This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. Introduction A datalake is a centralized repository for storing, processing, and securing massive amounts of structured, semi-structured, and unstructured data. DataLakes are an important […].
This article was published as a part of the Data Science Blogathon. Introduction Today, DataLake is most commonly used to describe an ecosystem of IT tools and processes (infrastructure as a service, software as a service, etc.) that work together to make processing and storing large volumes of data easy.
This article was published as a part of the Data Science Blogathon. Introduction You can access your Azure DataLake Storage Gen1 directly with the RapidMiner Studio. This is the feature offered by the Azure DataLake Storage connector. It supports both reading and writing operations.
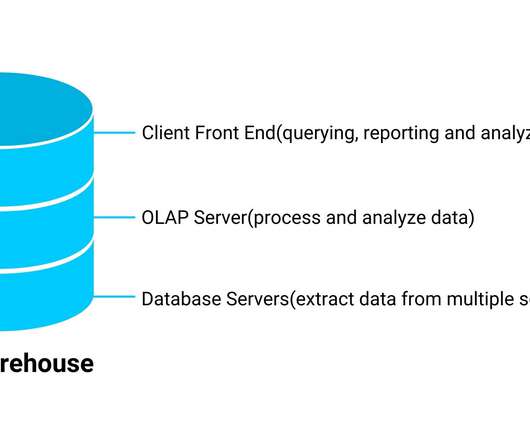
By their definition, the types of data it stores and how it can be accessible to users differ. This article will discuss some of the features and applications of data warehouses, data marts, and data […]. The post Data Warehouses, Data Marts and DataLakes appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction Data is defined as information that has been organized in a meaningful way. Data collection is critical for businesses to make informed decisions, understand customers’ […]. The post DataLake or Data Warehouse- Which is Better?
This article was published as a part of the Data Science Blogathon. Azure DataLake Storage is capable of storing large quantities of structured, semi-structured, and unstructured data in […]. The post Introduction to Azure DataLake Storage Gen2 appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the Data Science Blogathon. Introduction DataLake architecture for different use cases – Elegant. The post A Guide to Build your DataLake in AWS appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction A datalake is a central data repository that allows us to store all of our structured and unstructured data on a large scale. The post A Detailed Introduction on DataLakes and Delta Lakes appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Before seeing the practical implementation of the use case, let’s briefly introduce Azure DataLake Storage Gen2 and the Paramiko module. The post An Overview of Using Azure DataLake Storage Gen2 appeared first on Analytics Vidhya.
In this article, we will explore the evolution of Iceberg, its key features like ACID transactions, partition evolution, and time travel, and how it integrates with modern datalakes. Well also dive into […] The post How to Use Apache Iceberg Tables? appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Image Source: GitHub Table of Contents What is Data Engineering? Components of Data Engineering Object Storage Object Storage MinIO Install Object Storage MinIO DataLake with Buckets Demo DataLake Management Conclusion References What is Data Engineering?
This article was published as a part of the Data Science Blogathon. The post How a Delta Lake is Process with Azure Synapse Analytics appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction Most of you would know the different approaches for building a data and analytics platform. You would have already worked on systems that used traditional warehouses or Hadoop-based datalakes. Selecting one among […].
This article was published as a part of the Data Science Blogathon. Introduction In the modern data world, Lakehouse has become one of the most discussed topics for building a data platform.
Datalakes and data warehouses are probably the two most widely used structures for storing data. In this article, we will explore both, unfold their key differences and discuss their usage in the context of an organization. Data Warehouses and DataLakes in a Nutshell. Key Differences.
Azure DataLake Storage Gen2 is based on Azure Blob storage and offers a suite of big data analytics features. If you don’t understand the concept, you might want to check out our previous article on the difference between datalakes and data warehouses. Determine your preparedness.
For many organizations, this centralized data store follows a datalake architecture. Although datalakes provide a centralized repository, making sense of this data and extracting valuable insights can be challenging. In our example, we use PDF files from the AWS Prescriptive Guidance portal.
Datalake is a newer IT term created for a new category of data store. But just what is a datalake? According to IBM, “a datalake is a storage repository that holds an enormous amount of raw or refined data in native format until it is accessed.” That makes sense. I think the […].
For a while now, vendors have been advocating that people put their data in a datalake when they put their data in the cloud. The DataLake The idea is that you put your data into a datalake. Then, at a later point in time, the end user analyst can come along and […].
Reading Time: 3 minutes First we had data warehouses, then came datalakes, and now the new kid on the block is the data lakehouse. But what is a data lakehouse and why should we develop one? In a way, the name describes what.
In today’s rapidly evolving digital landscape, seamless data, applications, and device integration are more pressing than ever. Enter Microsoft Fabric, a cutting-edge solution designed to revolutionize how we interact with technology.
Reading Time: 2 minutes The data lakehouse has emerged as a powerful and popular data architecture, combining the scale of datalakes with the management features of data warehouses. It promises a unified platform for storing and analyzing structured and unstructured data, particularly for.
to store and analyze this data to get valuable business insights from it. You will study top 11 azure interview questions in this article which will discuss different data services like Azure Cosmos […] The post Top 11 Azure Data Services Interview Questions in 2023 appeared first on Analytics Vidhya.
