This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
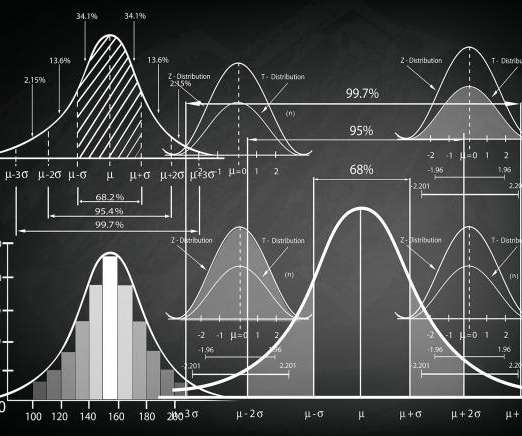
This article was published as a part of the Data Science Blogathon Introduction to StatisticsStatistics is a type of mathematical analysis that employs quantified models and representations to analyse a set of experimental data or real-world studies. Data processing is […]. Data processing is […].
Today’s article comes from Maryfrances Porter, Ph.D. & — Thank you to Ann Emery, Depict Data Studio, and her Simple Spreadsheets class for inviting us to talk to them about the use of statistics in nonprofit program evaluation! . Why Nonprofits Shouldn’t Use Statistics. & Alison Nagel, Ph.D And here’s why!
Computer Vision: Data Mining: Data Science: Application of scientific method to discovery from data (including Statistics, Machine Learning, data visualization, exploratory data analysis, experimentation, and more). They cannot process language inputs generally. Examples: (1) Automated manufacturing assembly line. (2) 4) Prosthetics.
For example, imagine a fantasy football site is considering displaying advanced player statistics. A ramp-up strategy may mitigate the risk of upsetting the site’s loyal users who perhaps have strong preferences for the current statistics that are shown. One reason to do ramp-up is to mitigate the risk of never before seen arms.
Some of that uncertainty is the result of statistical inference, i.e., using a finite sample of observations for estimation. But there are other kinds of uncertainty, at least as important, that are not statistical in nature. Among these, only statistical uncertainty has formal recognition. leaves out.
The article is interspersed with rich columns and pictures, introduces the basic business principles in a simple way with real cases from many companies and entrepreneurs around the world. – Head First Data Analysis: A learner’s guide to big numbers, statistics, and good decisions. By Michael Milton.
A 1958 Harvard Business Review article coined the term information technology, focusing their definition on rapidly processing large amounts of information, using statistical and mathematical methods in decision-making, and simulating higher order thinking through applications.
Two years later, I published a post on my then-favourite definition of data science , as the intersection between software engineering and statistics. This article is a short summary of my understanding of the definition of data science in 2018. Numerous articles have been published on the meaning of data science in the past six years.
You need people with deep skills in Scientific Method , Design of Experiments , and Statistical Analysis. The team did the normal modeling to ensure that the results were statistically significant (large enough sample set, sufficient number of conversions in each variation). * ask for a raise. It is that simple. Okay, it is not simple.
Common elements of DataOps strategies include: Collaboration between data managers, developers and consumers A development environment conducive to experimentation Rapid deployment and iteration Automated testing Very low error rates. But the approaches and principles that form the basis of DataOps have been around for decades.
In addition, Jupyter Notebook is also an excellent interactive tool for data analysis and provides a convenient experimental platform for beginners. Pandas incorporates a large number of analysis function methods, as well as common statistical models and visualization processing. From Google. Data Analysis Libraries.
And it can look up an author and make statistical observations about their interests. ChatGPT offers users a paid account that costs $20/month, which is good enough for experimenters, though there is a limit on the number of requests you can make. Again, ChatGPT is predicting a response to your question.
Skomoroch proposes that managing ML projects are challenging for organizations because shipping ML projects requires an experimental culture that fundamentally changes how many companies approach building and shipping software. Yet, this challenge is not insurmountable. for what is and isn’t possible) to address these challenges.
This article presents a case study of how DataRobot was able to achieve high accuracy and low cost by actually using techniques learned through Data Science Competitions in the process of solving a DataRobot customer’s problem. If this knock leveling could be automated, it would result in significant cost savings.
by SANGHO YOON In this article, we discuss an approach to the design of experiments in a network. Experimentation on networks A/B testing is a standard method of measuring the effect of changes by randomizing samples into different treatment groups. This simulation is based on the actual user network of GCP.
