This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Q dataintegration , introduced in January 2024, allows you to use natural language to author extract, transform, load (ETL) jobs and operations in AWS Glue specific data abstraction DynamicFrame. In this post, we discuss how Amazon Q dataintegration transforms ETL workflow development.
With the growing emphasis on data, organizations are constantly seeking more efficient and agile ways to integrate their data, especially from a wide variety of applications. SageMaker Lakehouse gives you the flexibility to access and query your data in-place with all Apache Iceberg compatible tools and engines.
Amazon Web Services (AWS) has been recognized as a Leader in the 2024 Gartner Magic Quadrant for DataIntegration Tools. This recognition, we feel, reflects our ongoing commitment to innovation and excellence in dataintegration, demonstrating our continued progress in providing comprehensive data management solutions.
Talend is a dataintegration and management software company that offers applications for cloud computing, bigdataintegration, application integration, data quality and master data management.
Datalakes and data warehouses are two of the most important data storage and management technologies in a modern data architecture. Datalakes store all of an organization’s data, regardless of its format or structure.
licensed, 100% open-source data table format that helps simplify data processing on large datasets stored in datalakes. Data engineers use Apache Iceberg because it’s fast, efficient, and reliable at any scale and keeps records of how datasets change over time.
A datalake is a centralized repository that you can use to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data and then run different types of analytics for better business insights. They are the same.
Today, we’re excited to announce general availability of Amazon Q dataintegration in AWS Glue. Amazon Q dataintegration, a new generative AI-powered capability of Amazon Q Developer , enables you to build dataintegration pipelines using natural language.
Unlocking the true value of data often gets impeded by siloed information. Traditional data management—wherein each business unit ingests raw data in separate datalakes or warehouses—hinders visibility and cross-functional analysis. Amazon DataZone natively supports data sharing for Amazon Redshift data assets.
SageMaker brings together widely adopted AWS ML and analytics capabilities—virtually all of the components you need for data exploration, preparation, and integration; petabyte-scale bigdata processing; fast SQL analytics; model development and training; governance; and generative AI development.
Effective data analytics relies on seamlessly integratingdata from disparate systems through identifying, gathering, cleansing, and combining relevant data into a unified format. This solution also allows you to update certain fields of the account object in the datalake and push it back to Salesforce.
Today, Amazon Redshift is used by customers across all industries for a variety of use cases, including data warehouse migration and modernization, near real-time analytics, self-service analytics, datalake analytics, machine learning (ML), and data monetization.
Amazon Redshift enables you to directly access data stored in Amazon Simple Storage Service (Amazon S3) using SQL queries and join data across your data warehouse and datalake. With Amazon Redshift, you can query the data in your S3 datalake using a central AWS Glue metastore from your Redshift data warehouse.
We often see requests from customers who have started their data journey by building datalakes on Microsoft Azure, to extend access to the data to AWS services. In such scenarios, data engineers face challenges in connecting and extracting data from storage containers on Microsoft Azure.
In the current industry landscape, datalakes have become a cornerstone of modern data architecture, serving as repositories for vast amounts of structured and unstructured data. Maintaining data consistency and integrity across distributed datalakes is crucial for decision-making and analytics.
Unified access to your data is provided by Amazon SageMaker Lakehouse , a unified, open, and secure data lakehouse built on Apache Iceberg open standards. Now, theyre able to build and collaborate with their data and tools available in one experience, dramatically reducing time-to-value.
In this post, we delve into the key aspects of using Amazon EMR for modern data management, covering topics such as data governance, data mesh deployment, and streamlined data discovery. Organizations have multiple Hive data warehouses across EMR clusters, where the metadata gets generated.
Apache Iceberg brings the reliability and simplicity of SQL tables to bigdata, while making it possible for processing engines such as Apache Spark, Trino, Apache Flink, Presto, Apache Hive, and Impala to safely work with the same tables at the same time. The following table shows the cost and time for each query and product.
With data becoming the driving force behind many industries today, having a modern data architecture is pivotal for organizations to be successful. In this post, we describe Orca’s journey building a transactional datalake using Amazon Simple Storage Service (Amazon S3), Apache Iceberg, and AWS Analytics.
cycle_end"', "sagemakedatalakeenvironment_sub_db", ctas_approach=False) A similar approach is used to connect to shared data from Amazon Redshift, which is also shared using Amazon DataZone. While real-time data is processed by other applications, this setup maintains high-performance analytics without the expense of continuous processing.
Like oil, data is valuable but it must be refined in order to provide value. Organizations need to collect, organize, and analyze their data across multi-cloud, hybrid cloud, and datalakes. Yet traditional ETL tools support only a limited number of delivery styles and involve a significant amount of hand-coding.
Third, some services require you to set up and manage compute resources used for federated connectivity, and capabilities like connection testing and data preview arent available in all services. To solve for these challenges, we launched Amazon SageMaker Lakehouse unified data connectivity.
Now you can author data preparation transformations and edit them with the AWS Glue Studio visual editor. The AWS Glue Studio visual editor is a graphical interface that enables you to create, run, and monitor dataintegration jobs in AWS Glue. She is passionate about helping customers build datalakes using ETL workloads.
AWS Glue is a serverless, scalable dataintegration service that makes it easier to discover, prepare, move, and integratedata from multiple sources. AWS Glue provides an extensible architecture that enables users with different data processing use cases.
