This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. Introduction For data scientists and machine learning engineers, developing and testing machine learning models may take a lot of time. For instance, you would need to write a few lines of code, wait for each model to run, and then go on to […].
Introduction With the advancements in Artificial Intelligence, developing and deploying large language model (LLM) applications has become increasingly complex and demanding. LangSmith is a new cutting-edge DevOps platform designed to develop, collaborate, test, deploy, and monitor LLM applications.
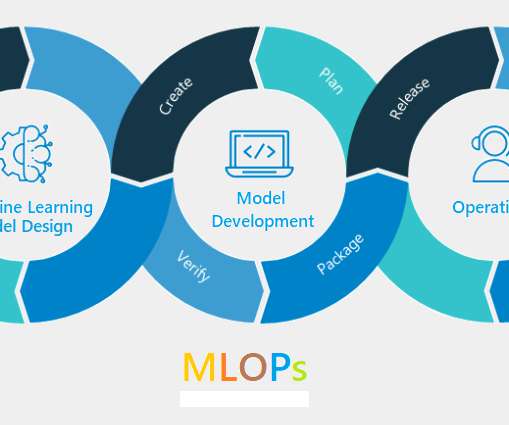
This article was published as a part of the Data Science Blogathon. Introduction This article is part of blog series on Machine Learning Operations(MLOps). In the previous articles, we have gone through the introduction, MLOps pipeline, model training, modeltesting, model packaging, and model registering.
This article was published as a part of the Data Science Blogathon. The post A brief introduction to Multilevel Modelling appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon Introduction With ignite, you can write loops to train the network in just a few lines, add standard metrics calculation out of the box, save the model, etc. The post Training and Testing Neural Networks on PyTorch using Ignite appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. The Model development process undergoes multiple iterations and finally, a model which has acceptable performance metrics on test data is taken to the production […].
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Logistic Regression, a statistical model is a very popular and. The post 20+ Questions to Test your Skills on Logistic Regression appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon Dear readers, In this blog, let’s build our own custom CNN(Convolutional Neural Network) model all from scratch by training and testing it with our custom image dataset.
This article was published as a part of the Data Science Blogathon. A team at Google Brain developed Transformers in 2017, and they are now replacing RNN models like long short-term memory(LSTM) as the model of choice for NLP […].
ArticleVideos This article was published as a part of the Data Science Blogathon. Introduction The main objectives of a model validation include the testing. The post Validation of Classification Model appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. First, you build software, test it for possible faults, and finally deploy it for the end user’s accessibility. The post Automate Model Deployment with GitHub Actions and AWS appeared first on Analytics Vidhya. The same can be applied to […].
Introduction Hallucination in large language models (LLMs) refers to the generation of information that is factually incorrect, misleading, or fabricated. This article explores the concept of hallucination in LLMs, its causes, implications, and potential solutions.
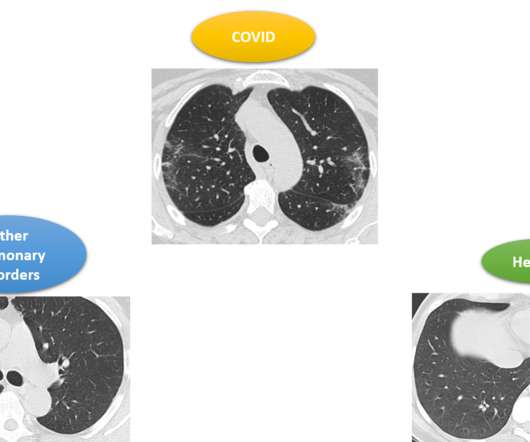
This article was published as a part of the Data Science Blogathon. Overview In this article, we will be discussing the face detection process using the Dlib HOG detection algorithm. Though in this article we will not only test the frontal face but also different angles of the image and see where our model will perform […].
This article was published as a part of the Data Science Blogathon. Background on Flower Classification Model Deep learning models, especially CNN (Convolutional Neural Networks), are implemented to classify different objects with the help of labeled images. For example, a […].
