This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
BladeBridge offers a comprehensive suite of tools that automate much of the complex conversion work, allowing organizations to quickly and reliably transition their data analytics capabilities to the scalable Amazon Redshift datawarehouse. times better price performance than other cloud datawarehouses.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud datawarehouse that makes it simple and cost-effective to analyze your data using standard SQL and your existing business intelligence (BI) tools. Data ingestion is the process of getting data to Amazon Redshift.
This enables you to extract insights from your data without the complexity of managing infrastructure. dbt has emerged as a leading framework, allowing data teams to transform and manage data pipelines effectively. This feature reduces the amount of data scanned by Athena, resulting in faster query performance and lower costs.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis.
Amazon Redshift is a fast, fully managed cloud datawarehouse that makes it cost-effective to analyze your data using standard SQL and business intelligence tools. However, if you want to test the examples using sample data, download the sample data. Amazon Redshift delivers price performance right out of the box.
Data lakes and datawarehouses are two of the most important data storage and management technologies in a modern dataarchitecture. Data lakes store all of an organization’s data, regardless of its format or structure. Delta Lake doesn’t have a specific concept for incremental queries.
The landscape of bigdata management has been transformed by the rising popularity of open table formats such as Apache Iceberg, Apache Hudi, and Linux Foundation Delta Lake. These formats, designed to address the limitations of traditional data storage systems, have become essential in modern dataarchitectures.
SageMaker brings together widely adopted AWS ML and analytics capabilities—virtually all of the components you need for data exploration, preparation, and integration; petabyte-scale bigdata processing; fast SQL analytics; model development and training; governance; and generative AI development.
Amazon AppFlow automatically encrypts data in motion, and allows you to restrict data from flowing over the public internet for SaaS applications that are integrated with AWS PrivateLink , reducing exposure to security threats. He has helped customers build scalable data warehousing and bigdata solutions for over 16 years.
This post describes how HPE Aruba automated their Supply Chain management pipeline, and re-architected and deployed their data solution by adopting a modern dataarchitecture on AWS. The following diagram illustrates the solution architecture.
Amazon Redshift is a fast, scalable, and fully managed cloud datawarehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. Solution overview Amazon Redshift is an industry-leading cloud datawarehouse.
They must also select the data processing frameworks such as Spark, Beam or SQL-based processing and choose tools for ML. Based on business needs and the nature of the data, raw vs structured, organizations should determine whether to set up a datawarehouse, a Lakehouse or consider a data fabric technology.
The Gartner Magic Quadrant evaluates 20 data integration tool vendors based on two axesAbility to Execute and Completeness of Vision. Discover, prepare, and integrate all your data at any scale AWS Glue is a fully managed, serverless data integration service that simplifies data preparation and transformation across diverse data sources.
This post was co-written with Dipankar Mazumdar, Staff Data Engineering Advocate with AWS Partner OneHouse. Dataarchitecture has evolved significantly to handle growing data volumes and diverse workloads. For more examples and references to other posts on using XTable on AWS, refer to the following GitHub repository.
Satori enables both just-in-time and self-service access to data. Solution overview Satori creates a transparent layer providing visibility and control capabilities that is deployed in front of your existing Redshift datawarehouse. The following diagram illustrates the solution architecture.
Dataarchitecture is a complex and varied field and different organizations and industries have unique needs when it comes to their data architects. Solutions data architect: These individuals design and implement data solutions for specific business needs, including datawarehouses, data marts, and data lakes.
Amazon Redshift is a fully managed, petabyte-scale datawarehouse service in the cloud that delivers powerful and secure insights on all your data with the best price-performance. With Amazon Redshift, you can analyze your data to derive holistic insights about your business and your customers.
Need for a data mesh architecture Because entities in the EUROGATE group generate vast amounts of data from various sourcesacross departments, locations, and technologiesthe traditional centralized dataarchitecture struggles to keep up with the demands for real-time insights, agility, and scalability.
In today’s world, datawarehouses are a critical component of any organization’s technology ecosystem. The rise of cloud has allowed datawarehouses to provide new capabilities such as cost-effective data storage at petabyte scale, highly scalable compute and storage, pay-as-you-go pricing and fully managed service delivery.
But the data repository options that have been around for a while tend to fall short in their ability to serve as the foundation for bigdata analytics powered by AI. Traditional datawarehouses, for example, support datasets from multiple sources but require a consistent data structure.
While traditional extract, transform, and load (ETL) processes have long been a staple of data integration due to its flexibility, for common use cases such as replication and ingestion, they often prove time-consuming, complex, and less adaptable to the fast-changing demands of modern dataarchitectures.
Several factors determine the quality of your enterprise data like accuracy, completeness, consistency, to name a few. But there’s another factor of data quality that doesn’t get the recognition it deserves: your dataarchitecture. How the right dataarchitecture improves data quality.
The construction of bigdata applications based on open source software has become increasingly uncomplicated since the advent of projects like Data on EKS , an open source project from AWS to provide blueprints for building data and machine learning (ML) applications on Amazon Elastic Kubernetes Service (Amazon EKS).
This blog is intended to give an overview of the considerations you’ll want to make as you build your Redshift datawarehouse to ensure you are getting the optimal performance. Modeling Your Data for Performance. Dataarchitecture. The data landscape has changed significantly over the last two decades.
