This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
1) What Is DataQuality Management? 4) DataQuality Best Practices. 5) How Do You Measure DataQuality? 6) DataQuality Metrics Examples. 7) DataQuality Control: Use Case. 8) The Consequences Of Bad DataQuality. 9) 3 Sources Of Low-QualityData.
As technology and business leaders, your strategic initiatives, from AI-powered decision-making to predictive insights and personalized experiences, are all fueled by data. Yet, despite growing investments in advanced analytics and AI, organizations continue to grapple with a persistent and often underestimated challenge: poor dataquality.
Data collections are the ones and zeroes that encode the actionable insights (patterns, trends, relationships) that we seek to extract from our data through machine learning and data science. Source: [link] SAP also announced key partners that further enhance Datasphere as a powerful business data fabric.
Getting to great dataquality need not be a blood sport! This article aims to provide some practical insights gained from enterprise master dataquality projects undertaken within the past […].
Ensuring dataquality is an important aspect of data management and these days, DBAs are increasingly being called upon to deal with the quality of the data in their database systems more than ever before. The importance of qualitydata cannot be overstated.
If the data is not easily gathered, managed and analyzed, it can overwhelm and complicate decision-makers. Data insight techniques provide a comprehensive set of tools, data analysis and quality assurance features to allow users to identify errors, enhance dataquality, and boost productivity.’
Know thy data: understand what it is (formats, types, sampling, who, what, when, where, why), encourage the use of data across the enterprise, and enrich your datasets with searchable (semantic and content-based) metadata (labels, annotations, tags). The latter is essential for Generative AI implementations.
Data is everywhere! But can you find the data you need? What can be done to ensure the quality of the data? How can you show the value of investing in data? Can you trust it when you get it? These are not new questions, but many people still do not know how to practically […].
Will the new creative, diverse and scalable data pipelines you are building also incorporate the AI governance guardrails needed to manage and limit your organizational risk? We will tackle all these burning questions and more in this article. And lets not forget about the controls.
In this article, we will walk you through the process of implementing fine grained access control for the data governance framework within the Cloudera platform. First, a set of initial metadata objects are created by the data steward. A business metadata collection called “Project.”
Aptly named, metadata management is the process in which BI and Analytics teams manage metadata, which is the data that describes other data. In other words, data is the context and metadata is the content. Without metadata, BI teams are unable to understand the data’s full story.
Well, of course, metadata is data. Our standard definition explicitly says that metadata is data describing other data. So why would I even ask this question in the article title?
While this is a technically demanding task, the advent of ‘Payload’ Data Journeys (DJs) offers a targeted approach to meet the increasingly specific demands of Data Consumers. Deploying a Data Journey Instance unique to each customer’s payload is vital to fill this gap.
Metadata enrichment is about scaling the onboarding of new data into a governed data landscape by taking data and applying the appropriate business terms, data classes and quality assessments so it can be discovered, governed and utilized effectively. Scalability and elasticity. Public API.
In this article, we will walk you through the process of implementing fine grained access control for the data governance framework within the Cloudera platform. First, a set of initial metadata objects are created by the data steward. A business metadata collection called “Project.”
Preparing for an artificial intelligence (AI)-fueled future, one where we can enjoy the clear benefits the technology brings while also the mitigating risks, requires more than one article. This first article emphasizes data as the ‘foundation-stone’ of AI-based initiatives. Establishing a Data Foundation. era is upon us.
In part one of “Metadata Governance: An Outline for Success,” I discussed the steps required to implement a successful data governance environment, what data to gather to populate the environment, and how to gather the data.
Lower cost data processes. This article is will help you understand the critical role of information stewardship as it relates to data and analytics. These stewards monitor the input and output of data integrations and workflows to ensure dataquality. More effective business process execution.
KGs bring the Semantic Web paradigm to the enterprises, by introducing semantic metadata to drive data management and content management to new levels of efficiency and breaking silos to let them synergize with various forms of knowledge management. The RDF data model and the other standards in W3C’s Semantic Web stack (e.g.,
With in-place table migration, you can rapidly convert to Iceberg tables since there is no need to regenerate data files. Only metadata will be regenerated. Newly generated metadata will then point to source data files as illustrated in the diagram below. . Dataquality using table rollback.
(BFSI, PHARMA, INSURANCE AND NON-PROFIT) CASE STUDIES FOR AUTOMATED METADATA-DRIVEN AUTOMATION. As well as introducing greater efficiency to the data governance process, automated data mapping tools enable data to be auto-documented from XML that builds mappings for the target repository or reporting structure.
The particular episode we recommend looks at how WeWork struggled with understanding their data lineage so they created a metadata repository to increase visibility. Agile Data. Another podcast we think is worth a listen is Agile Data. Techcopedia follows the latest trends in data and provides comprehensive tutorials.
Apache Kafka is a well-known open-source event store and stream processing platform and has grown to become the de facto standard for data streaming. Apache Kafka transfers data without validating the information in the messages. Kafka does not examine the metadata of your messages. What’s next?
But while state and local governments seek to improve policies, decision making, and the services constituents rely upon, data silos create accessibility and sharing challenges that hinder public sector agencies from transforming their data into a strategic asset and leveraging it for the common good. .
