This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This week on the keynote stages at AWS re:Invent 2024, you heard from Matt Garman, CEO, AWS, and Swami Sivasubramanian, VP of AI and Data, AWS, speak about the next generation of Amazon SageMaker , the center for all of your data, analytics, and AI. The relationship between analytics and AI is rapidly evolving.
Whether youre a data analyst seeking a specific metric or a data steward validating metadata compliance, this update delivers a more precise, governed, and intuitive search experience. Start using this enhanced search capability today and experience the difference it brings to your data discovery journey.
In addition to real-time analytics and visualization, the data needs to be shared for long-term dataanalytics and machine learning applications. From here, the metadata is published to Amazon DataZone by using AWS Glue Data Catalog. This process is shown in the following figure.
The Eightfold Talent Intelligence Platform integrates with Amazon Redshift metadata security to implement visibility of data catalog listing of names of databases, schemas, tables, views, stored procedures, and functions in Amazon Redshift. This post discusses restricting listing of data catalog metadata as per the granted permissions.
Amazon Q generative SQL for Amazon Redshift uses generative AI to analyze user intent, query patterns, and schema metadata to identify common SQL query patterns directly within Amazon Redshift, accelerating the query authoring process for users and reducing the time required to derive actionable data insights.
We’re excited to announce a new feature in Amazon DataZone that offers enhanced metadata governance for your subscription approval process. With this update, domain owners can define and enforce metadata requirements for data consumers when they request access to data assets.
With this approach, you create a new Amazon MWAA environment, migrate your metadata, and manage the transition between environments. To help prevent data duplication or corruption during parallel operation, we recommend implementing idempotent DAGs. Back up your current environment configuration and metadata.
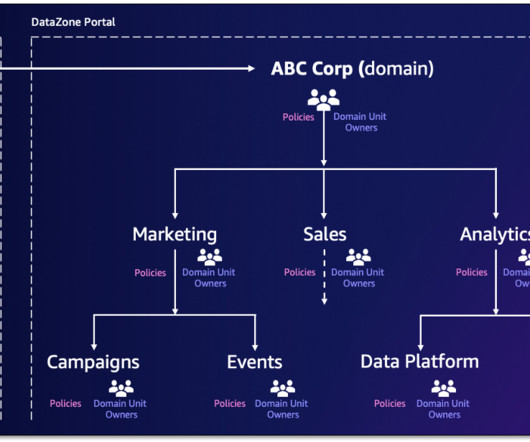
Institutional Data & AI Platform architecture The Institutional Division has implemented a self-service data platform to enable the domain teams to build and manage data products autonomously. The following diagram illustrates the building blocks of the Institutional Data & AI Platform.
The IAM role ARN must be the same for both the OpenSearch Servicer sink definition and the Kinesis Data Streams source definition. You can control what data gets indexed in different indexes using the index definition in the sink.
The following are the key components and steps in the integration process: Zero-ETL extracts and loads the data into Amazon S3 , a highly scalable object storage service. The data is also registered in the Glue Data Catalog , a metadata repository. BigData and ETL Solutions Architect, Amazon MWAA and AWS Glue ETL expert.
Data scientists are analyticaldata experts who use data science to discover insights from massive amounts of structured and unstructured data to help shape or meet specific business needs and goals. Data scientist job description. Semi-structured data falls between the two. Data scientist skills.
Pricing and availability Amazon MWAA pricing dimensions remains unchanged, and you only pay for what you use: The environment class Metadata database storage consumed Metadata database storage pricing remains the same. Over the years, he has helped multiple customers on data platform transformations across industry verticals.
BladeBridge offers a comprehensive suite of tools that automate much of the complex conversion work, allowing organizations to quickly and reliably transition their dataanalytics capabilities to the scalable Amazon Redshift data warehouse. She is passionate about dataanalytics and data science.
We have enhanced data sharing performance with improved metadata handling, resulting in data sharing first query execution that is up to four times faster when the data sharing producers data is being updated. Industry-leading price-performance: Amazon Redshift launches RA3.large
Dataanalytics is the linchpin of digital business strategies in the 21st Century. Sensible companies need to know how to properly utilize dataanalytics to take full advantage of all of their digital resources. The Intersection Between DataAnalytics and Digital Asset Management.
But most important of all, the assumed dormant value in the unstructured data is a question mark, which can only be answered after these sophisticated techniques have been applied. Therefore, there is a need to being able to analyze and extract value from the data economically and flexibly. The solution integrates data in three tiers.
reduces the Amazon DynamoDB cost associated with KCL by optimizing read operations on the DynamoDB table storing metadata. KCL uses DynamoDB to store metadata such as shard-worker mapping and checkpoints. Priyanka Chaudhary is a Senior Solutions Architect and dataanalytics specialist. Other benefits in KCL 3.0
There are countless examples of bigdata transforming many different industries. There is no disputing the fact that the collection and analysis of massive amounts of unstructured data has been a huge breakthrough. We would like to talk about data visualization and its role in the bigdata movement.
Create an Amazon Bedrock knowledge base referencing structured data in Amazon Redshift Amazon Bedrock Knowledge Bases uses Amazon Redshift as the query engine to query your data. It reads metadata from your structured data store to generate SQL queries. Choose your Redshift workgroup. Use the IAM role created earlier.
Each file arrives as a pair with a tail metadata file in CSV format containing the size and name of the file. This metadata file is later used to read source file names during processing into the staging layer. These files follow the same naming pattern, with a daily system-generated timestamp appended to each file name.
In this post, we walk you through the top analytics announcements from re:Invent 2024 and explore how these innovations can help you unlock the full potential of your data. S3 Metadata is designed to automatically capture metadata from objects as they are uploaded into a bucket, and to make that metadata queryable in a read-only table.