In the era of bigdata, datalakes have emerged as a cornerstone for storing vast amounts of raw data in its native format. They support structured, semi-structured, and unstructured data, offering a flexible and scalable environment for data ingestion from multiple sources.
Data analytics on operational data at near-real time is becoming a common need. Due to the exponential growth of data volume, it has become common practice to replace read replicas with datalakes to have better scalability and performance. Apache Hudi connector for AWS Glue For this post, we use AWS Glue 4.0,
About the Authors Noritaka Sekiyama is a Principal BigData Architect on the AWS Glue team. Keerthi Chadalavada is a Senior Software Development Engineer at AWS Glue, focusing on combining generative AI and dataintegration technologies to design and build comprehensive solutions for customers’ data and analytics needs.
Amazon Redshift is a fast, scalable, and fully managed cloud data warehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. It also helps you securely access your data in operational databases, datalakes, or third-party datasets with minimal movement or copying of data.
Reading Time: 4 minutes The amount of expanding volume and variety of data originating from various sources are a massive challenge for businesses. In attempts to overcome their bigdata challenges, organizations are exploring datalakes as repositories where huge volumes and varieties of.
Customers often want to augment and enrich SAP source data with other non-SAP source data. Such analytic use cases can be enabled by building a data warehouse or datalake. Customers can now use the AWS Glue SAP OData connector to extract data from SAP. For more information see AWS Glue.
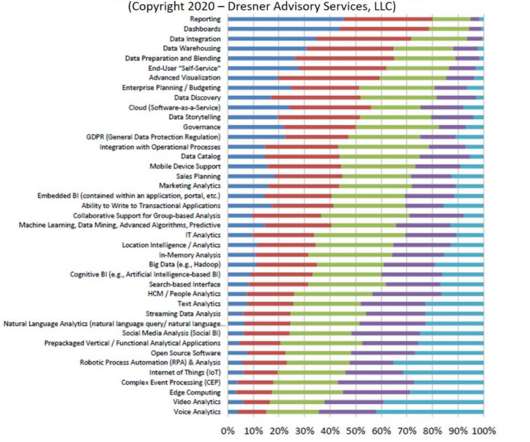
Among all the hot analytics initiatives to choose from (bigdata, IoT, NLP, data storytelling, cognitive BI, GDPR), plain old reporting is what is considered the most important strategic initiative. But seriously, reporting?
Under that focus, Informatica's conference emphasized capabilities across six areas (all strong areas for Informatica): dataintegration, data management, data quality & governance, Master Data Management (MDM), data cataloging, and data security.
Today, we are pleased to announce new AWS Glue connectors for Azure Blob Storage and Azure DataLake Storage that allow you to move data bi-directionally between Azure Blob Storage, Azure DataLake Storage, and Amazon Simple Storage Service (Amazon S3). option("header","true").load("wasbs://yourblob@youraccountname.blob.core.windows.net/loadingtest-input/100mb")
Bigdata is shaping our world in countless ways. Data powers everything we do. Exactly why, the systems have to ensure adequate, accurate and most importantly, consistent data flow between different systems. A point of data entry in a given pipeline. Data Pipeline: Use Cases. Destination.
These features allow efficient data corrections, gap-filling in time series, and historical data updates without disrupting ongoing analyses or compromising dataintegrity. Unlike direct Amazon S3 access, Iceberg supports these operations on petabyte-scale datalakes without requiring complex custom code.
Even after identification, it’s cumbersome to implement redaction, masking, or encryption of sensitive data at scale. In this post, we provide an automated solution to detect PII data in Amazon Redshift using AWS Glue. For our solution, we use Amazon Redshift to store the data.
In today’s data-driven business environment, organizations face the challenge of efficiently preparing and transforming large amounts of data for analytics and data science purposes. Businesses need to build data warehouses and datalakes based on operational data.
Sesha Sanjana Mylavarapu is an Associate DataLake Consultant at AWS Professional Services. She specializes in cloud-based data management and collaborates with enterprise clients to design and implement scalable datalakes.
Apache Hudi is an open table format that brings database and data warehouse capabilities to datalakes. Apache Hudi helps data engineers manage complex challenges, such as managing continuously evolving datasets with transactions while maintaining query performance. Under Administration , choose Data catalog settings.
This week SnapLogic posted a presentation of the 10 Modern DataIntegration Platform Requirements on the company’s blog. They are: Application integration is done primarily through REST & SOAP services. Large-volume dataintegration is available to Hadoop-based datalakes or cloud-based data warehouses.
In the first post of this series , we described how AWS Glue for Apache Spark works with Apache Hudi, Linux Foundation Delta Lake, and Apache Iceberg datasets tables using the native support of those datalake formats. Even without prior experience using Hudi, Delta Lake or Iceberg, you can easily achieve typical use cases.
This post is co-authored by Vijay Gopalakrishnan, Director of Product, Salesforce Data Cloud. In today’s data-driven business landscape, organizations collect a wealth of data across various touch points and unify it in a central data warehouse or a datalake to deliver business insights.
As organizations increasingly rely on data stored across various platforms, such as Snowflake , Amazon Simple Storage Service (Amazon S3), and various software as a service (SaaS) applications, the challenge of bringing these disparate data sources together has never been more pressing. For more information on AWS Glue, visit AWS Glue.
Hundreds of thousands of customers use AWS Glue , a serverless dataintegration service, to discover, prepare, and combine data for analytics, machine learning (ML), and application development. AWS Glue for Apache Spark jobs work with your code and configuration of the number of data processing units (DPU).
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content