This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the DataScience Blogathon. Introduction A datalake is a centralized repository for storing, processing, and securing massive amounts of structured, semi-structured, and unstructured data. DataLakes are an important […].
This article was published as a part of the DataScience Blogathon. Introduction Today, DataLake is most commonly used to describe an ecosystem of IT tools and processes (infrastructure as a service, software as a service, etc.) that work together to make processing and storing large volumes of data easy.
This article was published as a part of the DataScience Blogathon. Introduction A datalake is a central data repository that allows us to store all of our structured and unstructured data on a large scale. The post A Detailed Introduction on DataLakes and Delta Lakes appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon. Before seeing the practical implementation of the use case, let’s briefly introduce Azure DataLake Storage Gen2 and the Paramiko module. The post An Overview of Using Azure DataLake Storage Gen2 appeared first on Analytics Vidhya.
While there is a lot of discussion about the merits of data warehouses, not enough discussion centers around datalakes. We talked about enterprise data warehouses in the past, so let’s contrast them with datalakes. Both data warehouses and datalakes are used when storing bigdata.
For container terminal operators, data-driven decision-making and efficient data sharing are vital to optimizing operations and boosting supply chain efficiency. Two use cases illustrate how this can be applied for business intelligence (BI) and datascience applications, using AWS services such as Amazon Redshift and Amazon SageMaker.
SageMaker brings together widely adopted AWS ML and analytics capabilities—virtually all of the components you need for data exploration, preparation, and integration; petabyte-scale bigdata processing; fast SQL analytics; model development and training; governance; and generative AI development.
Fail Fast, Learn Faster: Lessons in Data-Driven Leadership in an Age of Disruption, BigData, and AI, by Randy Bean. This book is not available until January 2022, but considering all the hype around the data mesh, we expect it to be a best seller. A distributed data mesh is a better choice. How did we get here?
Since the deluge of bigdata over a decade ago, many organizations have learned to build applications to process and analyze petabytes of data. Datalakes have served as a central repository to store structured and unstructured data at any scale and in various formats.
Various data pipelines process these logs, storing petabytes (PBs) of data per month, which after processing data stored on Amazon S3, are then stored in Snowflake Data Cloud. Until recently, this data was mostly prepared by automated processes and aggregated into results tables, used by only a few internal teams.
Microsoft just held one of its largest conferences of the year, and a few major announcements were made which pertain to the cloud datascience world. Azure Synapse Analytics can be seen as a merge of Azure SQL Data Warehouse and Azure DataLake. Those are the bigdatascience announcements of the week.
The BigData revolution has been surprisingly rapid. Even five years ago many companies were still asking the question, “What is BigData?” We were consistently being told that datascience would be the “ sexiest ” job of the century but finding a data scientist to implement a BigData project was difficult to do.
Recently, I gave a Make Your Data Work Monday webinar on the complexities of the data sources for datascience in Azure, and I thought it important enough to turn into an actual post. How can you differentiate the different opportunities to store your data in Azure? Organizations need to recast storing their data.
Organizations are always looking to improve their ability to use data and AI to gain meaningful and actionable insights into their operations, services and customer needs. But unlocking value from data requires multiple analytics workloads, datascience tools and machine learning algorithms to run against the same diverse data sets.
As organizations across the globe are modernizing their data platforms with datalakes on Amazon Simple Storage Service (Amazon S3), handling SCDs in datalakes can be challenging.
It manages large collections of files as tables, and it supports modern analytical datalake operations such as record-level insert, update, delete, and time travel queries. About the Authors Vivek Gautam is a Data Architect with specialization in datalakes at AWS Professional Services.
It’s been one decade since the “ BigData Era ” began (and to much acclaim!). Analysts asked, What if we could manage massive volumes and varieties of data? Yet the question remains: How much value have organizations derived from bigdata? BigData as an Enabler of Digital Transformation.
Enterprise data is brought into datalakes and data warehouses to carry out analytical, reporting, and datascience use cases using AWS analytical services like Amazon Athena , Amazon Redshift , Amazon EMR , and so on. About the author Naidu Rongal i is a BigData and ML engineer at Amazon.
But the data repository options that have been around for a while tend to fall short in their ability to serve as the foundation for bigdata analytics powered by AI. Traditional data warehouses, for example, support datasets from multiple sources but require a consistent data structure. Meet the data lakehouse.
Data analytics on operational data at near-real time is becoming a common need. Due to the exponential growth of data volume, it has become common practice to replace read replicas with datalakes to have better scalability and performance. For more information, see Changing the default settings for your datalake.
Tens of thousands of customers use Amazon Redshift every day to run analytics, processing exabytes of data for business insights. times better price performance than other cloud data warehouses. He has helped customers build scalable data warehousing and bigdata solutions for over 16 years.
In today’s data-driven world , organizations are constantly seeking efficient ways to process and analyze vast amounts of information across datalakes and warehouses. This post will showcase how this data can also be queried by other data teams using Amazon Athena. Verify that you have Python version 3.7
The Salesforce Trust Intelligence Platform (TIP) log platform team is responsible for data pipeline and datalake infrastructure, providing log ingestion, normalization, persistence, search, and detection capability to ensure Salesforce is safe from threat actors. This is the bronze layer of the TIP datalake.
Though you may encounter the terms “datascience” and “data analytics” being used interchangeably in conversations or online, they refer to two distinctly different concepts. Meanwhile, data analytics is the act of examining datasets to extract value and find answers to specific questions.
DataLakes have been around for well over a decade now, supporting the analytic operations of some of the largest world corporations. Such data volumes are not easy to move, migrate or modernize. The challenges of a monolithic datalake architecture Datalakes are, at a high level, single repositories of data at scale.