Santiago Ortiz’s article, 45 ways to communicate two quantiles , shows us a stunning expanse for just two numbers. Strip plots in the flesh: NPR looks at school funding The LA Times on pop music’s evolution Eurostat’s key European statistics Jittered Strip Plot. The histogram's familiarity makes it quick to interpret for many.
In an ideal world, experimentation through randomization of the treatment assignment allows the identification and consistent estimation of causal effects. Identification We now discuss formally the statistical problem of causal inference. We start by describing the problem using standard statistical notation.
In this article, we share some data-driven advice on how to get started on the right foot with an effective and appropriate screening process. Article by Adam Azzam. Originally posted on Open Data Science (ODSC). Length: Highly Variable. Thanks to April Minsky, Holly Szafarek, and Geneviève Smith for feedback on drafts.
Below is a list of topics, answers and articles in support of a recent Tweet Chat in which I was the guest. I have included the topics of discussion, some of my answers and a list of articles in support of the week’s topic. Also, here is an article about 1 0 digital transformation influencers that will change your world.
This article covers causal relationships and includes a chapter excerpt from the book Machine Learning in Production: Developing and Optimizing Data Science Workflows and Applications by Andrew Kelleher and Adam Kelleher. As data science work is experimental and probabilistic in nature, data scientists are often faced with making inferences.
LLMs like ChatGPT are trained on massive amounts of text data, allowing them to recognize patterns and statistical relationships within language. It analyzes historical data and news articles, confirming a possible market correction. NLP techniques help them parse the nuances of human language, including grammar, syntax and context.
How can he make it easy to see statistics, and do calculations, on discovered commonalities, across structured and unstructured data? An integrated unstructured data match engine to find similar documents, reports, articles, and patents, using natural language and/or in combination with SQL.
However, there is a lot more to know about DataOps, as it has its own definition, principles, benefits, and applications in real-life companies today – which we will cover in this article! Technical environments and IDEs must be disposable so that experimental costs can be kept to a minimum. What Is DataOps? Simplicity.
In this article, we turn our attention to the process itself: how do you bring a product to market? Without clarity in metrics, it’s impossible to do meaningful experimentation. Experimentation should show you how your customers use your site, and whether a recommendation engine would help the business. Identifying the problem.
Note These three particular words are called articles , or determiners. Although it’s not perfect, [Note: These are statistical approximations, of course!] We waved our finger in the air to select 64, so some experimentation and optimization are warranted at your end if you feel like it. Example 11.6 place an LSTM() layer.
One of the most fundamental tenets of statistical methods in the last century has focused on correlation to determine causation. The quantitative models that make ML-enhanced analytics possible analyze business issues through statistical, mathematical and computational techniques.
Since you're reading a blog on advanced analytics, I'm going to assume that you have been exposed to the magical and amazing awesomeness of experimentation and testing. And yet, chances are you really don’t know anyone directly who uses experimentation as a part of their regular business practice. Wah wah wah waaah.
" + Strategic Analysis Articles. Tactical Analysis Articles. Blogging Experience Articles. + Book Articles. Misc Articles. In each section the listing is from the latest article to the earliest. " Strategic Analysis Articles. Tactical Analysis Articles. How do I crush tough problems?
The book focuses on randomised controlled trials and well-defined interventions as the basis of causal inference from both experimental and observational data. Hence, the book is full of practical examples. A call for less casual causal inferences.
Paco Nathan’s latest article features several emerging threads adjacent to model interpretability. I’ve been out themespotting and this month’s article features several emerging threads adjacent to the interpretability of machine learning models. Use of influence functions goes back to the 1970s in robust statistics.
This article provides an excerpt of “Tuning Hyperparameters and Pipelines” from the book, Machine Learning with Python for Everyone by Mark E. Choice and Assessment of Statistical Predictions by Stone. Introduction. A Survey of Cross-Validation Procedures for Model Selection by Arlot and Celisse. Cross-Validatory.
In this article, I will discuss the construction of the AIgent, from data collection to model assembly. The most powerful approach for the first task is to use a ‘language model’ (LM), i.e. a statistical model of natural language. Ultimately this will mean a more streamlined, inclusive, and personal publishing industry.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

































Let's personalize your content