, and explore the data.
Unfiltered Table Metadata This tab displays the response of the AWS Glue API GetUnfilteredTableMetadata policies for the selected table. Get table data and metadata for this user to see how Lake Formation permissions are enforced and so the two users can see different data (on the Authorized Data tab).
To learn more about working with events using EventBridge, refer to Events via Amazon EventBridge default bus. After you create the asset, you can add glossaries or metadata forms, but its not necessary for this post. We refer to this role as the instance-role throughout the post. Enter a name for the asset.
You can take all your data from various silos, aggregate that data in your data lake, and perform analytics and machine learning (ML) directly on top of that data. We refer to this concept as outside-in data movement. For a list of supported metrics, refer to Monitoring pipeline metrics.
Amazon SageMaker Lakehouse unifies all your data across Amazon S3 data lakes and Amazon Redshift data warehouses, helping you build powerful analytics and AI/ML applications on a single copy of data. The data is also registered in the Glue Data Catalog , a metadata repository. You don’t need to maintain complex ETL pipelines.
Organizations with particularly deep data stores might need a data catalog with advanced capabilities, such as automated metadata harvesting to speed up the data preparation process. Three Types of Metadata in a Data Catalog. The metadata provides information about the asset that makes it easier to locate, understand and evaluate.
This post provides guidance on how to build scalable analytical solutions for gaming industry use cases using Amazon Redshift Serverless. The following diagram is a conceptual analytics data hub reference architecture. They should also provide optimal performance with low or no tuning.
Along with the Glue Data Catalog’s automated compaction feature, these storage optimizations can help you reduce metadata overhead, control storage costs, and improve query performance. The Glue Data Catalog monitors tables daily, removes snapshots from table metadata, and removes the data files and orphan files that are no longer needed.
BMW Cloud Efficiency Analytics (CLEA) is a homegrown tool developed within the BMW FinOps CoE (Center of Excellence) aiming to optimize and reduce costs across all these accounts. In this post, we explore how the BMW Group FinOps CoE implemented their Cloud Efficiency Analytics tool (CLEA), powered by Amazon QuickSight and Amazon Athena.
Tens of thousands of customers use Amazon Redshift to process exabytes of data every day to power their analytic workloads. This JSON file contains the migration metadata, namely the following: A list of Google BigQuery projects and datasets. If you don’t have one, refer to Amazon Redshift Serverless. An S3 bucket.
quintillion bytes of data being produced on a daily basis and the wide range of online data analysis tools in the market, the use of data and analytics has never been more accessible. Data quality refers to the assessment of the information you have, relative to its purpose and its ability to serve that purpose. With a shocking 2.5
Amazon Redshift is a fully managed, scalable cloud data warehouse that accelerates your time to insights with fast, easy, and secure analytics at scale. Tens of thousands of customers rely on Amazon Redshift to analyze exabytes of data and run complex analytical queries, making it the widely used cloud data warehouse.
Considerations when using data sharing in Amazon Redshift For a comprehensive list of considerations and limitations of data sharing, refer to Considerations when using data sharing in Amazon Redshift. Refer to Part 1 of this series to complete the setup. xlplus) and Redshift Serverless. Choose Create to complete the setup.
Since its inception, Apache Kafka has depended on Apache Zookeeper for storing and replicating the metadata of Kafka brokers and topics. the Kafka community has adopted KRaft (Apache Kafka on Raft), a consensus protocol, to replace Kafka’s dependency on ZooKeeper for metadata management. For Metadata mode , select KRaft.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content