This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
According to a 2015 whitepaper published in Science Direct , bigdata is one of the most disruptive technologies influencing the field of academia. Now it has become so popular that you can even get data structure assignment help from professionals. BigData Internal Impact. Student Model Based on BigData.
The external data catalog can be AWS Glue Data Catalog, the data catalog that comes with Amazon Athena, or your own Apache Hive metastore. To get the best performance on data lake queries with Redshift, you can use AWS Glue Data Catalog’s column statistics feature to collect statistics on Data Lake tables.
We’ve already discussed how checkpoints, when triggered by the job manager, signal all source operators to snapshot their state, which is then broadcasted as a special record called a checkpoint barrier. Then it broadcasts the barrier downstream. However, it continues to process partitions that are behind the barrier.
Delta lake allows thousands of data to run in parallel, address optimization and partition challenges, faster metadata operations, maintains a transactional log and continuously keeps updating the data. improved data processing in the following ways: Skewed Join Optimization. Optimization.
Internally, Apache Flink uses clever mechanisms to maintain exactly-once state consistency, while also optimizing for throughput and reduced latency. After the barriers from all upstream partitions have arrived, the sub-task takes the snapshot of its state and then broadcasts the barrier downstream.
Suboptimal data distribution – If data distribution is suboptimal, you might notice a large broadcast or redistribution of data across compute nodes when two large tables are joined together. Nested loop joins are the cross-joins without a join condition that result in the Cartesian product of two tables.
It’s your billing system that allows your IPTV/OTT platform to turn a profit, and it’s the source of invaluable user data and statistics. This data includes usage analytics & reports that you can view and analyse in order to optimize your service. Client Reporting.
We have talked extensively about the many industries that have been impacted by bigdata. many of our articles have centered around the role that data analytics and artificial intelligence has played in the financial sector. However, many other industries have also been affected by advances in bigdata technology.
When you use Trino on Amazon EMR or Athena, you get the latest open source community innovations along with proprietary, AWS developed optimizations. and Athena engine version 2, AWS has been developing query plan and engine behavior optimizations that improve query performance on Trino. Starting from Amazon EMR 6.8.0
The stealthy nature of data skew means it can often go undetected because monitoring tools might not flag an uneven distribution as a critical issue, and logs don’t always make it evident. This can help make sure that data with similar characteristics is in the same partition and reduce the size of the largest partition.
During the first-ever virtual broadcast of our annual Data Impact Awards (DIA) ceremony, we had the great pleasure of announcing this year’s finalists and winners. It hosts over 150 bigdata analytics sandboxes across the region with over 200 users utilizing the sandbox for data discovery.
The lesson is about the limitation of optimizing for a local maxima, usually in a silo. I believe this approach optimizes for a local maxima (the media buying bubble) and does not create the necessary incentives to solve for the global maxima (short or long-term business success). I believe this is necessary, but not sufficient.
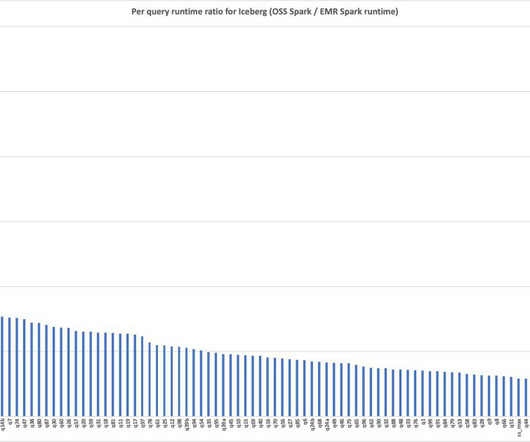
times faster with Amazon EMR runtime for Apache Spark , we detailed some of the optimizations, showing a runtime improvement of 4.5 However, many of the optimizations are geared towards DataSource V1, whereas Iceberg uses Spark DataSource V2. We have added eight new optimizations incrementally since the Amazon EMR 6.15
Bigdata technology has significantly changed the marketing profession over the last few years. One of the biggest changes brought on by bigdata has been in the field of social media marketing. Most savvy marketers recognize the importance of using analytics technology to optimize their strategies to get a higher ROI.
Sreesha Rao, senior manager of IT applications at Niagara Bottling and Seth Dobrin, CDO of IBM Analytics, spoke with Dave Vellante in NYC on the eve of the 13 September taping of the Win with AI digital broadcast about the company’s efforts to save on plastic use by optimizing the settings of its pallet wrappers, machines that wrap an entire pallet (..)
In this article, we will explore various optimizations that can be implemented to help you achieve better performance or plan for scalability. . The existing protocols need to be optimized carefully to achieve improvements. In this upcoming section, we will discuss a few of the possible optimizations.
WiFi-enabled tracking: WiFi-enabled tracking systems use a tag affixed to an asset to broadcast a variety of information about it over a local WiFi network. Enterprise asset management with the IBM Maximo Application Suite helps companies optimize asset performance and extend asset lifespans.
By default, the sink writes in batches to optimize throughput. SQL In Apache Flink SQL, users can provide hints to join queries that can be used to suggest the optimizer to have an effect in the query plan. The DataStream API now supports features like side outputs and broadcast state, and gaps on windowing API have been closed.
Netflix uses AWS cloud services for optimizing almost all of its services. The cloud services provided through AWS help with everything from video transcribing, analytics, data storage and much more. We have talked about the benefits bigdata has brought to VPN technology.
Greater alignment across business units: Optimize management processes according to a variety of factors beyond just the condition of a piece of equipment. Radio frequency identifier tags (RFID): RFID tags broadcast information about the asset they’re attached to using radio-frequency signals and Bluetooth technology.
Today, many mundane but necessary tasks associated with equipment repair and optimization are being turned over to machines thanks to 5G connectivity paired with AI and ML capabilities. Smart factories 5G, along with AI and ML, is poised to help factories become not only smarter but more automated, efficient and resilient.
Unlike other communication channels, social media posts are broadcast to the public. This requires organizations to monitor their channels and use tools that create notifications every time their brand is mentioned. That can turn an individual issue into a much larger corporate reputation issue if not immediately addressed.
Read this blog post to explore how digital twins can help you optimize your asset performance. A sound ALM strategy ensures compliance no matter where data is being stored. RFID tags broadcast a variety of information about an asset in addition to its location, including the temperature and humidity of its environment.
By DAVID ADAMS Since inception, this blog has defined “data science” as inference derived from data too big to fit on a single computer. Thus the ability to manipulate bigdata is essential to our notion of data science. Many significant differences between the two are a consequence of this distinction.
A less-than-optimal transportation infrastructure affects the economy, hastens environmental impact and lowers the overall quality of living. However, stalled cars and harried people waiting for public transportation aren’t just an individual nuisance.
The service allows you to configure clusters with different types of nodes such as data nodes, dedicated cluster manager nodes, and UltraWarm nodes. When you send requests to your OpenSearch Service domain, the request is broadcast to the nodes with shards that will process that request.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content