Reading Time: 6 minutes Datalake, by combining the flexibility of object storage with the scalability and agility of cloud platforms, are becoming an increasingly popular choice as an enterprise data repository. Whether you are on Amazon Web Services (AWS) and leverage AWS S3.
Reading Time: 6 minutes Datalake, by combining the flexibility of object storage with the scalability and agility of cloud platforms, are becoming an increasingly popular choice as an enterprise data repository. Whether you are on Amazon Web Services (AWS) and leverage AWS S3.
In attempts to overcome their big data challenges, organizations are exploring datalakes as repositories where huge volumes and varieties of. The post Is Data Virtualization the Secret Behind Operationalizing DataLakes?
In the ever-evolving landscape of data management, two key concepts have emerged as essential components for organizations seeking to harness the power of their data: data marts and datalakes. Understanding the distinctions […]
Introduction Enterprises have been building data platforms for the last few decades, and data architectures have been evolving. Let’s first look at how things have changed and how […].
For many enterprises, a hybrid cloud datalake is no longer a trend, but becoming reality. Due to these needs, hybrid cloud datalakes emerged as a logical middle ground between the two consumption models. Without business context, business users are less likely to use the datalake and insights will be hard to come by.
This increase was driven in part by the launch of my new Maths & Science section , articles from which claimed no fewer than 6 slots in the 2018 top 10 articles, when measured by hits [1]. This is my selection of the articles that I enjoyed writing most, which does not always overlap with the most popular ones. May onwards.
Traditional relational databases provide certain benefits, but they are not suitable to handle big and various data. That is when datalake products started gaining popularity, and since then, more companies introduced lake solutions as part of their data infrastructure. AWS Athena and S3. How to improve indexing.
In this article, we want to dig deeper into the fundamentals of machine learning as an engineering discipline and outline answers to key questions: Why does ML need special treatment in the first place? ML use cases rarely dictate the master data management solution, so the ML stack needs to integrate with existing data warehouses.
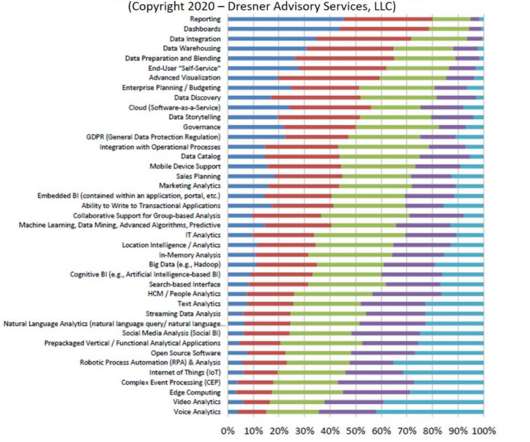
Among all the hot analytics initiatives to choose from (big data, IoT, NLP, data storytelling, cognitive BI, GDPR), plain old reporting is what is considered the most important strategic initiative. It is everywhere, holding the data universe together, yet it manages to elude our attention and affection.
This article was co-authored by Duke Dyksterhouse , an Associate at Metis Strategy. Data & Analytics is delivering on its promise. So, they built a data-lake. The datalake, too, took on new purpose.
Whether it’s data management, analytics, or scalability, AWS can be the top-notch solution for any SaaS company. In this article we will list 10 things AWS can do for your SaaS company. This article finally gets to the core question we started with: what can AWS do for your SaaS business? Data storage databases.
Many organizations in a variety of industries struggle to access the customer data they need to provide personalized and contextual experiences across all touchpoints. To read this article in full, please click here
Preparing for an artificial intelligence (AI)-fueled future, one where we can enjoy the clear benefits the technology brings while also the mitigating risks, requires more than one article. This first article emphasizes data as the ‘foundation-stone’ of AI-based initiatives. Establishing a Data Foundation. era is upon us.
It’s interesting how the number of projected IoT devices being connected in 2023 can differ by 26 billion from article to article. Today’s management and infrastructure are designed to populate a datalake with valuable information that helps accurately determine the type of endpoint clients that are on your network.
This blog post outlines detailed step by step instructions to perform Hive Replication from an on-prem CDH cluster to a CDP Public Cloud DataLake. CDP DataLake cluster versions – CM 7.4.0, Pre-Check: DataLake Cluster. Understanding Ranger Policies in DataLake Cluster. Runtime 7.2.8.
This article forms part of her further adventures [1]. Get us data now… Our CDO has helped us to work out a plan. We built a warehouse first, now for a datalake. Got our data now. Another article from peterjamesthomas.com. In my last post , we met Jane Doe, CEO. Not a bright spot anywhere. Notes. .
In her groundbreaking article, How to Move Beyond a Monolithic DataLake to a Distributed Data Mesh, Zhamak Dehghani made the case for building data mesh as the next generation of enterprise data platform architecture.
There are several choices to consider, each with its own set of advantages and disadvantages: Data warehouses are used to store data that has been processed for a specific function from one or more sources. Datalakes hold raw data that has not yet been altered to meet a specific purpose.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content