This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ArticleVideo Book This article was published as a part of the Data Science Blogathon In the last blog, we discussed what an Artificial Neural network. The post Implementing Artificial Neural Network on UnstructuredData appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction I am sure those of you working with data in any. The post What I did when I had to work with unstructureddata? appeared first on Analytics Vidhya.
Then connect the graph nodes and relations extracted from unstructureddata sources, reusing the results of entity resolution to disambiguate terms within the domain context. Chunk your documents from unstructureddata sources, as usual in GraphRAG. Let’s revisit the point about RAG borrowing from recommender systems.
It processes and handles structured and unstructureddata in exabytes (1018 bytes). The most common use cases of Redshift include large-scale data migration, log analysis, processing real-time analytics, joining multiple […].
For that, we need to compare, sort, and cluster various data points within the unstructureddata. Similarity and dissimilarity measures are crucial in data science, to compare and quantify how similar the data points are.
This article was published as a part of the Data Science Blogathon Introduction Let’s look at a practical application of the supervised NLP fastText model for detecting sarcasm in news headlines. About 80% of all information is unstructured, and text is one of the most common types of unstructureddata.
This article was published as a part of the Data Science Blogathon. Introduction Unstructureddata contains a plethora of information. A Simple Guide to Keyword Extraction in Python appeared first on Analytics Vidhya. It is like energy. The post Words that matter!
Introduction A data lake is a centralized repository for storing, processing, and securing massive amounts of structured, semi-structured, and unstructureddata. It can store data in its native format and process any type of data, regardless of size. Data Lakes are an important […].
ArticleVideo Book Objective Text data is a type of unstructureddata used in natural language processing. Understand how to preprocess the text data before. The post Tokenization and Text Normalization appeared first on Analytics Vidhya.
Introduction In the ever-evolving field of natural language processing and artificial intelligence, the ability to extract valuable insights from unstructureddata sources, like scientific PDFs, has become increasingly critical.
Azure Data Lake Storage is capable of storing large quantities of structured, semi-structured, and unstructureddata in […]. The post Introduction to Azure Data Lake Storage Gen2 appeared first on Analytics Vidhya. It combines the capabilities of ADLS Gen1 with Azure Blob Storage.
Fundamentally, it is the art of transforming unstructureddata into a usable format and then drawing actionable insights from it. But with technological advancements like machine learning and artificial intelligence, it has become an interdisciplinary area that utilizes computer […] The post What is Data Science?
Unstructureddata, including text documents and social media posts, exacerbates this challenge with its inherent lack of predefined structure, making extracting meaningful insights even […] The post Ways of Converting Textual Data into Structured Insights with LLMs appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon Introduction Analyzing texts is far more complicated than analyzing typical tabulated data (e.g. retail data) because texts fall under unstructureddata. Different people express themselves quite differently when it comes to […].
ArticleVideo Book Introduction Deep learning techniques are popularly used for unstructureddata such as text data or image data. appeared first on Analytics Vidhya. And before working on any. The post How Images are stored in the computer?
Introduction Textual data from social media posts, customer feedback, and reviews are valuable resources for any business. There is a host of useful information in such unstructureddata that we can discover. Making sense of this unstructureddata can help companies better understand […].
Overview What is sports analytics? What are the different use cases of sports analytics? We answer these questions here Understand how sports analytics can. The post Sports Analytics – Generating Actionable Insights using Cricket Commentary appeared first on Analytics Vidhya.
As someone deeply involved in shaping data strategy, governance and analytics for organizations, Im constantly working on everything from defining data vision to building high-performing data teams. My work centers around enabling businesses to leverage data for better decision-making and driving impactful change.
Introduction In this article, I am going to explain, how can we use log parsing with Spark and Scala to get meaningful data from unstructureddata. In my experience, after parsing a lot of logs from different sources, I have found no data is […].
Introduction Text Mining is also known as Text Data Mining or Text Analytics or is an artificial intelligence (AI) technology that uses natural language processing (NLP) to extract essential data from standard language text. It is a process to transform the unstructureddata (text […].
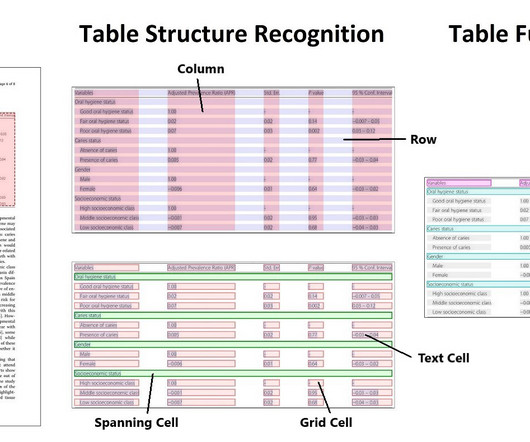
Introduction Have you ever worked with unstructureddata and thought of a way to detect the presence of tables in your document? To help you quickly process your documents?
Introduction on Apache Hive Advanced big data tools must handle the massive amounts of structured and unstructureddata generated daily. Data is not increasing only in terms of volume, but the variety and veracity of data are also growing. Big Data uses Hive […].
It takes unstructureddata from multiple sources as input and stores it […]. The post Basic Concept and Backend of AWS Elasticsearch appeared first on Analytics Vidhya. It is a Lucene-based search engine developed in Java but supports clients in various languages such as Python, C#, Ruby, and PHP.
Introduction A data lake is a central data repository that allows us to store all of our structured and unstructureddata on a large scale. You may run different types of analytics, from dashboards and visualizations to big data processing, real-time analytics, and machine […].