A data catalog can assist directly with every step, but model development. And even then, information from the data catalog can be transferred to a model connector , allowing data scientists to benefit from curated metadata within those platforms. How Data Catalogs Help Data Scientists Ask Better Questions.
“Most enterprise data is unstructured and semi-structured documents and code, as well as images and video. For example, gen AI can be used to extract metadata from documents, create indexes of information and knowledge graphs, and to query, summarize, and analyze this data.
Experts say that BI and data analytics makes the decision-making process 5x times faster for businesses. Renowned author Bernard Marr wrote an insightful article about Shell’s journey to become a fully data-driven company. Let’s look at our first use case.
Fit for Purpose data has been a foundational concept of Data Governance for as long as I’ve been in the field…so that’s 10-15 years now. Most dataquality definitions take Fit-for-Purpose as a given.
The purpose of this article is to provide a model to conduct a self-assessment of your organization’s data environment when preparing to build your Data Governance program. Take the […].
I believe that my strongest articles and columns come from opportunities to work with great companies and organization. A long-time client recently told me that, for their data and […]. Of course, I cannot mention their names. But there is a strong possibility that you may have some of the same opportunities in front of you.
Over the past few months, my team in Castlebridge and I have been working with clients delivering training to business and IT teams on data management skills like data governance, dataquality management, data modelling, and metadata management.
Cloudera Data Platform (CDP) is no different: it’s a hybrid data platform that meets organizations’ needs to get to grips with complex data anywhere, turning it into actionable insight quickly and easily. And, crucial for a hybrid data platform, it does so across hybrid cloud.
Modern data governance relies on automation, which reduces costs. Automated tools make data governance processes very cost-effective. Machine learning plays a key role, as it can increase the speed and accuracy of metadata capture and categorization. This empowers leaders to see and refine human processes around data.
If you do a general internet search for data catalogs, all sorts of possibilities emerge. If you look closely, and ask a lot of questions, you will find that some of these products are not actually fully functional data catalogs at all. Some software products start out life-solving a specific use case related to data, […].
Data search just got better. Alation has upgraded search with ranking that weights valuable social signals, and a new view that shares metadata alongside results. Searchers can now hunt through data domains, with filters that help them spotlight the best asset more quickly. With the latest release of 2021.2, Trust flag text.
This is a English translation of an article by Thérèse van Bellinghen that first appeared on the SAP News Blog. . They discussed how medium and small sized enterprises should handle the digital transformation, and the concrete roles of Data Protection Officers and Innovation Evangelists during this process.
According to this article , it costs $54,500 for every kilogram you want into space. That means removing errors, filling in missing information and harmonizing the various data sources so that there is consistency. Once that is done, data can be transformed and enriched with metadata to facilitate analysis.
As shown above, the data fabric provides the data services from the source data through to the delivery of data products, aligning well with the first and second elements of the modern data platform architecture. Mark: Another concept gaining ground is the idea of data observability.
Some tools, such as Great Expectations and Soda, are dedicated to continuous monitoring and validation, whilst others, such as dbt and Talend Data Integration, are intended for SQL-based transformations or ETL operations. Proper tooling & environment (Python ecosystem for Great Expectations, data warehouse credentials and macros fordbt).
In this article, we are bringing science fiction to the semantic technology (and data management) talk to shed some light on three common data challenges: the storage, retrieval and security of information. We will talk through these from the perspective of Linked Data (and cyberpunk).
According to an article in Harvard Business Review , cross-industry studies show that, on average, big enterprises actively use less than half of their structured data and sometimes about 1% of their unstructured data. The third challenge is how to combine data management with analytics.
Identify where your company currently stands in data governance, while keeping in mind your master data management plan, dataquality goals, data stewardship, data lineage, and metadata. Start to develop a data governance framework. Then, prioritize where you want to be.
Indeed, automation is a key element to data catalog features, which enhance data security. Selecting a Data Catalog. To support data security, an effective data catalog should have features, like a business glossary, wiki-like articles, and metadata management.
As a reminder, here’s Gartner’s definition of data fabric: “A design concept that serves as an integrated layer (fabric) of data and connecting processes. In this blog, we will focus on the “integrated layer” part of this definition by examining each of the key layers of a comprehensive data fabric in more detail.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




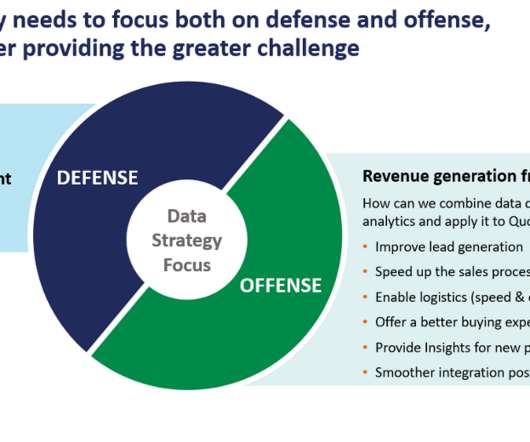














































Let's personalize your content