This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A datalake is a centralized repository designed to house bigdata in structured, semi-structured and unstructured form. I have been covering the datalake topic for several years and encourage you to check out an earlier perspective called DataLakes: Safe Way to Swim in BigData?
In this analyst perspective, Dave Menninger takes a look at datalakes. He explains the term “datalake,” describes common use cases and shares his views on some of the latest market trends. He explores the relationship between data warehouses and datalakes and share some of Ventana Research’s findings on the subject.
The need for streamlined data transformations As organizations increasingly adopt cloud-based datalakes and warehouses, the demand for efficient data transformation tools has grown. Using Athena and the dbt adapter, you can transform raw data in Amazon S3 into well-structured tables suitable for analytics.
Databricks is a data engineering and analytics cloud platform built on top of Apache Spark that processes and transforms huge volumes of data and offers data exploration capabilities through machine learning models. The platform supports streaming data, SQL queries, graph processing and machine learning.
Data fuels the modern enterprise — today more than ever, businesses compete on their ability to turn bigdata into essential business insights. Increasingly, enterprises are leveraging cloud datalakes as the platform used to store data for analytics, combined with various compute engines for processing that data.
Amazon DataZone now launched authentication supports through the Amazon Athena JDBC driver, allowing data users to seamlessly query their subscribed datalake assets via popular business intelligence (BI) and analytics tools like Tableau, Power BI, Excel, SQL Workbench, DBeaver, and more.
Unlocking the true value of data often gets impeded by siloed information. Traditional data management—wherein each business unit ingests raw data in separate datalakes or warehouses—hinders visibility and cross-functional analysis. Amazon DataZone natively supports data sharing for Amazon Redshift data assets.
Over the years, this customer-centric approach has led to the introduction of groundbreaking features such as zero-ETL , data sharing , streaming ingestion , datalake integration , Amazon Redshift ML , Amazon Q generative SQL , and transactional datalake capabilities.
Fail Fast, Learn Faster: Lessons in Data-Driven Leadership in an Age of Disruption, BigData, and AI, by Randy Bean. This book is not available until January 2022, but considering all the hype around the data mesh, we expect it to be a best seller. A distributed data mesh is a better choice. How did we get here?
However, the initial version of CDH supported only coarse-grained access control to entire data assets, and hence it was not possible to scope access to data asset subsets. This led to inefficiencies in datagovernance and access control.
Data landscape in EUROGATE and current challenges faced in datagovernance The EUROGATE Group is a conglomerate of container terminals and service providers, providing container handling, intermodal transports, maintenance and repair, and seaworthy packaging services. Eliminate centralized bottlenecks and complex data pipelines.
In this post, we delve into the key aspects of using Amazon EMR for modern data management, covering topics such as datagovernance, data mesh deployment, and streamlined data discovery. Organizations have multiple Hive data warehouses across EMR clusters, where the metadata gets generated.
A modern data architecture enables companies to ingest virtually any type of data through automated pipelines into a datalake, which provides highly durable and cost-effective object storage at petabyte or exabyte scale.
Data is your generative AI differentiator, and a successful generative AI implementation depends on a robust data strategy incorporating a comprehensive datagovernance approach. Datagovernance is a critical building block across all these approaches, and we see two emerging areas of focus.
Since the deluge of bigdata over a decade ago, many organizations have learned to build applications to process and analyze petabytes of data. Datalakes have served as a central repository to store structured and unstructured data at any scale and in various formats.
Over the years, organizations have invested in creating purpose-built, cloud-based datalakes that are siloed from one another. A major challenge is enabling cross-organization discovery and access to data across these multiple datalakes, each built on different technology stacks.
The Regulatory Rationale for Integrating Data Management & DataGovernance. Now, as Cybersecurity Awareness Month comes to a close – and ghosts and goblins roam the streets – we thought it a good time to resurrect some guidance on how datagovernance can make data security less scary.
Organizations still struggle with limited data visibility and insufficient insights, which are often caused by a multitude of reasons such as analytic workloads running independently, data spread across multiple data centers, datagovernance, etc.
With this integration, you can now seamlessly query your governeddatalake assets in Amazon DataZone using popular business intelligence (BI) and analytics tools, including partner solutions like Tableau. When you’re connected, you can query, visualize, and share data—governed by Amazon DataZone—within Tableau.
Initially, the data inventories of different services were siloed within isolated environments, making data discovery and sharing across services manual and time-consuming for all teams involved. Implementing robust datagovernance is challenging. The following figure illustrates the data mesh architecture.
How can companies protect their enterprise data assets, while also ensuring their availability to stewards and consumers while minimizing costs and meeting data privacy requirements? Data Security Starts with DataGovernance. Lack of a solid datagovernance foundation increases the risk of data-security incidents.
Datagovernance is the process of ensuring the integrity, availability, usability, and security of an organization’s data. Due to the volume, velocity, and variety of data being ingested in datalakes, it can get challenging to develop and maintain policies and procedures to ensure datagovernance at scale for your datalake.
The combination of these three services provides a powerful, comprehensive solution for end-to-end data lineage analysis. In this post, we use dbt for data modeling on both Amazon Athena and Amazon Redshift. This led to the implementation of both Athena on dbt and Amazon Redshift on dbt architectures.
