This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Managing metadata across tools and teams is a growing challenge for organizations building modern data and AI platforms. As data volumes grow and generative AI becomes more central to business strategy, teams need a consistent way to define, discover, and govern their datasets, features, and models.
Amazon Athena provides interactive analytics service for analyzing the data in Amazon Simple Storage Service (Amazon S3). Amazon Redshift is used to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes. Table metadata is fetched from AWS Glue.
The landscape of bigdata management has been transformed by the rising popularity of open table formats such as Apache Iceberg, Apache Hudi, and Linux Foundation Delta Lake. These formats, designed to address the limitations of traditional data storage systems, have become essential in modern data architectures.
How RFS works OpenSearch and Elasticsearch snapshots are a directory tree that contains both data and metadata. The raw data for a given shard is stored in its corresponding shard sub-directory as a collection of Lucene files, which OpenSearch and Elasticsearch lightly obfuscates. source cluster containing 5 TiB (3.9
Onboard key data products – The team identified the key data products that enabled these two use cases and aligned to onboard them into the data solution. These data products belonged to data domains such as production, finance, and logistics. It highlights the guardrails that enable ease of access to quality data.
To achieve this, they aimed to break down data silos and centralize data from various business units and countries into the BMW Cloud Data Hub (CDH). Consumer accounts : Used by data consumers to implement use cases insights and build applications tailored to their business needs.
We have enhanced data sharing performance with improved metadata handling, resulting in data sharing first query execution that is up to four times faster when the data sharing producers data is being updated. Industry-leading price-performance: Amazon Redshift launches RA3.large
Open table formats are emerging in the rapidly evolving domain of bigdata management, fundamentally altering the landscape of data storage and analysis. These are useful for flexible data lifecycle management. An Iceberg table’s metadata stores a history of snapshots, which are updated with each transaction.
SageMaker brings together widely adopted AWS ML and analytics capabilities—virtually all of the components you need for data exploration, preparation, and integration; petabyte-scale bigdata processing; fast SQL analytics; model development and training; governance; and generative AI development.
After you create the asset, you can add glossaries or metadata forms, but its not necessary for this post. You can publish the data asset so its now discoverable within the Amazon DataZone portal. Create it as a JSON file on your workstation (for this post, we call it blog-sub-target.json ). Enter a name for the asset.
This approach simplifies your data journey and helps you meet your security requirements. The SageMaker Lakehouse data connection testing capability boosts your confidence in established connections. About the Authors Chiho Sugimoto is a Cloud Support Engineer on the AWS BigData Support team.
Run the following commands: export PROJ_NAME=lfappblog aws s3 cp s3://aws-blogs-artifacts-public/BDB-3934/schema.graphql ~/${PROJ_NAME}/amplify/backend/api/${PROJ_NAME}/schema.graphql In the s chema.graphql file, you can see that the lf-app-lambda-engine function is set as the data source for the GraphQL queries.
Organizations commonly choose Apache Avro as their data serialization format for IoT data due to its compact binary format, built-in schema evolution support, and compatibility with bigdata processing frameworks. The schema literal serves as a form of metadata, providing a clear description of your data structure.
Business analysts enhance the data with business metadata/glossaries and publish the same as data assets or data products. The data security officer sets permissions in Amazon DataZone to allow users to access the data portal. Amazon Athena is used to query, and explore the data.
This blog post will explore how zero-ETL capabilities combined with its new application connectors are transforming the way businesses integrate and analyze their data from popular platforms such as ServiceNow, Salesforce, Zendesk, SAP and others. The data is also registered in the Glue Data Catalog , a metadata repository.
Data lakes were originally designed to store large volumes of raw, unstructured, or semi-structured data at a low cost, primarily serving bigdata and analytics use cases. By using features like Icebergs compaction, OTFs streamline maintenance, making it straightforward to manage object and metadata versioning at scale.
Under Data sources , select Amazon S3. Select the Amazon S3 source node and enter the following values: S3 URI: s3://aws-bigdata-blog/generated_synthetic_reviews/data/product_category=Apparel/ Format: Parquet Select Update node. About the authors Chiho Sugimoto is a Cloud Support Engineer on the AWS BigData Support team.
You can use sample data to extract information from the specific category, update partition metadata, and display query results in the notebook using Python code. To use the sample data provided in this blog post, your domain should be in us-east-1 region. Choose the plus sign, and under Data sources , choose Amazon S3.
Publish data assets – As the data producer from the retail team, you must ingest individual data assets into Amazon DataZone. For this use case, create a data source and import the technical metadata of four data assets— customers , order_items , orders , products , reviews , and shipments —from AWS Glue Data Catalog.
This feature will be discussed in detail later in this blog. The raw metadata is assumed to be not more than 100Gb. However, the recently introduced disk-based vector search feature eliminates the need for external vector quantization. For detailed implementation steps, see to the OpenSearch documentation.
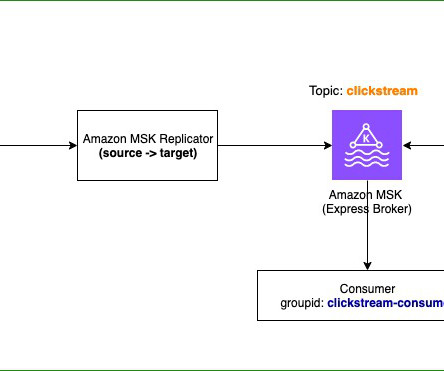
However, you can use Amazon MSK Replicator to copy all data and metadata from your existing MSK cluster to a new cluster comprising of Express brokers. MSK Replicator offers a built-in replication capability to seamlessly replicate data from one cluster to another. It doesnt explicitly copy the write ACLs except the deny ones.
