This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Snapshots are crucial for data backup and disaster recovery in Amazon OpenSearch Service. These snapshots allow you to generate backups of your domain indexes and cluster state at specific moments and save them in a reliable storage location such as Amazon Simple Storage Service (Amazon S3). Snapshots are not instantaneous.
OpenSearch is a distributed search and analytics engine, which is an open-source project. OpenSearch Service seamlessly integrates with other AWS offerings, providing a robust solution for building scalable and resilient search and analytics applications in the cloud.
Metadata layer Contains metadata files that track table history, schema evolution, and snapshot information. In many operations (like OVERWRITE, MERGE, and DELETE), the query engine needs to know which files or rows are relevant, so it reads the current table snapshot. This is optional for operations like INSERT.
By providing a standardized framework for data representation, open table formats break down data silos, enhance data quality, and accelerate analytics at scale. For more details, refer to Iceberg Release 1.6.1. Branching Branches are independent lineage of snapshot history that point to the head of each lineage.
One-time and complex queries are two common scenarios in enterprise data analytics. Complex queries, on the other hand, refer to large-scale data processing and in-depth analysis based on petabyte-level data warehouses in massive data scenarios. One-time queries are flexible and suitable for instant analysis and exploratory research.
Initially, data warehouses were the go-to solution for structured data and analytical workloads but were limited by proprietary storage formats and their inability to handle unstructured data. In practice, OTFs are used in a broad range of analytical workloads, from business intelligence to machine learning.
in Amazon OpenSearch Service , we introduced Snapshot Management , which automates the process of taking snapshots of your domain. Snapshot Management helps you create point-in-time backups of your domain using OpenSearch Dashboards, including both data and configuration settings (for visualizations and dashboards).
In this post, we use the term vanilla Parquet to refer to Parquet files stored directly in Amazon S3 and accessed through standard query engines like Apache Spark, without the additional features provided by table formats such as Iceberg. When a user requests a time travel query, the typical workflow involves querying a specific snapshot.
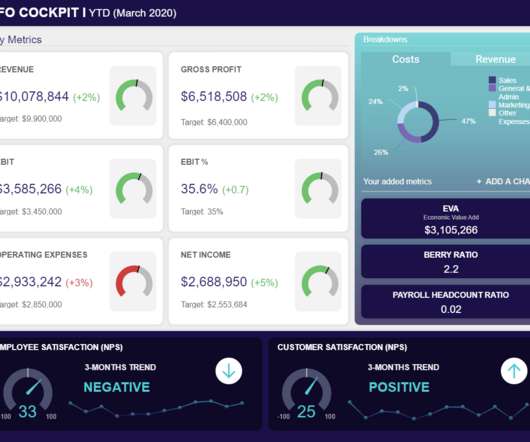
CFO dashboards exist to enhance the strategic as well as the analytical efforts related to every financial aspect of your business. In essence, a CFO dashboard is the analytical nerve center for all of your most invaluable financial data. If a CFO KPI dashboard is the analytical framework, the reports are your analytical eyes.
Iceberg creates a new version called a snapshot for every change to the data in the table. Iceberg has features like time travel and rollback that allow you to query data lake snapshots or roll back to previous versions. The Glue Data Catalog honors retention policies for Iceberg branches and tags referencing snapshots.
AWS-powered data lakes, supported by the unmatched availability of Amazon Simple Storage Service (Amazon S3), can handle the scale, agility, and flexibility required to combine different data and analytics approaches. For more information, refer to Amazon S3: Allows read and write access to objects in an S3 Bucket.
It aims to provide a framework to create low-latency streaming applications on the AWS Cloud using Amazon Kinesis Data Streams and AWS purpose-built data analytics services. The collected data is available in milliseconds to allow real-time analytics use cases, such as real-time dashboards, real-time anomaly detection, and dynamic pricing.
Organizations with legacy, on-premises, near-real-time analytics solutions typically rely on self-managed relational databases as their data store for analytics workloads. Near-real-time streaming analytics captures the value of operational data and metrics to provide new insights to create business opportunities.
