This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Customer concerns about old apps At Ensono, Klingbeil runs a customer advisory board, with CIOs from the banking and insurance industries well represented. Banking and insurance are two industries still steeped in the use of mainframes, and Ensono manages mainframes for several customers. We are in mid-transition, Stone says.
A modern data architecture is an evolutionary architecture pattern designed to integrate a datalake, data warehouse, and purpose-built stores with a unified governance model. The company wanted the ability to continue processing operational data in the secondary Region in the rare event of primary Region failure.
While this blog post helps you to get started using Amazon Redshift with Amazon S3 Tables, there are additional steps you need to consider when working with your data in production environments, including who has access to your data and with what level of permissions.
Data analytics on operational data at near-real time is becoming a common need. Due to the exponential growth of data volume, it has become common practice to replace read replicas with datalakes to have better scalability and performance. For more information, see Changing the default settings for your datalake.
In today’s data-driven world , organizations are constantly seeking efficient ways to process and analyze vast amounts of information across datalakes and warehouses. This post will showcase how this data can also be queried by other data teams using Amazon Athena. Verify that you have Python version 3.7
This post is co-authored by Vijay Gopalakrishnan, Director of Product, Salesforce Data Cloud. In today’s data-driven business landscape, organizations collect a wealth of data across various touch points and unify it in a central data warehouse or a datalake to deliver business insights.
Many customers need an ACID transaction (atomic, consistent, isolated, durable) datalake that can log change data capture (CDC) from operational data sources. There is also demand for merging real-time data into batch data. Delta Lake framework provides these two capabilities.
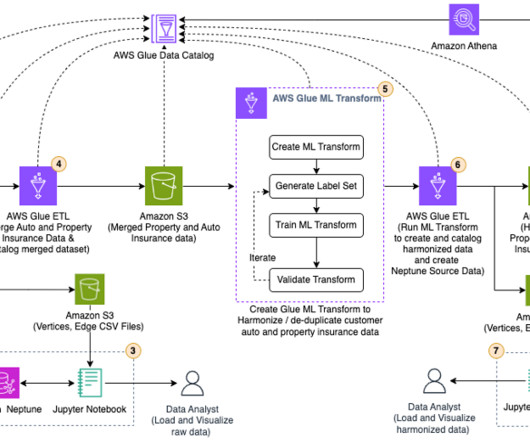
Companies are faced with the daunting task of ingesting all this data, cleansing it, and using it to provide outstanding customer experience. Typically, companies ingest data from multiple sources into their datalake to derive valuable insights from the data. The following diagram shows our solution architecture.
There were thousands of attendees at the event – lining up for book signings and meetings with recruiters to fill the endless job openings for developers experienced with MapReduce and managing BigData. This was the gold rush of the 21st century, except the gold was data.
It ingests data from both streaming and batch sources and organizes it into logical tables distributed across multiple nodes in a Pinot cluster, ensuring scalability. Pinot provides functionality similar to other modern bigdata frameworks, supporting SQL queries, upserts, complex joins, and various indexing options.
Compute scales based on data volume. Use case 3 – A datalake query scanning large datasets (TBs). Compute scales based on the expected data to be scanned from the datalake. The expected data scan is predicted by machine learning (ML) models based on prior historical run statistics.
The bank and its subsidiaries offer a broad array of commercial banking, specialist financial and wealth management services, ranging from consumer, corporate, investment, private and transaction banking to treasury, insurance, asset management and stockbroking services. Real-time data analysis for better business and customer solutions.
“We’ve been able to create some models that will analyze things like the listing comments and descriptions and tell you which properties are waterfront or not,” Wilhemy says, adding that such data gives its agents a competitive advantage by enabling them to reach out to a selective set of potential buyers first.
With Itzik’s wisdom fresh in everyone’s minds, Scott Castle, Sisense General Manager, Data Business, shared his view on the role of modern data teams. Scott whisked us through the history of business intelligence from its first definition in 1958 to the current rise of BigData. A true unicorn.
Amazon Redshift integrates with AWS HealthLake and datalakes through Redshift Spectrum and Amazon S3 auto-copy features, enabling you to query data directly from files on Amazon S3. This means you no longer have to create an external schema in Amazon Redshift to use the datalake tables cataloged in the Data Catalog.
We are excited to announce the General Availability of AWS Glue Data Quality. Our journey started by working backward from our customers who create, manage, and operate datalakes and data warehouses for analytics and machine learning. DeeQu is optimized to run data quality rules in minimal passes that makes it efficient.
The rule requires health insurers to provide clear and concise information to consumers about their health plan benefits, including costs and coverage details. The Transparency in Coverage rule also requires insurers to make available data files that contain detailed information on the prices they negotiate with health care providers.
We also have some primary insurance entities in the group, but the main thing about reinsurance is that we’re taking care of the big and complex risks in the world. A lot of people in our audience are looking at implementing datalakes or are in the middle of bigdatalake initiatives.
