This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With franchise leagues like IPL and BBL, teams rely on statisticalmodels and tools for competitive edge. This article explores how data analytics optimizes strategies by leveraging player performances and opposition weaknesses. Python programming predicts player performances, aiding team selections and game tactics.
This article was published as a part of the Data Science Blogathon. Machine Learning is the method of teaching computer programs to do a specific task accurately (essentially a prediction) by training a predictivemodel using various statistical algorithms leveraging data. Source: [link] For […].
This article was published as a part of the Data Science Blogathon. Introduction Feature analysis is an important step in building any predictivemodel. In this article, we will look into a very simple feature analysis technique that can be used in cases such as […].
This article was published as a part of the Data Science Blogathon. Introduction Machine learning is about building a predictivemodel using historical data. The post Quick Guide to Evaluation Metrics for Supervised and Unsupervised Machine Learning appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the Data Science Blogathon. Introduction Some time back, I was making the predictivemodel. The post STANDARDIZED VS UNSTANDARDIZED REGRESSION COEFFICIENT appeared first on Analytics Vidhya.
This article reflects some of what Ive learned. The hype around large language models (LLMs) is undeniable. Even basic predictivemodeling can be done with lightweight machine learning in Python or R. In life sciences, simple statistical software can analyze patient data. You get the picture.
Moreover, the domain knowledge, which often is not encoded in the data (nor fully documented), is an integral part of this data (see this article from Forbes). In this post, we shed some light on various efforts toward generating data for machine learning (ML) models. See this article on data integration status for details.
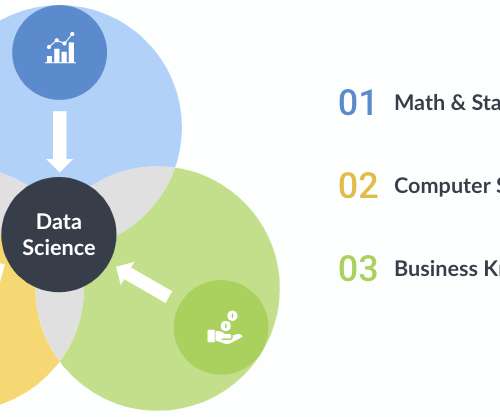
A data scientist must be skilled in many arts: math and statistics, computer science, and domain knowledge. Statistics and programming go hand in hand. Mastering statistical techniques and knowing how to implement them via a programming language are essential building blocks for advanced analytics. Linear regression.
This article answers these questions, based on our combined experience as both a lawyer and a data scientist responding to cybersecurity incidents, crafting legal frameworks to manage the risks of AI, and building sophisticated interpretable models to mitigate risk. Because statistics: Last is the inherently probabilistic nature of ML.
The objective here is to brainstorm on potential security vulnerabilities and defenses in the context of popular, traditional predictivemodeling systems, such as linear and tree-based models trained on static data sets. If an attacker can receive many predictions from your model API or other endpoint (website, app, etc.),
The business can harness the power of statistics and machine learning to uncover those crucial nuggets of information that drive effective decision, and to improve the overall quality of data. This helps you select the predictors that have the greatest impact, making it easier to create an effective predictivemodel.
While some experts try to underline that BA focuses, also, on predictivemodeling and advanced statistics to evaluate what will happen in the future, BI is more focused on the present moment of data, making the decision based on current insights. Your Chance: Want to extract the maximum potential out of your data?
Because all ML models make mistakes, everyone who cares about ML should also care about model debugging. [1] This article is meant to be a short, relatively technical primer on what model debugging is, what you should know about it, and the basics of how to debug models in practice.
Through a marriage of traditional statistics with fast-paced, code-first computer science doctrine and business acumen, data science teams can solve problems with more accuracy and precision than ever before, especially when combined with soft skills in creativity and communication. Math and Statistics Expertise.
Two years later, I published a post on my then-favourite definition of data science , as the intersection between software engineering and statistics. This article is a short summary of my understanding of the definition of data science in 2018. Numerous articles have been published on the meaning of data science in the past six years.
The technology research firm, Gartner has predicted that, ‘predictive and prescriptive analytics will attract 40% of net new enterprise investment in the overall business intelligence and analytics market.’ It is meant to identify crucial relationships and opportunities and risks and help the organization to accurately predict: Growth.
On top of this, pre-existing societal biases are being reinforced and promulgated at previously unheard of scales as we increasingly integrate machine learning models into our daily lives. Put simply, we are reduced to the inputs of an algorithm.
In this article, we will discuss the current state of AI in analytics, as well as the future of this burgeoning industry and how it can be applied to analytics to simplify and clarify results and to make analytics easier for businesses and business users to leverage.
R is a tool built by statisticians mainly for mathematics, statistics, research, and data analysis. We’ll actually do this later in this article. These support a wide array of uses, such as data analysis, manipulation, visualizations, and machine learning (ML) modeling. y_pred=predict(xb, y_val) val-auc=auc(y_pred,y_val).
This article presents a case study of how DataRobot was able to achieve high accuracy and low cost by actually using techniques learned through Data Science Competitions in the process of solving a DataRobot customer’s problem. I thought of the solutions of the top team in a Data Science Competition for LANL Earthquake Prediction.