Tens of thousands of customers use Amazon Redshift for modern data analytics at scale, delivering up to three times better price-performance and seven times better throughput than other cloud datawarehouses. About the Authors Songzhi Liu is a Principal BigData Architect with the AWS Identity Solutions team.
Large-scale datawarehouse migration to the cloud is a complex and challenging endeavor that many organizations undertake to modernize their data infrastructure, enhance data management capabilities, and unlock new business opportunities. This makes sure the new data platform can meet current and future business goals.
In this post, we look at three key challenges that customers face with growing data and how a modern datawarehouse and analytics system like Amazon Redshift can meet these challenges across industries and segments. Nasdaq’s massive data growth meant they needed to evolve their dataarchitecture to keep up.
In his spare time, he loves reading and finds areas for home automation Raza Hafeez is a Senior Data Architect within the Shared Delivery Practice of AWS Professional Services. He specializes in migrating enterprise datawarehouses to AWS Modern DataArchitecture.
Companies today are struggling under the weight of their legacy datawarehouse. These old and inefficient systems were designed for a different era, when data was a side project and access to analytics was limited to the executive team. To do so, these companies need a modern datawarehouse, such as Snowflake.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud datawarehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing ETL (extract, transform, and load), business intelligence (BI), and reporting tools.
Amazon Redshift is a fully managed cloud datawarehouse that’s used by tens of thousands of customers for price-performance, scale, and advanced data analytics. This would necessitate the ability to securely share and potentially monetize the company’s data with external partners, such as franchises.
Amazon Redshift is a fast, fully managed petabyte-scale cloud datawarehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools. Amazon Redshift also supports querying nested data with complex data types such as struct, array, and map.
Since the deluge of bigdata over a decade ago, many organizations have learned to build applications to process and analyze petabytes of data. Data lakes have served as a central repository to store structured and unstructured data at any scale and in various formats.
They understand that a one-size-fits-all approach no longer works, and recognize the value in adopting scalable, flexible tools and open data formats to support interoperability in a modern dataarchitecture to accelerate the delivery of new solutions. Andries has over 20 years of experience in the field of data and analytics.
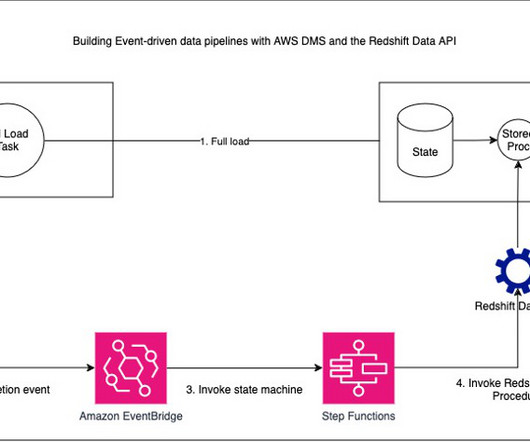
Diagram 1: Overall architecture of the solution, using AWS Step Functions, Amazon Redshift and Amazon S3 The following AWS services were used to shape our new ETL architecture: Amazon Redshift A fully managed, petabyte-scale datawarehouse service in the cloud.
The AaaS model accelerates data-driven decision-making through advanced analytics, enabling organizations to swiftly adapt to changing market trends and make informed strategic choices. times better price-performance than other cloud datawarehouses. Data processing jobs enrich the data in Amazon Redshift.
But at the other end of the attention spectrum is data management, which all too frequently is perceived as being boring, tedious, the work of clerks and admins, and ridiculously expensive. Still, to truly create lasting value with data, organizations must develop data management mastery. And here is the gotcha piece about data.
With the right technology now in place, ATB Financial is landing and curating more data than ever to bring data-driven insights to the business and its customers. Implementing a Modern DataArchitecture. ATB Financial is also the first to use SAS Viya to interface between SAS tools and HDP. Check out our customer stories.
In 2013, Amazon Web Services revolutionized the data warehousing industry by launching Amazon Redshift , the first fully-managed, petabyte-scale, enterprise-grade cloud datawarehouse. Amazon Redshift made it simple and cost-effective to efficiently analyze large volumes of data using existing business intelligence tools.
These lakes power mission critical large scale data analytics, business intelligence (BI), and machine learning use cases, including enterprise datawarehouses. In recent years, the term “data lakehouse” was coined to describe this architectural pattern of tabular analytics over data in the data lake.
In this post, we delve into the key aspects of using Amazon EMR for modern data management, covering topics such as data governance, data mesh deployment, and streamlined data discovery. Organizations have multiple Hive datawarehouses across EMR clusters, where the metadata gets generated.
Amazon SageMaker Lakehouse provides an open dataarchitecture that reduces data silos and unifies data across Amazon Simple Storage Service (Amazon S3) data lakes, Redshift datawarehouses, and third-party and federated data sources. AWS Glue 5.0 Finally, AWS Glue 5.0
To speed up the self-service analytics and foster innovation based on data, a solution was needed to provide ways to allow any team to create data products on their own in a decentralized manner. To create and manage the data products, smava uses Amazon Redshift , a cloud datawarehouse.
These lakes power mission critical large scale data analytics, business intelligence (BI), and machine learning use cases, including enterprise datawarehouses. In recent years, the term “data lakehouse” was coined to describe this architectural pattern of tabular analytics over data in the data lake.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content