This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Redshift is a fast, fully managed cloud data warehouse that makes it cost-effective to analyze your data using standard SQL and business intelligence tools. Customers use datalake tables to achieve cost effective storage and interoperability with other tools. The sample files are ‘|’ delimited text files.
Amazon DataZone now launched authentication supports through the Amazon Athena JDBC driver, allowing data users to seamlessly query their subscribed datalake assets via popular business intelligence (BI) and analytics tools like Tableau, Power BI, Excel, SQL Workbench, DBeaver, and more.
Initially, data warehouses were the go-to solution for structured data and analytical workloads but were limited by proprietary storage formats and their inability to handle unstructured data. Eventually, transactional datalakes emerged to add transactional consistency and performance of a data warehouse to the datalake.
Many organizations operate datalakes spanning multiple cloud data stores. In these cases, you may want an integrated query layer to seamlessly run analytical queries across these diverse cloud stores and streamline your data analytics processes. You can download the sample data file cust_feedback_v0.csv.
Datalakes and data warehouses are two of the most important data storage and management technologies in a modern data architecture. Datalakes store all of an organization’s data, regardless of its format or structure.
Tens of thousands of customers use Amazon Redshift every day to run analytics, processing exabytes of data for business insights. times better price performance than other cloud data warehouses. For macOS and Linux users, you need to deflate the downloaded gzip file. Amazon Redshift is built for scale and delivers up to 7.9
Amazon Redshift enables you to directly access data stored in Amazon Simple Storage Service (Amazon S3) using SQL queries and join data across your data warehouse and datalake. With Amazon Redshift, you can query the data in your S3 datalake using a central AWS Glue metastore from your Redshift data warehouse.
For many organizations, this centralized data store follows a datalake architecture. Although datalakes provide a centralized repository, making sense of this data and extracting valuable insights can be challenging. Process the file to extract or convert the text content.
Datalakes have been gaining popularity for storing vast amounts of data from diverse sources in a scalable and cost-effective way. As the number of data consumers grows, datalake administrators often need to implement fine-grained access controls for different user profiles.
Since the deluge of bigdata over a decade ago, many organizations have learned to build applications to process and analyze petabytes of data. Datalakes have served as a central repository to store structured and unstructured data at any scale and in various formats.
In this post, we delve into the key aspects of using Amazon EMR for modern data management, covering topics such as data governance, data mesh deployment, and streamlined data discovery. Organizations have multiple Hive data warehouses across EMR clusters, where the metadata gets generated.
With this integration, you can now seamlessly query your governed datalake assets in Amazon DataZone using popular business intelligence (BI) and analytics tools, including partner solutions like Tableau. Prerequisites To get started, complete these steps: Download and install the latest Athena JDBC driver for Tableau.
Download the Report. The BigData revolution has been surprisingly rapid. Even five years ago many companies were still asking the question, “What is BigData?”
Over the years, organizations have invested in creating purpose-built, cloud-based datalakes that are siloed from one another. A major challenge is enabling cross-organization discovery and access to data across these multiple datalakes, each built on different technology stacks.
A modern data architecture is an evolutionary architecture pattern designed to integrate a datalake, data warehouse, and purpose-built stores with a unified governance model. The company wanted the ability to continue processing operational data in the secondary Region in the rare event of primary Region failure.
Option 3: Azure DataLakes. This leads us to Microsoft’s apparent long-term strategy for D365 F&SCM reporting: Azure DataLakes. Azure DataLakes are highly complex and designed with a different fundamental purpose in mind than financial and operational reporting. Datalakes are not a mature technology.
The landscape of bigdata management has been transformed by the rising popularity of open table formats such as Apache Iceberg, Apache Hudi, and Linux Foundation Delta Lake. These formats, designed to address the limitations of traditional data storage systems, have become essential in modern data architectures.
Enterprise data is brought into datalakes and data warehouses to carry out analytical, reporting, and data science use cases using AWS analytical services like Amazon Athena , Amazon Redshift , Amazon EMR , and so on. About the author Naidu Rongal i is a BigData and ML engineer at Amazon.
Although Jira Cloud provides reporting capability, loading this data into a datalake will facilitate enrichment with other business data, as well as support the use of business intelligence (BI) tools and artificial intelligence (AI) and machine learning (ML) applications. Search for the Jira Cloud connector.
As organizations across the globe are modernizing their data platforms with datalakes on Amazon Simple Storage Service (Amazon S3), handling SCDs in datalakes can be challenging.
Amazon Redshift is a fast, scalable, and fully managed cloud data warehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. It also helps you securely access your data in operational databases, datalakes, or third-party datasets with minimal movement or copying of data.
You can download the results as JSON or CSV files using the download icon at the bottom of the output cell. The sample data includes a column star_rating representing a 5-star rating for products. About the Authors Chiho Sugimoto is a Cloud Support Engineer on the AWS BigData Support team. Choose Run all.
Events and many other security data types are stored in Imperva’s Threat Research Multi-Region datalake. Imperva harnesses data to improve their business outcomes. As part of their solution, they are using Amazon QuickSight to unlock insights from their data.
AWS Glue provides an extensible architecture that enables users with different data processing use cases. A common use case is building datalakes on Amazon Simple Storage Service (Amazon S3) using AWS Glue extract, transform, and load (ETL) jobs. On the AWS Glue console, choose Jobs in the navigation plane.
Verify all table metadata is stored in the AWS Glue Data Catalog. Consume data with Athena or Amazon EMR Trino for business analysis. Update and delete source records in Amazon RDS for MySQL and validate the reflection of the datalake tables. the Flink table API/SQL can integrate with the AWS Glue Data Catalog.
