This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Redshift is a fast, fully managed cloud data warehouse that makes it cost-effective to analyze your data using standard SQL and business intelligence tools. Customers use datalake tables to achieve cost effective storage and interoperability with other tools. The sample files are ‘|’ delimited text files.
The need for streamlined data transformations As organizations increasingly adopt cloud-based datalakes and warehouses, the demand for efficient data transformation tools has grown. Using Athena and the dbt adapter, you can transform raw data in Amazon S3 into well-structured tables suitable for analytics.
Amazon DataZone now launched authentication supports through the Amazon Athena JDBC driver, allowing data users to seamlessly query their subscribed datalake assets via popular business intelligence (BI) and analytics tools like Tableau, Power BI, Excel, SQL Workbench, DBeaver, and more. Choose Test connection.
DataLakes are among the most complex and sophisticated data storage and processing facilities we have available to us today as human beings. Analytics Magazine notes that datalakes are among the most useful tools that an enterprise may have at its disposal when aiming to compete with competitors via innovation.
Azure DataLake Storage Gen2 is based on Azure Blob storage and offers a suite of bigdata analytics features. If you don’t understand the concept, you might want to check out our previous article on the difference between datalakes and data warehouses. Then, move your data.
A datalake is a centralized repository that you can use to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data and then run different types of analytics for better business insights. They are the same.
Initially, data warehouses were the go-to solution for structured data and analytical workloads but were limited by proprietary storage formats and their inability to handle unstructured data. Eventually, transactional datalakes emerged to add transactional consistency and performance of a data warehouse to the datalake.
Datalakes have been gaining popularity for storing vast amounts of data from diverse sources in a scalable and cost-effective way. As the number of data consumers grows, datalake administrators often need to implement fine-grained access controls for different user profiles.
Iceberg has become very popular for its support for ACID transactions in datalakes and features like schema and partition evolution, time travel, and rollback. and later supports the Apache Iceberg framework for datalakes. AWS Glue 3.0 The following diagram illustrates the solution architecture.
Apache Iceberg brings the reliability and simplicity of SQL tables to bigdata, while making it possible for processing engines such as Apache Spark, Trino, Apache Flink, Presto, Apache Hive, and Impala to safely work with the same tables at the same time.
A modern data architecture enables companies to ingest virtually any type of data through automated pipelines into a datalake, which provides highly durable and cost-effective object storage at petabyte or exabyte scale.
response = client.create( key="test", value="Test value", description="Test description" ) print(response) print("nListing all variables.") variables = client.list() print(variables) print("nGetting the test variable.") Creating a test variable. Creating a test variable. Creating a test variable.
The combination of a datalake in a serverless paradigm brings significant cost and performance benefits. By monitoring application logs, you can gain insights into job execution, troubleshoot issues promptly to ensure the overall health and reliability of data pipelines.
Amazon Redshift enables you to efficiently query and retrieve structured and semi-structured data from open format files in Amazon S3 datalake without having to load the data into Amazon Redshift tables. Amazon Redshift extends SQL capabilities to your datalake, enabling you to run analytical queries.
Over the years, organizations have invested in creating purpose-built, cloud-based datalakes that are siloed from one another. A major challenge is enabling cross-organization discovery and access to data across these multiple datalakes, each built on different technology stacks.
For many organizations, this centralized data store follows a datalake architecture. Although datalakes provide a centralized repository, making sense of this data and extracting valuable insights can be challenging. We recommend testing your use case and data with different models.
Today, Amazon Redshift is used by customers across all industries for a variety of use cases, including data warehouse migration and modernization, near real-time analytics, self-service analytics, datalake analytics, machine learning (ML), and data monetization.
A modern data architecture is an evolutionary architecture pattern designed to integrate a datalake, data warehouse, and purpose-built stores with a unified governance model. The company wanted the ability to continue processing operational data in the secondary Region in the rare event of primary Region failure.