Although Amazon DataZone automates subscription fulfillment for structured data assetssuch as data stored in Amazon Simple Storage Service (Amazon S3), cataloged with the AWS Glue Data Catalog , or stored in Amazon Redshift many organizations also rely heavily on unstructureddata. Enter a name for the asset.
Domo is best known as a business intelligence (BI) and analytics software provider, thanks to its functionality for visualization, reporting, data science and embedded analytics. Domo was founded in 2010 by chief executive officer Josh James, previously founder and CEO of web analytics provider Omniture.
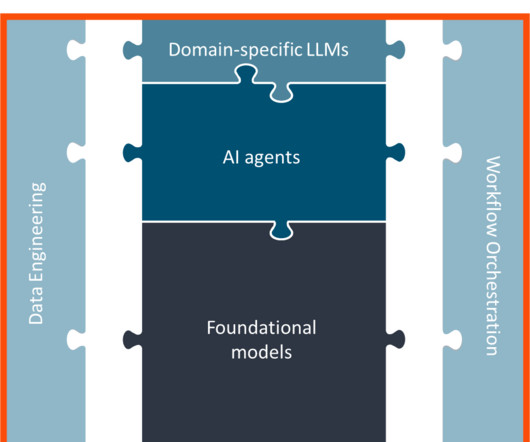
I was recently asked to identify key modern data architecture trends. Data architectures have changed significantly to accommodate larger volumes of data as well as new types of data such as streaming and unstructureddata. Here are some of the trends I see continuing to impact data architectures.
They may implement AI, but the data architecture they currently have is not equipped, or able, to scale with the huge volumes of data that power AI and analytics. This requires greater flexibility in systems to better manage data storage and ensure quality is maintained as data is fed into new AI models.
“Our big challenge, honestly, is the unstructureddata,” Seetharam said, noting that Corning must now “figure out how to categorize [unstructureddata] and bring it in a form that can be useful.” Bhavesh Dayalji, CAIO at S&P Global, added that integrating all kinds of data structures into gen AI models is a challenge.
Its about building on what you already have data, processes, and people with smart tools that enhance productivity and reduce complexity. Here are a few things to look for in a security analytics platform designed to scale with your team: Designed for security analysts Modern AI-powered platforms help analysts move faster not start over.
Unstructureddata has been a significant factor in data lakes and analytics for some time. Twelve years ago, nearly a third of enterprises were working with large amounts of unstructureddata. As I’ve pointed out previously , unstructureddata is really a misnomer.
Improving data quality and integrating new data sources to enrich customer and prospect data are vital for applying AI in marketing and sales. For example, many organizations have been centralizing customer data for some time, but gen AI can greatly enhance the ability to find patterns and signals in unstructureddata sources.
In today’s data-driven world, large enterprises are aware of the immense opportunities that data and analytics present. Yet, the true value of these initiatives is in their potential to revolutionize how data is managed and utilized across the enterprise.
To integrate AI into enterprise workflows, we must first do the foundation work to get our clients data estate optimized, structured, and migrated to the cloud. It requires the ability to break down silos between disparate data sets and keep data flowing in real-time. To learn more, visit us here.
Introduction A data lake is a centralized and scalable repository storing structured and unstructureddata. The need for a data lake arises from the growing volume, variety, and velocity of data companies need to manage and analyze.
Analytics remained one of the key focus areas this year, with significant updates and innovations aimed at helping businesses harness their data more efficiently and accelerate insights. This premier event showcased groundbreaking advancements, keynotes from AWS leadership, hands-on technical sessions, and exciting product launches.
Here are just 10 of the many key features of Datasphere that were covered during the launch day announcements : Datasphere works with the SAP Analytics Cloud and runs on the existing SAP BTP (Business Technology Platform), with all the essential features: security, access control, high availability. Datasphere is not just for data managers.
Technology leaders want to harness the power of their data to gain intelligence about what their customers want and how they want it. This is why the overall data and analytics (D&A) market is projected to grow astoundingly and expected to jump to $279.3 billion by 2030. That failure can be costly.
Building a successful data strategy at scale goes beyond collecting and analyzing data,” says Ryan Swann, chief dataanalytics officer at financial services firm Vanguard. Overlooking these data resources is a big mistake. What are the goals for leveraging unstructureddata?”
Testing and Data Observability. Process Analytics. We have also included vendors for the specific use cases of ModelOps, MLOps, DataGovOps and DataSecOps which apply DataOps principles to machine learning, AI, data governance, and data security operations. . Reflow — A system for incremental data processing in the cloud.
They’re still struggling with the basics: tagging and labeling data, creating (and managing) metadata, managing unstructureddata, etc. Nearly one-quarter of respondents work as data scientists or analysts (see Figure 1). An additional 7% are data engineers. Some other common data quality issues (Figure 4)—e.g.,
We have embarked on a journey to unify the broad range of AWS data processing, analytics, and AI capabilities, starting with the announcement of Amazon SageMaker Unified Studio at re:Invent 2024. This includes the data integration capabilities mentioned above, with support for both structured and unstructureddata.
This infrastructure must be suited to handle extreme data growth, especially with unstructureddata. An estimated 90% of the global datasphere is comprised of unstructureddata 1. And it’s growing rapidly, estimated at 55-65% 2 year-over-year and three times faster than structured data.
As was explained in ISGs State of Generative AI Market Report , AI requires data that is clean, well-organized and compliant with regulatory standards. MarkLogic is a multi-model database platform designed to support operational and analytic workloads.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content