The recent announcement of the Microsoft Intelligent Data Platform makes that more obvious, though analytics is only one part of that new brand. Azure Data Explorer. Azure DataLake Analytics. Data warehouses are designed for questions you already know you want to ask about your data, again and again.
Reading Time: 4 minutes The amount of expanding volume and variety of data originating from various sources are a massive challenge for businesses. In attempts to overcome their bigdata challenges, organizations are exploring datalakes as repositories where huge volumes and varieties of.
The data architect also “provides a standard common business vocabulary, expresses strategic requirements, outlines high-level integrated designs to meet those requirements, and aligns with enterprise strategy and related business architecture,” according to DAMA International’s Data Management Body of Knowledge.
In today’s data-driven business environment, organizations face the challenge of efficiently preparing and transforming large amounts of data for analytics and datascience purposes. Businesses need to build data warehouses and datalakes based on operational data.
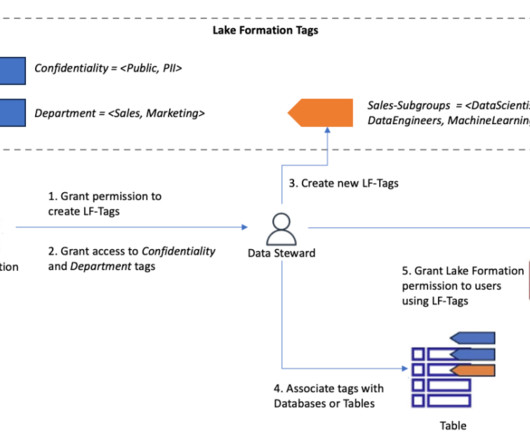
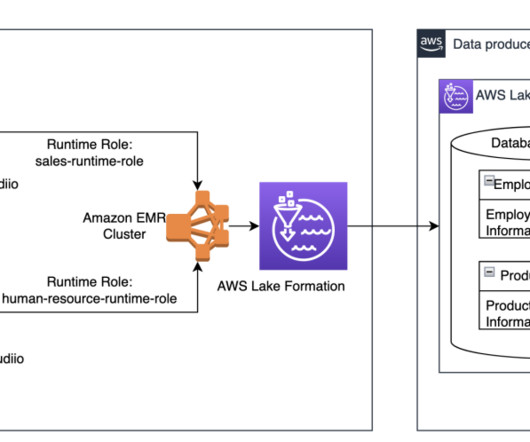
One of the core features of AWS Lake Formation is the delegation of permissions on a subset of resources such as databases, tables, and columns in AWS Glue Data Catalog to data stewards, empowering them make decisions regarding who should get access to their resources and helping you decentralize the permissions management of your datalakes.
This year, we expanded our partnership with NVIDIA , enabling your data teams to dramatically speed up compute processes for data engineering and datascience workloads with no code changes using RAPIDS AI. Data Ingestion. The raw data is in a series of CSV files. What is RAPIDS. Register Now. .
Amazon EMR Studio is an integrated development environment (IDE) that makes it straightforward for data scientists and data engineers to develop, visualize, and debug data engineering and datascience applications written in R, Python, Scala, and PySpark. This helps you reduce operational overhead.
Cloudera customers run some of the biggest datalakes on earth. These lakes power mission critical large scale data analytics, business intelligence (BI), and machine learning use cases, including enterprise data warehouses. On data warehouses and datalakes.
Cloudera customers run some of the biggest datalakes on earth. These lakes power mission critical large scale data analytics, business intelligence (BI), and machine learning use cases, including enterprise data warehouses. On data warehouses and datalakes.
This post was co-written with Rajiv Arora, Director of DataScience Platform at Gilead Life Sciences. Gilead Sciences, Inc. Create a datalake external schema and table in Redshift Serverless. You can query datalake tables directly from Amazon Redshift Query Editor v2 or your favorite SQL editors.
Amazon Redshift is a fully managed data warehousing service that offers both provisioned and serverless options, making it more efficient to run and scale analytics without having to manage your data warehouse. Additionally, data is extracted from vendor APIs that includes data related to product, marketing, and customer experience.
One modern data platform solution that provides simplicity and flexibility to grow is Snowflake’s data cloud and platform. These Snowflake accelerators reduce the time to analytics for your users at all levels so you can make data-driven decisions faster. Security DataLake. Overall data architecture and strategy.
It hosts over 150 bigdata analytics sandboxes across the region with over 200 users utilizing the sandbox for data discovery. With this functionality, business units can now leverage bigdata analytics to develop better and faster insights to help achieve better revenues, higher productivity, and decrease risk. .
Data, of course, has been all the rage the past decade, having been declared the “new oil” of the digital economy. And yes, data has enormous potential to create value for your business, making its accrual and the analysis of it, aka datascience, very exciting. And here is the gotcha piece about data.
Combining AWS data integration services like AWS Glue with data platforms like Snowflake allows you to build scalable, secure datalakes and pipelines to power analytics, BI, datascience, and ML use cases. This unlocks scalable analytics while maintaining data governance, compliance, and access control.
In conjunction with the evolving data ecosystem are demands by business for reliable, trustworthy, up-to-date data to enable real-time actionable insights. BigData Fabric has emerged in response to modern data ecosystem challenges facing today’s enterprises. What is BigData Fabric? Data access.
OCBC identified the need to upgrade its datalake technology as part of an enterprise datascience initiative to introduce a more resilient infrastructure and platform capable of managing projects with increasing volume, variety and velocity of data, while also enabling real-time analytics. .
Managing data and its flow, from the edge to the cloud, is one of the most important tasks in the process of gaining data intelligence. . The category Data Lifecycle Connection highlights organizations that work with multiple parts of the data lifecycle to collect, enrich, report, serve, and predict. .
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content