In this post, we delve into the key aspects of using Amazon EMR for modern data management, covering topics such as data governance, data mesh deployment, and streamlined data discovery. Organizations have multiple Hive data warehouses across EMR clusters, where the metadata gets generated.
The DataFrame code generation now extends beyond AWS Glue DynamicFrame to support a broader range of data processing scenarios. Upon checking the S3 data target, we can see the S3 path is now a placeholder and the output format is Parquet. Stuti Deshpande is a BigData Specialist Solutions Architect at AWS.
It’s been one decade since the “ BigData Era ” began (and to much acclaim!). Analysts asked, What if we could manage massive volumes and varieties of data? Yet the question remains: How much value have organizations derived from bigdata? BigData as an Enabler of Digital Transformation.
Datalakes are a popular choice for today’s organizations to store their data around their business activities. As a best practice of a datalake design, data should be immutable once stored. A datalake built on AWS uses Amazon Simple Storage Service (Amazon S3) as its primary storage environment.
When you build your transactional datalake using Apache Iceberg to solve your functional use cases, you need to focus on operational use cases for your S3 datalake to optimize the production environment. availability. Note the configuration parameters s3.write.tags.write-tag-name write.tags.write-tag-name and s3.delete.tags.delete-tag-name
These features allow efficient data corrections, gap-filling in time series, and historical data updates without disrupting ongoing analyses or compromising data integrity. Unlike direct Amazon S3 access, Iceberg supports these operations on petabyte-scale datalakes without requiring complex custom code.
Testing these upgrades involves running the application and addressing issues as they arise. Each test run may reveal new problems, resulting in multiple iterations of changes. About the Authors Noritaka Sekiyama is a Principal BigData Architect on the AWS Glue team. Python 3.7) to Spark 3.3.0
The term “BigData” has lost its relevance. The fact remains, though: every dataset is becoming a BigData set, whether its owners and users know (and understand) that or not. BigData isn’t just something that happens to other people or giant companies like Google and Amazon. BigData Today.
As organizations across the globe are modernizing their data platforms with datalakes on Amazon Simple Storage Service (Amazon S3), handling SCDs in datalakes can be challenging.
Data-driven organizations treat data as an asset and use it across different lines of business (LOBs) to drive timely insights and better business decisions. This leads to having data across many instances of data warehouses and datalakes using a modern data architecture in separate AWS accounts.
Enterprise data is brought into datalakes and data warehouses to carry out analytical, reporting, and data science use cases using AWS analytical services like Amazon Athena , Amazon Redshift , Amazon EMR , and so on. About the author Naidu Rongal i is a BigData and ML engineer at Amazon.
For each service, you need to learn the supported authorization and authentication methods, data access APIs, and framework to onboard and testdata sources. This approach simplifies your data journey and helps you meet your security requirements. Noritaka Sekiyama is a Principal BigData Architect on the AWS Glue team.
Amazon Athena supports the MERGE command on Apache Iceberg tables, which allows you to perform inserts, updates, and deletes in your datalake at scale using familiar SQL statements that are compliant with ACID (Atomic, Consistent, Isolated, Durable).
Amazon DataZone recently announced the expansion of data analysis and visualization options for your project-subscribed data within Amazon DataZone using the Amazon Athena JDBC driver.
Bigdata is shaping our world in countless ways. Data powers everything we do. Exactly why, the systems have to ensure adequate, accurate and most importantly, consistent data flow between different systems. A point of data entry in a given pipeline. Data Pipeline: Use Cases. Destination.
Storage plays one of the most important roles in the data platforms strategy, it provides the basis for all compute engines and applications to be built on top of it. Cloudera and Cisco have tested together with dense storage nodes to make this a reality. . This CVD is built using Cloudera Data Platform Private Cloud Base 7.1.5
In our previous post Improve operational efficiencies of Apache Iceberg tables built on Amazon S3 datalakes , we discussed how you can implement solutions to improve operational efficiencies of your Amazon Simple Storage Service (Amazon S3) datalake that is using the Apache Iceberg open table format and running on the Amazon EMR bigdata platform.