This article focuses on the Independent Samples T Test technique of Hypothesis testing. The independent sample t-test is a statistical method of hypothesis testing that determines whether there is a statistically significant difference between the means of two independent samples. About Smarten.
Areas making up the data science field include mining, statistics, data analytics, data modeling, machine learning modeling and programming. Ultimately, data science is used in defining new business problems that machine learning techniques and statistical analysis can then help solve.
In this article, we will focus on the identification and exploration of data patterns and the trends that data reveals. In prediction, the objective is to “model” all the components to some trend patterns to the point that the only component that remains unexplained is the random component. Stationary/Stationarity.
This article explains the Karl Pearson Correlation method of analysis, and how it can be applied in business. Correlation is a statistical measure that indicates the extent to which two variables fluctuate together. What is the Karl Pearson Correlation Analytical Technique?
This article describes the Simple Linear Regression method of analysis. Simple Linear Regression is a statistical technique that attempts to explore the relationship between one independent variable (X) and one dependent variable (Y). What is Simple Linear Regression?
In this article, we’ll discuss the challenge organizations face around fraud detection, how machine learning can be used to identify and spot anomalies that the human eye might not catch. In contrast, the decision tree classifies observations based on attribute splits learned from the statistical properties of the training data.
This article describes chi square test of association and hypothesis testing. It is used to determine whether there is a statistically significant association between the two categorical variables. What is the Chi Square Test of Association Method of Hypothesis Testing?
This article discusses the Paired Sample T Test method of hypothesis testing and analysis. At 95% confidence level (5% chance of error): As p-value = 0.041 which is less than 0.05, there is a statistically significant difference between means of pre and post sample values. What is the Paired Sample T Test?
This article describes the analytical technique of multiple linear regression. Multiple Linear Regression is a statistical technique that is designed to explore the relationship between two or more variables (X, and Y). What is Multiple Linear Regression Analysis?
This article looks at the ARIMAX Forecasting method of analysis and how it can be used for business analysis. An Autoregressive Integrated Moving Average with Explanatory Variable (ARIMAX) model can be viewed as a multiple regression model with one or more autoregressive (AR) terms and/or one or more moving average (MA) terms.
This article describes the Spearman’s Rank Correlation and how it is used for enterprise analysis. Correlation is a statistical measure that indicates the extent to which two variables fluctuate together A positive correlation indicates the extent to which those variables increase or decrease in parallel.
This article provides a brief explanation of the ARIMA method of analytical forecasting. Autoregressive Integrated Moving Average (ARIMA) predicts future values of a time series using a linear combination of its past values and a series of errors. ’ The ARIMA model is suggested for short term forecasting.
This article discusses the analytical technique known as Sampling and provides a brief explanation of two types of sampling analysis, and how each of these methods is applied. What is Sampling Analysis? A random sample from each of these subgroups is taken in proportion to the subgroup size relative to the population size.
Diving into examples of building and deploying ML models at The New York Times including the descriptive topic modeling-oriented Readerscope (audience insights engine), a predictionmodel regarding who was likely to subscribe/cancel their subscription, as well as prescriptive example via recommendations of highly curated editorial content.
This article summarizes our recent article series on the definition, meaning and use of the various algorithms and analytical methods and techniques used in predictive analytics for business users, and in augmented data preparation and augmented data discovery tools. Use Case(s): Weather Forecasting, Fraud Analysis and more.
This article presents a brief explanation of Outliers, and how this type of analysis is used. All of these tools are designed for business users with average skills and require no special skills or knowledge of statistical analysis or support from IT or data scientists. What is Outlier Analysis?
This article discusses the analytical method of Hierarchical Clustering and how it can be used within an organization for analytical purposes. All of these tools are designed for business users with average skills and require no special skills or knowledge of statistical analysis or support from IT or data scientists.
This article provides a brief explanation of the KMeans Clustering algorithm. Smarten Augmented Analytics tools include plug n’ play predictive analytics , assisted predictivemodeling , smart data visualization , self-serve data preparation and clickless analytics for search analytics with natural language processing (NLP).
This article provides a brief definition of the multinomial-logistic regression classification algorithm and its uses and benefits. All of these tools are designed for business users with average skills and require no special skills or knowledge of statistical analysis or support from IT or data scientists.
This article provides a brief explanation of the FP Growth technique of Frequent Pattern Mining. All of these tools are designed for business users with average skills and require no special skills or knowledge of statistical analysis or support from IT or data scientists. What is the FP Growth Algorithm?
In this article, we will discuss the Binary Logistic Regression Classification method of analysis, and how it can be used in business. All of these tools are designed for business users with average skills and require no special skills or knowledge of statistical analysis or support from IT or data scientists.
This article provides a brief explanation of the SVM Classification method of analytics. All of these tools are designed for business users with average skills and require no special skills or knowledge of statistical analysis or support from IT or data scientists. What is SVM Classification Analysis?
This article provides insight on the mindset, approach, and tools to consider when solving a real-world ML problem. As a result, there has been a recent explosion in individual statistics that try to measure a player’s impact. 05) in predicting changes in attendance. The lower the RMSE, the better the prediction.
In this article, we will discuss the KNN Classification method of analysis. Smarten Augmented Analytics tools include plug n’ play predictive analytics , assisted predictivemodeling , smart data visualization , self-serve data preparation and clickless analytics for search analytics with natural language processing (NLP).
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content