In this blog post, there are three personas: DataLake Administrator (with admin level access) User Silver from the Data Engineering group User Lead Auditor from the Auditor group. You will see how different personas in an organization can access the data without the need to modify their existing enterprise entitlements.
Talend is a data integration and management software company that offers applications for cloud computing, bigdata integration, application integration, data quality and master data management.
To address the flood of data and the needs of enterprise businesses to store, sort, and analyze that data, a new storage solution has evolved: the datalake. What’s in a DataLake? Data warehouses do a great job of standardizing data from disparate sources for analysis. Taking a Dip.
In the era of bigdata, datalakes have emerged as a cornerstone for storing vast amounts of raw data in its native format. They support structured, semi-structured, and unstructured data, offering a flexible and scalable environment for data ingestion from multiple sources.
Traditional on-premises data processing solutions have led to a hugely complex and expensive set of data silos where IT spends more time managing the infrastructure than extracting value from the data.
Data-driven organizations treat data as an asset and use it across different lines of business (LOBs) to drive timely insights and better business decisions. This leads to having data across many instances of data warehouses and datalakes using a modern data architecture in separate AWS accounts.
Building a datalake on Amazon Simple Storage Service (Amazon S3) provides numerous benefits for an organization. However, many use cases, like performing change data capture (CDC) from an upstream relational database to an Amazon S3-based datalake, require handling data at a record level.
AWS Lake Formation and the AWS Glue Data Catalog form an integral part of a datagovernance solution for datalakes built on Amazon Simple Storage Service (Amazon S3) with multiple AWS analytics services integrating with them. We realized that your use cases need more flexibility in datagovernance.
In today’s data-driven world , organizations are constantly seeking efficient ways to process and analyze vast amounts of information across datalakes and warehouses. This post will showcase how this data can also be queried by other data teams using Amazon Athena. Verify that you have Python version 3.7
He has over 17 years of experience architecting, building, leading, and maintaining bigdata platforms. Rohit helps customers modernize their analytic workloads using the breadth of AWS services and ensures that customers get the best price/performance with utmost security and datagovernance.
Under the federated mesh architecture, each divisional mesh functions as a node within the broader enterprise data mesh, maintaining a degree of autonomy in managing its data products. These nodes can implement analytical platforms like datalake houses, data warehouses, or data marts, all united by producing data products.
DataLakes have been around for well over a decade now, supporting the analytic operations of some of the largest world corporations. Such data volumes are not easy to move, migrate or modernize. The challenges of a monolithic datalake architecture Datalakes are, at a high level, single repositories of data at scale.
Datagovernance is the collection of policies, processes, and systems that organizations use to ensure the quality and appropriate handling of their data throughout its lifecycle for the purpose of generating business value.
VEDA — Verizon Enterprise Data Analytics—is an enterprise organization that addresses data management, datagovernance, data warehousing and datalakes and common analytical and AI technologies.
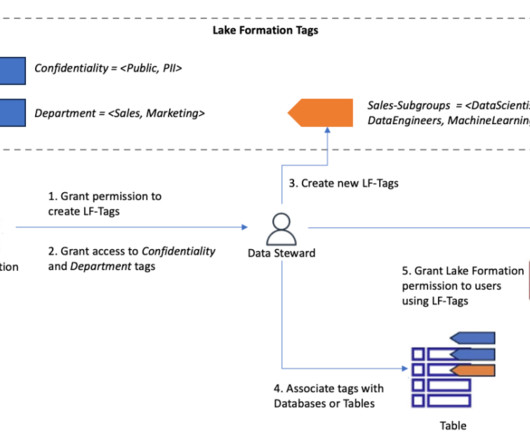
One of the core features of AWS Lake Formation is the delegation of permissions on a subset of resources such as databases, tables, and columns in AWS Glue Data Catalog to data stewards, empowering them make decisions regarding who should get access to their resources and helping you decentralize the permissions management of your datalakes.
Today, we are pleased to announce new AWS Glue connectors for Azure Blob Storage and Azure DataLake Storage that allow you to move data bi-directionally between Azure Blob Storage, Azure DataLake Storage, and Amazon Simple Storage Service (Amazon S3). option("header","true").load("wasbs://yourblob@youraccountname.blob.core.windows.net/loadingtest-input/100mb")
Even after identification, it’s cumbersome to implement redaction, masking, or encryption of sensitive data at scale. In this post, we provide an automated solution to detect PII data in Amazon Redshift using AWS Glue. For our solution, we use Amazon Redshift to store the data.
New feature: Custom AWS service blueprints Previously, Amazon DataZone provided default blueprints that created AWS resources required for datalake, data warehouse, and machine learning use cases. You can build projects and subscribe to both unstructured and structured data assets within the Amazon DataZone portal.
Solutions data architect: These individuals design and implement data solutions for specific business needs, including data warehouses, data marts, and datalakes. Application data architect: The application data architect designs and implements data models for specific software applications.
Analytics remained one of the key focus areas this year, with significant updates and innovations aimed at helping businesses harness their data more efficiently and accelerate insights. From enhancing datalakes to empowering AI-driven analytics, AWS unveiled new tools and services that are set to shape the future of data and analytics.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content