Analytics remained one of the key focus areas this year, with significant updates and innovations aimed at helping businesses harness their data more efficiently and accelerate insights. From enhancing datalakes to empowering AI-driven analytics, AWS unveiled new tools and services that are set to shape the future of data and analytics.
Today, we are pleased to announce new AWS Glue connectors for Azure Blob Storage and Azure DataLake Storage that allow you to move data bi-directionally between Azure Blob Storage, Azure DataLake Storage, and Amazon Simple Storage Service (Amazon S3). option("header","true").load("wasbs://yourblob@youraccountname.blob.core.windows.net/loadingtest-input/100mb")
Data architect Armando Vázquez identifies eight common types of data architects: Enterprise data architect: These data architects oversee an organization’s overall data architecture, defining data architecture strategy and designing and implementing architectures.
Data governance is the process of ensuring the integrity, availability, usability, and security of an organization’s data. Due to the volume, velocity, and variety of data being ingested in datalakes, it can get challenging to develop and maintain policies and procedures to ensure data governance at scale for your datalake.
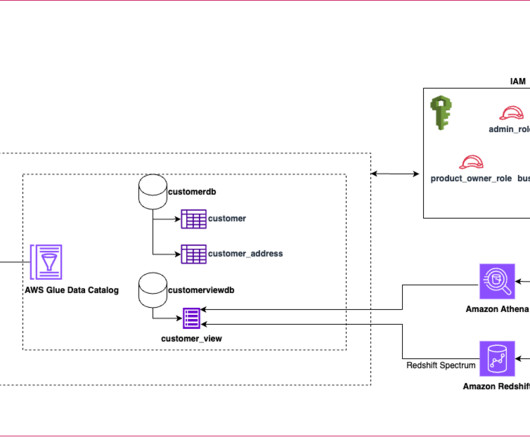
Today’s datalakes are expanding across lines of business operating in diverse landscapes and using various engines to process and analyze data. Traditionally, SQL views have been used to define and share filtered data sets that meet the requirements of these lines of business for easier consumption. Choose Grant.
As enterprises collect increasing amounts of data from various sources, the structure and organization of that data often need to change over time to meet evolving analytical needs. Schema evolution enables adding, deleting, renaming, or modifying columns without needing to rewrite existing data.
We have seen a strong customer demand to expand its scope to cloud-based datalakes because datalakes are increasingly the enterprise solution for large-scale data initiatives due to their power and capabilities. Let’s say that this company is located in Europe and the data product must comply with the GDPR.
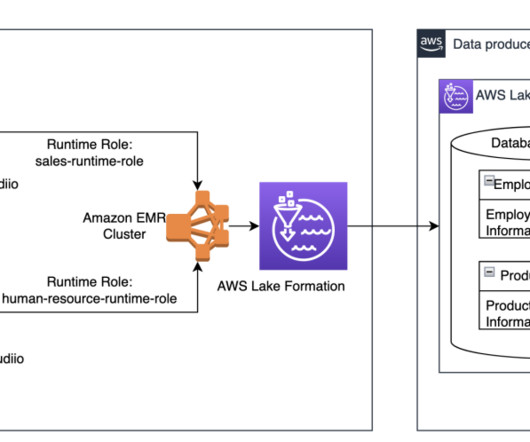
You can attach an EMR Studio Workspace to an EMR cluster, and use the compute power of the EMR cluster and run data science jobs on the cluster. Data is often stored in datalakes managed by AWS Lake Formation , enabling you to apply fine-grained access control through a simple grant or revoke mechanism.
Let’s go through the ten Azure data pipeline tools Azure Data Factory : This cloud-based data integration service allows you to create data-driven workflows for orchestrating and automating data movement and transformation. You can use it for bigdata analytics and machine learning workloads.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content