This article was published as a part of the Data Science Blogathon. Source: Wikipedia In this article, we shall provide some background on how multilingual multi-speaker models work and test an Indic TTS model that supports 9 languages and 17 speakers (Hindi, Malayalam, Manipuri, Bengali, Rajasthani, Tamil, Telugu, Gujarati, Kannada).
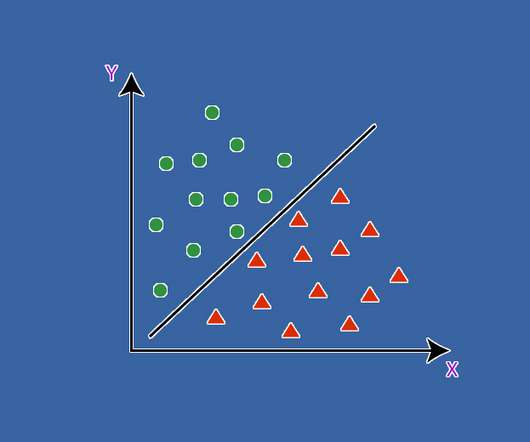
This article was published as a part of the Data Science Blogathon Introduction Instance-based learning is an important aspect of supervised machine learning. The modus operandi of this algorithm is that the training examples are being stored and when the test […].
This article was published as a part of the Data Science Blogathon. Introduction In order to build machine learning models that are highly generalizable to a wide range of test conditions, training models with high-quality data is essential.
This article was published as a part of the Data Science Blogathon. Loading Data Into Big Query Training the model Evaluating the ModelTesting the model Summary Shutting down the […]. Table of Contents Introduction Machine Learning Pipeline Data Preprocessing Flow of pipeline 1.
Not least is the broadening realization that ML models can fail. And that’s why model debugging, the art and science of understanding and fixing problems in ML models, is so critical to the future of ML. Because all ML models make mistakes, everyone who cares about ML should also care about model debugging. [1]
This is article was published as a part of the Data Science Blogathon. In the model-building phase of any supervised machine learning project, we train a model with the aim to learn the optimal values for all the weights and biases from labeled examples. If we use the same labeled examples for testing our model […].
Between vacation, end-of-year projects, the coming holidays, and other hysteria, I haven’t come up with an article this month. No, but honestly, if a human summarized my articles, I’d probably find a few things to complain about. Models using computers Anthropic’s computer use API is now available in beta. Are we virtual yet?
Weve seen this across dozens of companies, and the teams that break out of this trap all adopt some version of Evaluation-Driven Development (EDD), where testing, monitoring, and evaluation drive every decision from the start. In this article, were going to share an emerging SDLC for LLM applications that can help you escape POC Purgatory.
This article was published as a part of the Data Science Blogathon. What is a Statistical Model? “Modeling is an art, as well as. The post All about Statistical Modeling appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction When training a machine learning model, the model can be easily overfitted or under fitted. To avoid this, we use regularization in machine learning to properly fit the model to our test set.
This article was published as a part of the Data Science Blogathon Introduction: OVERFITTING! We do not even spend a single day without encountering this situation and then try different options to get the correct accuracy of the model on the test dataset.
A few years ago, we started publishing articles (see “Related resources” at the end of this post) on the challenges facing data teams as they start taking on more machine learning (ML) projects. We are still in the early days for tools supporting teams developing machine learning models. Model governance.
Introduction This article introduces the ReAct pattern for improved capabilities and demonstrates how to create AI agents from scratch. It covers testing, debugging, and optimizing AI agents in addition to tools, libraries, environment setup, and implementation.
In this article, we want to dig deeper into the fundamentals of machine learning as an engineering discipline and outline answers to key questions: Why does ML need special treatment in the first place? Not only is data larger, but models—deep learning models in particular—are much larger than before. Why did something break?
There’s a lot of excitement about how the GPT models and their successors will change programming. Many of the prompts are about testing: ChatGPT is instructed to generate tests for each function that it generates. At least in theory, test driven development (TDD) is widely practiced among professional programmers.