Icebergs branching feature Iceberg offers a branching feature for data lifecycle management, which is particularly useful for efficiently implementing the WAP pattern. The metadata of an Iceberg table stores a history of snapshots. snappy.parquet s3:// /src-data/current/ !aws He works based in Tokyo, Japan.
Many enterprises have heterogeneous data platforms and technology stacks across different business units or data domains. For decades, they have been struggling with scale, speed, and correctness required to derive timely, meaningful, and actionable insights from vast and diverse bigdata environments.
Data processing and SQL analytics Analyze, prepare, and integrate data for analytics and AI using Amazon Athena, Amazon EMR, AWS Glue, and Amazon Redshift. Data and AI governance Publish your data products to the catalog with glossaries and metadata forms. BigData Architect. option("sep", ",").load("s3://aws-blogs-artifacts-public/artifacts/BDB-4798/data/venue.csv")
Each product record contains rich metadata, including title, detailed description, category, color, and price. For more insights, best practices and architectures, and industry trends, refer to Amazon OpenSearch Service blog posts and hands-on workshops at AWS Workshops. For an exhaustive list, refer to Search features.
Are you incurring significant cross Availability Zone traffic costs when running an Apache Kafka client in containerized environments on Amazon Elastic Kubernetes Service (Amazon EKS) that consume data from Amazon Managed Streaming for Apache Kafka (Amazon MSK) topics? An Apache Kafka client consumer will register to read against a topic.
More details related to baggage operational database modernization can be found at Enhance the reliability of airlines’ mission-critical baggage handling using Amazon DynamoDB in the AWS Database Blog. Amazon QuickSight can be configured to use Amazon Athena to read the data catalog.
For example, radiology requires high storage capacity and bandwidth for large medical imaging files, along with specialized indexing for metadata searches. For details, see this blog post: Workload management in OpenSearch-based multi-tenant centralized logging platforms. Transition to cold storage for years 3–7.
Traditionally, answering this question would involve multiple data exports, complex extract, transform, and load (ETL) processes, and careful data synchronization across systems. The table metadata is managed by Data Catalog. You can use SageMaker Lakehouse to unify the data across different data sources.
When an organization’s data governance and metadata management programs work in harmony, then everything is easier. Data governance is a complex but critical practice. There’s always more data to handle, much of it unstructured; more data sources, like IoT, more points of integration, and more regulatory compliance requirements.
In the era of bigdata, data lakes have emerged as a cornerstone for storing vast amounts of raw data in its native format. They support structured, semi-structured, and unstructured data, offering a flexible and scalable environment for data ingestion from multiple sources.
What Is Metadata? Metadata is information about data. A clothing catalog or dictionary are both examples of metadata repositories. Indeed, a popular online catalog, like Amazon, offers rich metadata around products to guide shoppers: ratings, reviews, and product details are all examples of metadata.
Metadata management is key to wringing all the value possible from data assets. However, most organizations don’t use all the data at their disposal to reach deeper conclusions about how to drive revenue, achieve regulatory compliance or accomplish other strategic objectives. What Is Metadata? Harvest data.
Untapped data, if mined, represents tremendous potential for your organization. While there has been a lot of talk about bigdata over the years, the real hero in unlocking the value of enterprise data is metadata , or the data about the data. Metadata Is the Heart of Data Intelligence.
We’re excited to announce a new feature in Amazon DataZone that offers enhanced metadata governance for your subscription approval process. With this update, domain owners can define and enforce metadata requirements for data consumers when they request access to data assets.
Metadata is an important part of data governance, and as a result, most nascent data governance programs are rife with project plans for assessing and documenting metadata. But in many scenarios, it seems that the underlying driver of metadata collection projects is that it’s just something you do for data governance.
If you include the title of this blog, you were just presented with 13 examples of heteronyms in the preceding paragraphs. This is accomplished through tags, annotations, and metadata (TAM). Smart content includes labeled (tagged, annotated) metadata (TAM). What you have just experienced is a plethora of heteronyms.
Aptly named, metadata management is the process in which BI and Analytics teams manage metadata, which is the data that describes other data. In other words, data is the context and metadata is the content. Without metadata, BI teams are unable to understand the data’s full story.
We have identified the top ten sites, videos, or podcasts online that deal with data lineage. Our list of Top 10 Data Lineage Podcasts, Blogs, and Websites To Follow in 2021. Data Engineering Podcast. This podcast centers around data management and investigates a different aspect of this field each week.
There are countless examples of bigdata transforming many different industries. There is no disputing the fact that the collection and analysis of massive amounts of unstructured data has been a huge breakthrough. This is something that you can learn more about in just about any technology blog.
Apache Iceberg is an open table format for very large analytic datasets, which captures metadata information on the state of datasets as they evolve and change over time. Iceberg has become very popular for its support for ACID transactions in data lakes and features like schema and partition evolution, time travel, and rollback.
This blog post is co-written with Hardeep Randhawa and Abhay Kumar from HPE. Each file arrives as a pair with a tail metadata file in CSV format containing the size and name of the file. This metadata file is later used to read source file names during processing into the staging layer.
This is a guest blog post co-written with Sumesh M R from Cargotec and Tero Karttunen from Knowit Finland. They chose AWS Glue as their preferred data integration tool due to its serverless nature, low maintenance, ability to control compute resources in advance, and scale when needed.
When the pandemic first hit, there was some negative impact on bigdata and analytics spending. Digital transformation was accelerated, and budgets for spending on bigdata and analytics increased. Technical metadata is what makes up database schema and table definitions.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content