Amazon Redshift is a cloud data warehousing service that provides high-performance analytical processing based on a massively parallel processing (MPP) architecture. For more information, refer SQL models. Snapshots – These implements type-2 slowly changing dimensions (SCDs) over mutable source tables.
With built-in features such as automated snapshots and cross-Region replication, you can enhance your disaster resilience with Amazon Redshift. Amazon Redshift supports two kinds of snapshots: automatic and manual, which can be used to recover data. Snapshots are point-in-time backups of the Redshift data warehouse.
This is a guest post by Miguel Chin, Data Engineering Manager at OLX Group and David Greenshtein, Specialist Solutions Architect for Analytics, AWS. To do this, we required the following: A reference cluster snapshot – This ensures that we can replay any tests starting from the same state. Take snapshot from 6 x RA3.4xlarge.
For more information on streaming applications on AWS, refer to Real-time Data Streaming and Analytics. To learn more about the available optimize data executors and catalog properties, refer to the README file in the GitHub repo. For instructions to set up an EMR notebook, refer to Amazon EMR Studio overview.
As enterprises collect increasing amounts of data from various sources, the structure and organization of that data often need to change over time to meet evolving analytical needs. For example, an ecommerce company may add new customer demographic attributes or order status flags to enrich analytics.
In this case, refer to Use CTAS and INSERT INTO to work around the 100 partition limit. If you specify partitions or buckets as part of the Apache Iceberg table definition, then you may run into the 100 partition per bucket limitation.
When data is used to improve customer experiences and drive innovation, it can lead to business growth,” – Swami Sivasubramanian , VP of Database, Analytics, and Machine Learning at AWS in With a zero-ETL approach, AWS is helping builders realize near-real-time analytics. You can also connect via a client and create the database.
Amazon SageMaker Lakehouse unifies all your data across Amazon S3 data lakes and Amazon Redshift data warehouses, helping you build powerful analytics and AI/ML applications on a single copy of data. About the authors Shovan Kanjilal is a Senior Analytics and Machine Learning Architect with Amazon Web Services.
With managed domains, you can use advanced capabilities at no extra cost such as cross-cluster search, cross-cluster replication, anomaly detection, semantic search, security analytics, and more. At release, you could create search and time series collections for full-text search and log analytics use cases, respectively.
Customers are using AWS and Snowflake to develop purpose-built data architectures that provide the performance required for modern analytics and artificial intelligence (AI) use cases. Snowflake integrates with AWS Glue Data Catalog to access the Iceberg table catalog and the files on Amazon S3 for analytical queries.
To track KPIs and set actionable benchmarks, today’s most forward-thinking businesses use what is often referred to as a KPI tracking system or a key performance indicator report. Key performance provides a panoramic snapshot of your business’s essential activities. So, what do most companies use to track KPIs?
We’ve already discussed how checkpoints, when triggered by the job manager, signal all source operators to snapshot their state, which is then broadcasted as a special record called a checkpoint barrier. When barriers from all upstream partitions have arrived, the sub-task takes a snapshot of its state.
For example, when the application scales up but runs into issues restoring from a savepoint due to operator mismatch between the snapshot and the Flink job graph. You may also receive a snapshot compatibility error when upgrading to a new Apache Flink version. For troubleshooting information, refer to documentation.
Tens of thousands of customers use Amazon Redshift to process exabytes of data every day to power their analytics workloads. Refer to the Workload Replicator README and the Configuration Comparison README for more detailed instructions to execute a replay using the respective tool. The following image shows the process flow.
For more information, refer to Retry Amazon S3 requests with EMRFS. To learn more about how to create an EMR cluster with Iceberg and use Amazon EMR Studio, refer to Use an Iceberg cluster with Spark and the Amazon EMR Studio Management Guide , respectively. We expire the old snapshots from the table and keep only the last two.
