This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this analyst perspective, Dave Menninger takes a look at datalakes. He explains the term “datalake,” describes common use cases and shares his views on some of the latest market trends. He explores the relationship between data warehouses and datalakes and share some of Ventana Research’s findings on the subject.
Amazon Redshift is a fast, fully managed cloud data warehouse that makes it cost-effective to analyze your data using standard SQL and businessintelligence tools. Customers use datalake tables to achieve cost effective storage and interoperability with other tools.
Databricks is a data engineering and analytics cloud platform built on top of Apache Spark that processes and transforms huge volumes of data and offers data exploration capabilities through machine learning models. The platform supports streaming data, SQL queries, graph processing and machine learning.
Introduction Enterprises here and now catalyze vast quantities of data, which can be a high-end source of businessintelligence and insight when used appropriately. Delta Lake allows businesses to access and break new data down in real time.
Amazon DataZone now launched authentication supports through the Amazon Athena JDBC driver, allowing data users to seamlessly query their subscribed datalake assets via popular businessintelligence (BI) and analytics tools like Tableau, Power BI, Excel, SQL Workbench, DBeaver, and more. Lionel Pulickal is Sr.
A datalake is a centralized repository that you can use to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data and then run different types of analytics for better business insights. They are the same.
Initially, data warehouses were the go-to solution for structured data and analytical workloads but were limited by proprietary storage formats and their inability to handle unstructured data. Eventually, transactional datalakes emerged to add transactional consistency and performance of a data warehouse to the datalake.
A modern data architecture enables companies to ingest virtually any type of data through automated pipelines into a datalake, which provides highly durable and cost-effective object storage at petabyte or exabyte scale.
Since the deluge of bigdata over a decade ago, many organizations have learned to build applications to process and analyze petabytes of data. Datalakes have served as a central repository to store structured and unstructured data at any scale and in various formats.
Amazon Redshift is a fast, fully managed petabyte-scale cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing businessintelligence (BI) tools. Amazon Redshift also supports querying nested data with complex data types such as struct, array, and map.
This amalgamation empowers vendors with authority over a diverse range of workloads by virtue of owning the data. This authority extends across realms such as businessintelligence, data engineering, and machine learning thus limiting the tools and capabilities that can be used. 5 seconds $0.08 8 seconds $0.07
Unified access to your data is provided by Amazon SageMaker Lakehouse , a unified, open, and secure data lakehouse built on Apache Iceberg open standards. The final model provides sales teams with the highest-value opportunities, which they can visualize in a businessintelligence dashboard and take action on immediately.
This led to inefficiencies in data governance and access control. AWS Lake Formation is a service that streamlines and centralizes the datalake creation and management process. The Solution: How BMW CDH solved data duplication The CDH is a company-wide datalake built on Amazon Simple Storage Service (Amazon S3).
With data becoming the driving force behind many industries today, having a modern data architecture is pivotal for organizations to be successful. In this post, we describe Orca’s journey building a transactional datalake using Amazon Simple Storage Service (Amazon S3), Apache Iceberg, and AWS Analytics.
To address the flood of data and the needs of enterprise businesses to store, sort, and analyze that data, a new storage solution has evolved: the datalake. What’s in a DataLake? Data warehouses do a great job of standardizing data from disparate sources for analysis. Taking a Dip.
Talend is a data integration and management software company that offers applications for cloud computing, bigdata integration, application integration, data quality and master data management.
In this post, we show you how EUROGATE uses AWS services, including Amazon DataZone , to make data discoverable by data consumers across different business units so that they can innovate faster. We encourage you to read Amazon DataZone concepts and terminology to become familiar with the terms used in this post.
But the data repository options that have been around for a while tend to fall short in their ability to serve as the foundation for bigdata analytics powered by AI. Traditional data warehouses, for example, support datasets from multiple sources but require a consistent data structure. Meet the data lakehouse.
Traditional on-premises data processing solutions have led to a hugely complex and expensive set of data silos where IT spends more time managing the infrastructure than extracting value from the data.
Previously, Walgreens was attempting to perform that task with its datalake but faced two significant obstacles: cost and time. Those challenges are well-known to many organizations as they have sought to obtain analytical knowledge from their vast amounts of data. Lakehouses redeem the failures of some datalakes.
AWS Glue provides an extensible architecture that enables users with different data processing use cases. A common use case is building datalakes on Amazon Simple Storage Service (Amazon S3) using AWS Glue extract, transform, and load (ETL) jobs.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud data warehouse that makes it simple and cost-effective to analyze your data using standard SQL and your existing businessintelligence (BI) tools. He has worked with building data warehouses and bigdata solutions for over 15+ years.
Although Jira Cloud provides reporting capability, loading this data into a datalake will facilitate enrichment with other businessdata, as well as support the use of businessintelligence (BI) tools and artificial intelligence (AI) and machine learning (ML) applications.
