This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Q dataintegration , introduced in January 2024, allows you to use natural language to author extract, transform, load (ETL) jobs and operations in AWS Glue specific data abstraction DynamicFrame. In this post, we discuss how Amazon Q dataintegration transforms ETL workflow development.
Piperr.io — Pre-built data pipelines across enterprise stakeholders, from IT to analytics, tech, data science and LoBs. Prefect Technologies — Open-source data engineering platform that builds, tests, and runs data workflows. Genie — Distributed bigdata orchestration service by Netflix.
In a recent survey , we explored how companies were adjusting to the growing importance of machine learning and analytics, while also preparing for the explosion in the number of data sources. You can find full results from the survey in the free report “Evolving Data Infrastructure”.). Data Platforms. Deep Learning.
Third, some services require you to set up and manage compute resources used for federated connectivity, and capabilities like connection testing and data preview arent available in all services. To solve for these challenges, we launched Amazon SageMaker Lakehouse unified data connectivity. For Add data source , choose Add connection.
The bigdata market is expected to be worth $189 billion by the end of this year. A number of factors are driving growth in bigdata. Demand for bigdata is part of the reason for the growth, but the fact that bigdata technology is evolving is another. Characteristics of BigData.
The SAP OData connector supports both on-premises and cloud-hosted (native and SAP RISE) deployments. By using the AWS Glue OData connector for SAP, you can work seamlessly with your data on AWS Glue and Apache Spark in a distributed fashion for efficient processing. For more information see AWS Glue.
Operations data: Data generated from a set of operations such as orders, online transactions, competitor analytics, sales data, point of sales data, pricing data, etc. The gigantic evolution of structured, unstructured, and semi-structured data is referred to as Bigdata. BigData Ingestion.
The applications are hosted in dedicated AWS accounts and require a BI dashboard and reporting services based on Tableau. While real-time data is processed by other applications, this setup maintains high-performance analytics without the expense of continuous processing. She can reached via LinkedIn.
Many AWS customers have integrated their data across multiple data sources using AWS Glue , a serverless dataintegration service, in order to make data-driven business decisions. Are there recommended approaches to provisioning components for dataintegration?
Let’s briefly describe the capabilities of the AWS services we referred above: AWS Glue is a fully managed, serverless, and scalable extract, transform, and load (ETL) service that simplifies the process of discovering, preparing, and loading data for analytics. To incorporate this third-party data, AWS Data Exchange is the logical choice.
As organizations increasingly rely on data stored across various platforms, such as Snowflake , Amazon Simple Storage Service (Amazon S3), and various software as a service (SaaS) applications, the challenge of bringing these disparate data sources together has never been more pressing.
In this post, we provide a step-by-step guide for installing and configuring Oracle GoldenGate for streaming data from relational databases to Amazon Simple Storage Service (Amazon S3) for real-time analytics using the Oracle GoldenGate S3 handler. These handlers allow GoldenGate to read from and write data to S3 buckets.
It covers the essential steps for taking snapshots of your data, implementing safe transfer across different AWS Regions and accounts, and restoring them in a new domain. This guide is designed to help you maintain dataintegrity and continuity while navigating complex multi-Region and multi-account environments in OpenSearch Service.
In today’s data-driven world, seamless integration and transformation of data across diverse sources into actionable insights is paramount. Access to an SFTP server with permissions to upload and download data. BigData and ETL Solutions Architect, MWAA and AWS Glue ETL expert. Choose Store a new secret.
With this in mind, the erwin team has compiled a list of the most valuable data governance, GDPR and Bigdata blogs and news sources for data management and data governance best practice advice from around the web. Top 7 Data Governance, GDPR and BigData Blogs and News Sources from Around the Web.
You can slice data by different dimensions like job name, see anomalies, and share reports securely across your organization. With these insights, teams have the visibility to make dataintegration pipelines more efficient. Typically, you have multiple accounts to manage and run resources for your data pipeline.
This has led to the emergence of the field of BigData, which refers to the collection, processing, and analysis of vast amounts of data. With the right BigData Tools and techniques, organizations can leverage BigData to gain valuable insights that can inform business decisions and drive growth.
In this post, we delve into the key aspects of using Amazon EMR for modern data management, covering topics such as data governance, data mesh deployment, and streamlined data discovery. Organizations have multiple Hive data warehouses across EMR clusters, where the metadata gets generated.
The workflow consists of the following initial steps: OpenSearch Service is hosted in the primary Region, and all the active traffic is routed to the OpenSearch Service domain in the primary Region.
Over the past 5 years, bigdata and BI became more than just data science buzzwords. Without real-time insight into their data, businesses remain reactive, miss strategic growth opportunities, lose their competitive edge, fail to take advantage of cost savings options, don’t ensure customer satisfaction… the list goes on.
Rise in polyglot data movement because of the explosion in data availability and the increased need for complex data transformations (due to, e.g., different data formats used by different processing frameworks or proprietary applications). As a result, alternative dataintegration technologies (e.g.,
Data monetization strategy: Managing data as a product Every organization has the potential to monetize their data; for many organizations, it is an untapped resource for new capabilities. But few organizations have made the strategic shift to managing “data as a product.”
With the advent of enterprise-level cloud computing, organizations could embark on cloud migration journeys and outsource IT storage space and processing power needs to public clouds hosted by third-party cloud service providers like Amazon Web Services (AWS), IBM Cloud, Google Cloud and Microsoft Azure.
This podcast centers around data management and investigates a different aspect of this field each week. Within each episode, there are actionable insights that data teams can apply in their everyday tasks or projects. The host is Tobias Macey, an engineer with many years of experience. Agile Data.