From obscurity to ubiquity, the rise of large language models (LLMs) is a testament to rapid technological advancement. Just a few short years ago, models like GPT-1 (2018) and GPT-2 (2019) barely registered a blip on anyone’s tech radar. In our real-world case study, we needed a system that would create test data.
Kevlin Henney and I were riffing on some ideas about GitHub Copilot , the tool for automatically generating code base on GPT-3’s language model, trained on the body of code that’s in GitHub. This article poses some questions and (perhaps) some answers, without trying to present any conclusions. Some of them are awful.
In our previous article, What You Need to Know About Product Management for AI , we discussed the need for an AI Product Manager. In this article, we shift our focus to the AI Product Manager’s skill set, as it is applied to day to day work in the design, development, and maintenance of AI products.
That’s what beta tests are for. Large language models like ChatGPT and Google’s LaMDA aren’t designed to give correct results. The ability of these models to “make up” stuff is interesting, and as I’ve suggested elsewhere , might give us a glimpse of artificial imagination.
This article was published as a part of the Data Science Blogathon Introduction to Statistics Statistics is a type of mathematical analysis that employs quantified models and representations to analyse a set of experimental data or real-world studies. Data processing is […].
While generative AI has been around for several years , the arrival of ChatGPT (a conversational AI tool for all business occasions, built and trained from large language models) has been like a brilliant torch brought into a dark room, illuminating many previously unseen opportunities. So, if you have 1 trillion data points (g.,
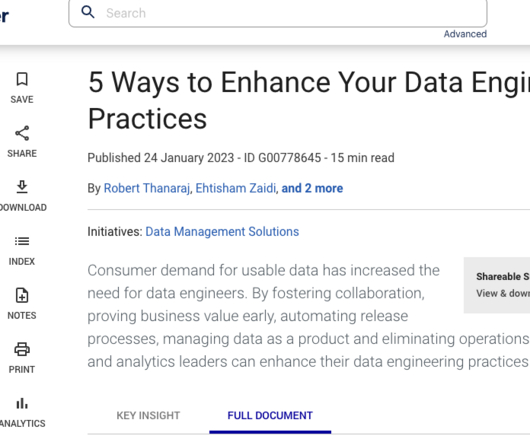
On 24 January 2023, Gartner released the article “ 5 Ways to Enhance Your Data Engineering Practices.” Release New Data Engineering Work Often With Low Risk: “Testing and release processes are heavily manual tasks… automate these processes.” And automate any manual steps in deployment or testing with scripted automation tools.
The purpose of this article is to provide a model to conduct a self-assessment of your organization’s data environment when preparing to build your Data Governance program. Take the […].
Our previous articles in this series introduce our own take on AI product management , discuss the skills that AI product managers need , and detail how to bring an AI product to market. In Bringing an AI Product to Market , we distinguished the debugging phase of product development from pre-deployment evaluation and testing.
It also generated a short program that implemented the widely used Miller-Rabin primality test. OpenAI recently opened their long-awaited Plugins feature to users of ChatGPT Plus (the paid version) using the GPT-4 model. Specifically, I was compelled to re-try my prime test. I had to try this!
Introduction This article uses to predict student performance. For many applications, including online customer service, marketing, and finance, the stock price is a crucial challenge.
In December, Springer published an insightful article about the value of deep learning for VPNs. The article “Deep learning-based real-time VPN encrypted traffic identification methods” delves into the use of machine learning to improve encryption models. It is also used for testing more effectively. What is VPN.
DeepMind’s new model, Gato, has sparked a debate on whether artificial general intelligence (AGI) is nearer–almost at hand–just a matter of scale. Gato is a model that can solve multiple unrelated problems: it can play a large number of different games, label images, chat, operate a robot, and more. If we had AGI, how would we know it?
This article reflects some of what Ive learned. The hype around large language models (LLMs) is undeniable. Think about it: LLMs like GPT-3 are incredibly complex deep learning models trained on massive datasets. Even basic predictive modeling can be done with lightweight machine learning in Python or R.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content