Data analytics on operational data at near-real time is becoming a common need. Due to the exponential growth of data volume, it has become common practice to replace read replicas with datalakes to have better scalability and performance. For more information, see Changing the default settings for your datalake.
Events and many other security data types are stored in Imperva’s Threat Research Multi-Region datalake. Imperva harnesses data to improve their business outcomes. As part of their solution, they are using Amazon QuickSight to unlock insights from their data.
Organizations have been using data virtualization to collect and integrate data from various sources, and in different formats, to create a single source of truth without redundancy or overlap, thus improving and accelerating decision-making giving them a competitive advantage in the market.
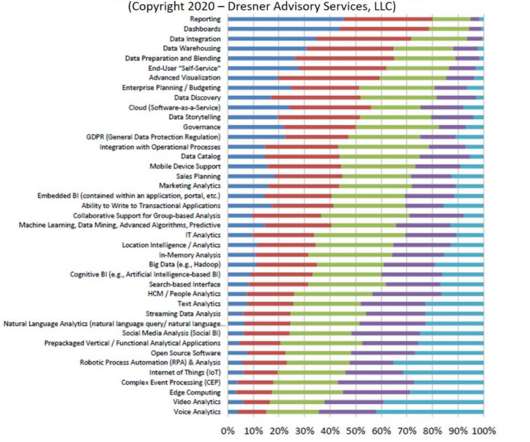
Dresner Advisory Services’ report about self-service businessintelligence uncovered a surprising result. Among all the hot analytics initiatives to choose from (bigdata, IoT, NLP, data storytelling, cognitive BI, GDPR), plain old reporting is what is considered the most important strategic initiative.
Stone called outdated apps a multi-trillion-dollar problem, even after organizations have spent the past decade focused on modernizing their infrastructure to deal with bigdata. This allows for the extraction and integration of data into AI models without overhauling entire platforms, Erolin says.
With this integration, you can now seamlessly query your governed datalake assets in Amazon DataZone using popular businessintelligence (BI) and analytics tools, including partner solutions like Tableau.
Amazon Athena supports the MERGE command on Apache Iceberg tables, which allows you to perform inserts, updates, and deletes in your datalake at scale using familiar SQL statements that are compliant with ACID (Atomic, Consistent, Isolated, Durable).
For a while now, vendors have been advocating that people put their data in a datalake when they put their data in the cloud. The DataLake The idea is that you put your data into a datalake. Then, at a later point in time, the end user analyst can come along and […].
In today’s data-driven world , organizations are constantly seeking efficient ways to process and analyze vast amounts of information across datalakes and warehouses. This post will showcase how this data can also be queried by other data teams using Amazon Athena. Verify that you have Python version 3.7
If you’re used to using SQL Server Analysis Services for businessintelligence, Analysis Services offers that enterprise-grade analytics engine as a cloud service that you can also connect to Power BI. Azure Data Explorer. Azure DataLake Analytics. Microsoft. Azure Analysis Services.
Building a datalake on Amazon Simple Storage Service (Amazon S3) provides numerous benefits for an organization. However, many use cases, like performing change data capture (CDC) from an upstream relational database to an Amazon S3-based datalake, require handling data at a record level.
In the context of comprehensive data governance, Amazon DataZone offers organization-wide data lineage visualization using Amazon Web Services (AWS) services, while dbt provides project-level lineage through model analysis and supports cross-project integration between datalakes and warehouses.
Organizations still struggle with limited data visibility and insufficient insights, which are often caused by a multitude of reasons such as analytic workloads running independently, data spread across multiple data centers, data governance, etc.
His business units had a presence in 180 countries worldwide with geographically-dispersed data warehouses and businessintelligence applications in various locations. Haruto Sakamoto, the Chief Information Officer at a Japanese multinational imaging company, had a few challenges to contend with.
The product data is stored on Amazon Aurora PostgreSQL-Compatible Edition. Their existing businessintelligence (BI) tool runs queries on Athena. Furthermore, they have a data pipeline to perform extract, transform, and load (ETL) jobs when moving data from the Aurora PostgreSQL database cluster to other data stores.
Cloudera customers run some of the biggest datalakes on earth. These lakes power mission critical large scale data analytics, businessintelligence (BI), and machine learning use cases, including enterprise data warehouses. On data warehouses and datalakes.
As organizations process vast amounts of data, maintaining an accurate historical record is crucial. History management in data systems is fundamental for compliance, businessintelligence, data quality, and time-based analysis. Hes passionate about helping customers use Apache Iceberg for their datalakes on AWS.
Cloudera customers run some of the biggest datalakes on earth. These lakes power mission critical large scale data analytics, businessintelligence (BI), and machine learning use cases, including enterprise data warehouses. On data warehouses and datalakes.
Analytics remained one of the key focus areas this year, with significant updates and innovations aimed at helping businesses harness their data more efficiently and accelerate insights. This zero-ETL integration reduces the complexity and operational burden of data replication to let you focus on deriving insights from your data.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content