Data ingestion must be done properly from the start, as mishandling it can lead to a host of new issues. The groundwork of training data in an AI model is comparable to piloting an airplane. This may also entail working with new data through methods like web scraping or uploading.
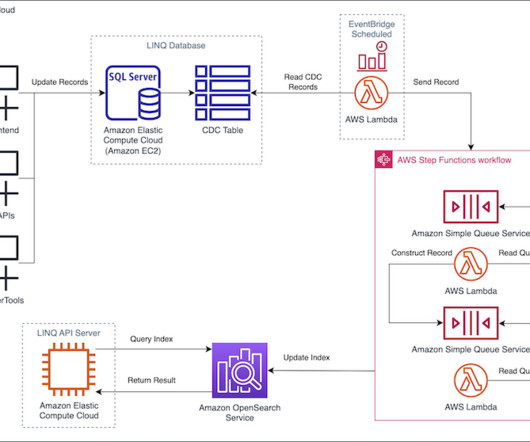
Initially, searches from Hub queried LINQ’s Microsoft SQL Server database hosted on Amazon Elastic Compute Cloud (Amazon EC2), with search times averaging 3 seconds, leading to reduced adoption and negative feedback. The LINQ team exposes access to the OpenSearch Service index through a search API hosted on Amazon EC2.
In this post, we discuss how the reimagined data flow works with OR1 instances and how it can provide high indexing throughput and durability using a new physical replication protocol. We also dive deep into some of the challenges we solved to maintain correctness and dataintegrity.
The Orca Platform is powered by a state-of-the-art anomaly detection system that uses cutting-edge ML algorithms and bigdata capabilities to detect potential security threats and alert customers in real time, ensuring maximum security for their cloud environment. Why did Orca choose Apache Iceberg?
To share data to our internal consumers, we use AWS Lake Formation with LF-Tags to streamline the process of managing access rights across the organization. Dataintegration workflow A typical dataintegration process consists of ingestion, analysis, and production phases.
Args: region (str): AWS region where the MWAA environment is hosted. Args: region (str): AWS region where the MWAA environment is hosted. BigData and ETL Solutions Architect, MWAA and AWS Glue ETL expert. env_name (str): Name of the MWAA environment. env_name (str): Name of the MWAA environment. His secret weapon?
Set up a custom domain with Amazon Redshift in the primary Region In the hosted zone that Route 53 created when you registered the domain, create records to tell Route 53 how you want to route traffic to Redshift endpoint by completing the following steps: On the Route 53 console, choose Hosted zones in the navigation pane.
Data ingestion You have to build ingestion pipelines based on factors like types of data sources (on-premises data stores, files, SaaS applications, third-party data), and flow of data (unbounded streams or batch data). Data exploration Data exploration helps unearth inconsistencies, outliers, or errors.
Streaming ingestion from Amazon MSK into Amazon Redshift, represents a cutting-edge approach to real-time data processing and analysis. Amazon MSK serves as a highly scalable, and fully managed service for Apache Kafka, allowing for seamless collection and processing of vast streams of data.
During data transfer, ensure that you pass the data through controls meant to improve reliability, as data tend to degenerate with time. Monitor the data to understand dataintegrity better. Data Migration Strategies. When you migrate data, it is not only your IT team that gets involved.
Using Amazon MSK, we securely stream data with a fully managed, highly available Apache Kafka service. Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, dataintegration, and mission-critical applications.
Change data capture (CDC) is one of the most common design patterns to capture the changes made in the source database and reflect them to other data stores. a new version of AWS Glue that accelerates dataintegration workloads in AWS.
A host with the installed MySQL utility, such as an Amazon Elastic Compute Cloud (Amazon EC2) instance, AWS Cloud9 , your laptop, and so on. The host is used to access an Amazon Aurora MySQL-Compatible Edition cluster that you create and to run a Python script that sends sample records to the Kinesis data stream.
The typical Cloudera Enterprise Data Hub Cluster starts with a few dozen nodes in the customer’s datacenter hosting a variety of distributed services. Over time, workloads start processing more data, tenants start onboarding more workloads, and administrators (admins) start onboarding more tenants. Conclusion and future work.
Unified, governed data can also be put to use for various analytical, operational and decision-making purposes. This process is known as dataintegration, one of the key components to a strong data fabric. The remote execution engine is a fantastic technical development which takes dataintegration to the next level.
It includes perspectives about current issues, themes, vendors, and products for data governance. My interest in data governance (DG) began with the recent industry surveys by O’Reilly Media about enterprise adoption of “ABC” (AI, BigData, Cloud). We keep feeding the monster data. the flywheel effect.
For enterprises dealing with sensitive information, it is vital to maintain state-of-the-art data security in order to reap the rewards,” says Stuart Winter, Executive Chairman and Co-Founder at Lacero Platform Limited, Jamworks and Guardian.
Launch the notebooks hosted under this link and unzip them on a local workstation. The path you choose for this upgrade, an in-place upgrade or CTAS migration, or a combination of both, will depend on careful analysis of the data architecture and dataintegration pipeline. Open AWS Glue Studio. Choose ETL Jobs.
Besides being an award-winning data modeling tool, erwin Data Modeler is proving it can still innovate by adding even more NoSQL database connectivity support options and a DevOps feature that makes this trusted 30-year tool the new kid on the block again. Google Big Query. dataintegrity. Git Hosting Service.
Examples: user empowerment and the speed of getting answers (not just reports) • There is a growing interest in data that tells stories; keep up with advances in storyboarding to package visual analytics that might fill some gaps in communication and collaboration • Monitor rumblings about trend to shift data to secure storage outside the U.S.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content