They chose AWS Glue as their preferred data integration tool due to its serverless nature, low maintenance, ability to control compute resources in advance, and scale when needed. To share the datasets, they needed a way to share access to the data and access to catalog metadata in the form of tables and views.
In this blog post, we dive into different data aspects and how Cloudinary breaks the two concerns of vendor locking and cost efficient dataanalytics by using Apache Iceberg, Amazon Simple Storage Service (Amazon S3 ), Amazon Athena , Amazon EMR , and AWS Glue. This concept makes Iceberg extremely versatile. SparkActions.get().expireSnapshots(iceTable).expireOlderThan(TimeUnit.DAYS.toMillis(7)).execute()
Working with massive structured and unstructured data sets can turn out to be complicated. It’s obvious that you’ll want to use bigdata, but it’s not so obvious how you’re going to work with it. So, let’s have a close look at some of the best strategies to work with large data sets. It’s a good idea to record metadata.
Benchmark setup In our testing, we used the 3 TB dataset stored in Amazon S3 in compressed Parquet format and metadata for databases and tables is stored in the AWS Glue Data Catalog. This benchmark uses unmodified TPC-DS data schema and table relationships. He has been focusing in the bigdataanalytics space since 2014.
You can use its built-in transformations, recipes, as well as integrations with the AWS Glue Data Catalog and Amazon Simple Storage Service (Amazon S3) to preprocess the data in your landing zone, clean it up, and send it downstream for analytical processing. For Matching conditions , choose Match all conditions.
Apache Iceberg is an open table format for very large analytic datasets, which captures metadata information on the state of datasets as they evolve and change over time. Iceberg has become very popular for its support for ACID transactions in data lakes and features like schema and partition evolution, time travel, and rollback.
Applying artificial intelligence (AI) to dataanalytics for deeper, better insights and automation is a growing enterprise IT priority. But the data repository options that have been around for a while tend to fall short in their ability to serve as the foundation for bigdataanalytics powered by AI.
In this post, we discuss ways to modernize your legacy, on-premises, real-time analytics architecture to build serverless dataanalytics solutions on AWS using Amazon Managed Service for Apache Flink. It shows a call center streaming data source that sends the latest call center feed in every 15 seconds.
The post will include details on how to perform read/write data operations against Amazon S3 tables with AWS Lake Formation managing metadata and underlying data access using temporary credential vending. Analytics Specialist Solutions Architect focused on bigdata and analytics and AI/ML with Amazon Web Services.
Despite these capabilities, data lakes are not databases, and object storage does not provide support for ACID processing semantics, which you may require to effectively optimize and manage your data at scale across hundreds or thousands of users using a multitude of different technologies.
We recently talked about the benefits of using bigdata in marketing. We even discussed some tools that leverage bigdata to get more value out of marketing strategies. These are all great reasons to use bigdata in marketing. But for accurate modeling, you need lots of reliable data. Lead Enrichment.
The FinAuto team built AWS Cloud Development Kit (AWS CDK), AWS CloudFormation , and API tools to maintain a metadata store that ingests from domain owner catalogs into the global catalog. This global catalog captures new or updated partitions from the data producer AWS Glue Data Catalogs.
According to Gartner, 60% of all the bigdata projects fail and according to Capgemini 70% of the bigdata projects are not profitable. There can only be one conclusion, bigdata projects are hard! There is not one specific.
AWS Glue Data Catalog stores information as metadata tables, where each table specifies a single data store. The AWS Glue crawler writes metadata to the Data Catalog by classifying the data to determine the format, schema, and associated properties of the data. BigData Architect.
Because a CDC file can contain data for multiple tables, the job loops over the tables in a file and loads the table metadata from the source table ( RDS column names). If the CDC operation is INSERT or UPDATE, the job merges the data into the Iceberg table.
Advancement in bigdata technology has made the world of business even more competitive. The proper use of business intelligence and analyticaldata is what drives big brands in a competitive market. This high-end data visualization makes data exploration more accessible to end-users.
Many customers run bigdata workloads such as extract, transform, and load (ETL) on Apache Hive to create a data warehouse on Hadoop. We split the solution into two primary components: generating Spark job metadata and running the SQL on Amazon EMR. The script generates a metadata JSON file for each step.
Bigdata is cool again. As the company who taught the world the value of bigdata, we always knew it would be. But this is not your grandfather’s bigdata. It has evolved into something new – hybrid data. The future is hybrid data, embrace it.
Additionally, authorization policies can be configured for a domain unit permitting actions such as who can create projects, metadata forms, and glossaries within their domain units. Similarly, authorization policies can help organizations govern the management of organizational domains, collaboration, and metadata.
Running Apache Airflow at scale puts proportionally greater load on the Airflow metadata database, sometimes leading to CPU and memory issues on the underlying Amazon Relational Database Service (Amazon RDS) cluster. A resource-starved metadata database may lead to dropped connections from your workers, failing tasks prematurely.
In this post, we delve into the key aspects of using Amazon EMR for modern data management, covering topics such as data governance, data mesh deployment, and streamlined data discovery. Organizations have multiple Hive data warehouses across EMR clusters, where the metadata gets generated.
The program must introduce and support standardization of enterprise data. Programs must support proactive and reactive change management activities for reference data values and the structure/use of master data and metadata.
Apache Flink is a scalable, reliable, and efficient data processing framework that handles real-time streaming and batch workloads (but is most commonly used for real-time streaming). It’s the preferred choice to run bigdata workloads because it helps improve throughput and optimize Amazon EC2 spend.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content