This streamlined method not only makes the implementation of SCD Type-2 more straightforward, but also offers improved performance and scalability for handling large volumes of historical data in CDC scenarios. Select the following JAR files from the Iceberg releases page and download these JAR files on your local machine: 1.6.1
With Amazon EMR 6.15, we launched AWS Lake Formation based fine-grained access controls (FGAC) on Open Table Formats (OTFs), including Apache Hudi, Apache Iceberg, and Delta lake. Many large enterprise companies seek to use their transactional datalake to gain insights and improve decision-making.
It manages large collections of files as tables, and it supports modern analytical datalake operations such as record-level insert, update, delete, and time travel queries. Download the dataset, unzip it to your local computer, and upload it to your S3 bucket.
New feature: Custom AWS service blueprints Previously, Amazon DataZone provided default blueprints that created AWS resources required for datalake, data warehouse, and machine learning use cases. Downloading these files individually would be a tedious and time-consuming process for Amazon DataZone users.
One of the bank’s key challenges related to strict cybersecurity requirements is to implement field level encryption for personally identifiable information (PII), Payment Card Industry (PCI), and data that is classified as high privacy risk (HPR). Only users with required permissions are allowed to access data in clear text.
Before they can fully realize the benefits of the cloud, they have had to adjust to new data models and new processes. Eventual consistency and other pitfalls can be a nightmare for engineers trying to migrate complex bigdata infrastructure to the cloud. Download Cloudera Altus Director and experience ADLS Gen2 now.
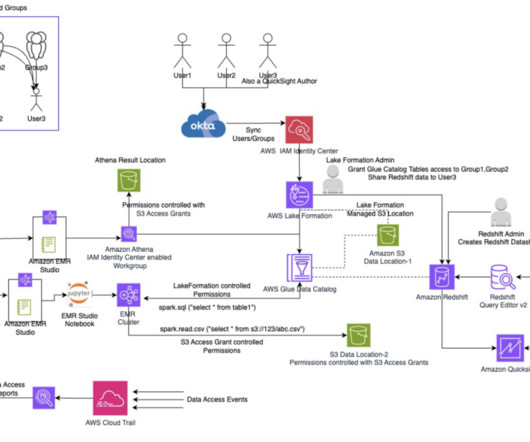
You can download the following sample certificate to use in this post. Grant access to User1 in Lake Formation Sign in to the Lake Formation console, choose Datalake permissions in the navigation pane, and grant access to the user group on the database oktank_tipblog_temp and table customer.
AWS-powered datalakes, supported by the unmatched availability of Amazon Simple Storage Service (Amazon S3), can handle the scale, agility, and flexibility required to combine different data and analytics approaches. For more information, refer to the Delete Object permissions section in Amazon S3 actions.
Because Apache Hive was built on top of Apache Hadoop, many organizations have been using the software from the time they have been using Hadoop for bigdata processing. Also, Hive metastore provides flexible integration with many other open-source bigdata software like Apache HBase, Apache Spark, Presto, and Apache Impala.
Finding similar columns in a datalake has important applications in data cleaning and annotation, schema matching, data discovery, and analytics across multiple data sources. You can download the code tutorial from GitHub to try this solution on sample data or your own data.
Today, customers are embarking on data modernization programs by migrating on-premises data warehouses and datalakes to the AWS Cloud to take advantage of the scale and advanced analytical capabilities of the cloud. Compare ongoing data that is replicated from the source on-premises database to the target S3 datalake.
Datalakes are designed for storing vast amounts of raw, unstructured, or semi-structured data at a low cost, and organizations share those datasets across multiple departments and teams. The queries on these large datasets read vast amounts of data and can perform complex join operations on multiple datasets.
Using S3Credentials1 , the function lists the S3 files stored in the table location S3 prefix and downloads them. The retrieved Amazon S3 data is filtered to remove those columns and rows that the user is not allowed access to (authorized columns and row filters were retrieved in Step 5) and authorized data is returned to the user.
When setting out to build a data warehouse, it’s a common pattern to have a datalake as the source of the data warehouse. The datalake in this context serves a number of important functions: It acts as a central source for multiple applications, not just exclusively for data warehousing purposes.
Many organizations are building datalakes to store and analyze large volumes of structured, semi-structured, and unstructured data. In addition, many teams are moving towards a data mesh architecture, which requires them to expose their data sets as easily consumable data products. YOUR-REGION}.amazonaws.com/{STAGE}
Now the CloudWatch data source has been registered. Copy the data source ID from the URL [link].amazonaws.com/datasources/edit/ Download the Grafana template. Replace in the JSON file with your Grafana data source ID. About the Authors Noritaka Sekiyama is a Principal BigData Architect on the AWS Glue team.
You might be modernizing your data architecture using Amazon Redshift to enable access to your datalake and data in your data warehouse, and are looking for a centralized and scalable way to define and manage the data access based on IdP identities. Download the.yml file or launch the CloudFormation stack.
With AWS Glue, you can discover and connect to hundreds of diverse data sources and manage your data in a centralized data catalog. It enables you to visually create, run, and monitor extract, transform, and load (ETL) pipelines to load data into your datalakes. Kamen Sharlandjiev is a Sr.
For the code to work, the data in it’s CSV format should be placed into the data subfolder. The dataset can be downloaded from: [link]. Data Ingestion. The raw data is in a series of CSV files. We will firstly convert this to parquet format as most datalakes exist as object stores full of parquet files.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content