The details of each step are as follows: Populate the Amazon Redshift Serverless data warehouse with company stock information stored in Amazon Simple Storage Service (Amazon S3). Redshift Serverless is a fully functional data warehouse holding data tables maintained in real time.
A data hub contains data at multiple levels of granularity and is often not integrated. It differs from a datalake by offering data that is pre-validated and standardized, allowing for simpler consumption by users. Data hubs and datalakes can coexist in an organization, complementing each other.
At the heart of all data warehousing is integration, and this layer contains integrated data from multiple sources built around the enterprise-wide business keys. Although datalakes resemble data vaults, a data vault provides more features of a data warehouse.
With this integration, customers can now harness the full power of Azure’s BigData offerings in a self-service manner to gain immediate value.”. This highlights the two companies’ shared vision on self-service data discovery with an emphasis on collaboration and data governance.
“We hear little about initiatives devoted to changing human attitudes and behaviors around data. Unless the focus shifts to these types of activities, we are likely to see the same problem areas in the future that we’ve observed year after year in this survey.” — BigData and AI Executive Survey 2019.
They’re built on machine learning algorithms that create outputs based on an organization’s data or other third-party bigdata sources. Sometimes, these outputs are biased because the data used to train the model was incomplete or inaccurate in some way.
Analytics Specialist Solutions Architect based out of Atlanta, specialized in building enterprise data platforms, data warehousing, and analytics solutions. He has over 17 years of experience in building data assets and leading complex data platform programs for banking and insurance clients across the globe.
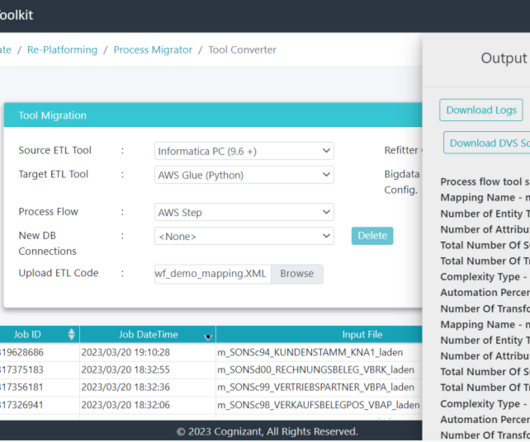
As part of this engagement, Cognizant helped the customer successfully migrate their Informatica based data acquisition and integration ETL jobs and workflows to AWS.
This functionality provides access to data by storing it in an open format, increasing flexibility for data exploration and ML modeling used by data scientists, facilitating governed data use of unstructured data, improving collaboration, and reducing data silos with simplified datalake integration.
sales conversation summaries, insurance coverage, meeting transcripts, contract information) Generate: Generate text content for a specific purpose, such as marketing campaigns, job descriptions, blogs or articles, and email drafting support.
Secure databases in the physical data center, bigdata platforms and the cloud. To comply with data protection regulations, highly regulated industries require organizations to maintain high data security. In 2022, it took an average of 277 days to identify and contain a data breach.
In our modern architectures, replete with web-services, APIs, cloud-based components and the quasi-instantaneous transmission of new transactions, it is perhaps not surprising that occasionally some data gets lost in translation [5] along the way. I explore some similar themes in a section of Data Visualisation – A Scientific Treatment.
As such banking, finance, insurance and media are good examples of information-based industries compared to manufacturing, retail, and so on. Does Data warehouse as a software tool will play role in future of Data & Analytics strategy? Datalakes don’t offer this nor should they.
That was the Science, here comes the Technology… A Brief Hydrology of DataLakes. Overlapping with the above, from around 2012, I began to get involved in also designing and implementing BigData Architectures; initially for narrow purposes and later DataLakes spanning entire enterprises.
Furthermore, all research data was made more easily available to a wider group of researchers, giving scientists the capability to deep dive on pharma analytics. . Insurance. New data scientists can then be onboarded more easily and efficiently. Find out more about Cloudera Data Platform here. . Oil and Gas.
These organizations have a huge demand for lakehouse solutions that combine the best of data warehouses and datalakes to simplify data management with easy access to all data from their preferred engines. Stefano Sandon is a Senior BigData Specialist Solution Architect at Amazon Web Services (AWS).
About the Authors Raj Ramasubbu is a Senior Analytics Specialist Solutions Architect focused on bigdata and analytics and AI/ML with Amazon Web Services. Ismail Makhlouf is a Senior Specialist Solutions Architect for Data Analytics at AWS. This post is cowritten with Mayank Shrivastava and Barkha Herman from StarTree.
Amazon Redshift supports querying data stored using Apache Iceberg tables , an open table format that simplifies management of tabular data residing in datalakes on Amazon Simple Storage Service (Amazon S3). Note Amazon Redshift is just one option for querying data stored in S3 Tables.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content