It supports modern analytical data lake operations such as create table as select (CTAS), upsert and merge, and time travel queries. Athena also supports the ability to create views and perform VACUUM (snapshot expiration) on Apache Iceberg tables to optimize storage and performance.
Apache Iceberg is an open table format for very large analytic datasets, which captures metadata information on the state of datasets as they evolve and change over time. Apache Iceberg integration is supported by AWS analytics services including Amazon EMR , Amazon Athena , and AWS Glue. The snapshot points to the manifest list.
Amazon Redshift is a fast, fully managed, petabyte-scale data warehouse that provides the flexibility to use provisioned or serverless compute for your analytical workloads. Modern analytics is much wider than SQL-based data warehousing. Solution overview AWS SCT uses a service account to connect to your Azure Synapse Analytics.
For more details, refer to the What’s New Post. In this post, we provide step-by-step guidance on how to get started with near-real time operational analytics using this feature. The transactional data from the source gets refreshed in near-real time on the destination, which processes analytical queries.
When analytics and dashboards are inaccurate, business leaders may not be able to solve problems and pursue opportunities. If you have been in the data profession for any length of time, you probably know what it means to face a mob of stakeholders who are angry about inaccurate or late analytics. Data errors impact decision-making.
Amazon Redshift Serverless makes it simple to run and scale analytics without having to manage your data warehouse infrastructure. For Filter by resource type , you can filter by Workgroup , Namespace , Snapshot , and Recovery Point. For more details on tagging, refer to Tagging resources overview. Choose Save changes.
Sometimes referred to as nested charts, they are especially useful in tables, where you can access additional drilldown options such as aggregated data for categories/breakdowns (e.g. For example, you may have different SQL databases, Google Analytics, and sales data in a CSV. In general, drilldowns can be added to any type of chart.
Many customers are looking for best practices to keep their Amazon Redshift analytics environment compliant and have an ability to respond to GDPR right to forgotten requests. Redshift resources, such as namespaces, workgroups, snapshots, and clusters can be tagged. Tags provide metadata about resources at a glance.
Customers have been using data warehousing solutions to perform their traditional analytics tasks. Recently, data lakes have gained lot of traction to become the foundation for analytical solutions, because they come with benefits such as scalability, fault tolerance, and support for structured, semi-structured, and unstructured datasets.
The third cost component is durable application backups, or snapshots. This is entirely optional and its impact on the overall cost is small, unless you retain a very large number of snapshots. The cost of durable application backup (snapshots) is $0.023 per GB per month. per hour, and attached application storage costs $0.10
BI tools access and analyze data sets and present analytical findings in reports, summaries, dashboards, graphs, charts, and maps to provide users with detailed intelligence about the state of the business. Whereas BI studies historical data to guide business decision-making, business analytics is about looking forward.
Customers across diverse industries rely on Amazon OpenSearch Service for interactive log analytics, real-time application monitoring, website search, vector database, deriving meaningful insights from data, and visualizing these insights using OpenSearch Dashboards. Under Generate the link as , select Snapshot and choose Copy iFrame code.
Refer to OpenSearch language clients for a list of all supported client libraries. For more information, refer to Starting an upgrade (CLI) and Starting an upgrade (SDK). Take a manual snapshot of your domain. This snapshot serves as a backup that you can restore on a new domain if you want to return to using the prior version.
Data Vault overview For a brief review of the core Data Vault premise and concepts, refer to the first post in this series. For more information, refer to Amazon Redshift database encryption. Automated snapshots retain all of the data required to restore a data warehouse from a snapshot. model in Amazon Redshift.
Amazon Redshift Serverless makes it simple to run and scale analytics in seconds. For more information, refer to Granting access to monitor queries. For a complete list of system views and their uses, refer to Monitoring views. For more information, refer to WLM query monitoring rules.
The result is made available to the application by querying the latest snapshot. The snapshot constantly updates through stream processing; therefore, the up-to-date data is provided in the context of a user prompt to the model. For more information, refer to Notions of Time: Event Time and Processing Time.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content