This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Containerizing is all about bundling up a software application/service and isolating it from the host environment […] The post Top 4 Cloud Platforms to Host or Run Docker Containers for Free appeared first on Analytics Vidhya.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis.
You can now generate data integration jobs for various data sources and destinations, including Amazon Simple Storage Service (Amazon S3) data lakes with popular file formats like CSV, JSON, and Parquet, as well as modern table formats such as Apache Hudi , Delta , and Apache Iceberg.
Piperr.io — Pre-built data pipelines across enterprise stakeholders, from IT to analytics, tech, data science and LoBs. Prefect Technologies — Open-source data engineering platform that builds, tests, and runs data workflows. Genie — Distributed bigdata orchestration service by Netflix.
Amazon Redshift is a fast, scalable, and fully managed cloud datawarehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. The system had an integration with legacy backend services that were all hosted on premises. The downside here is over-provisioning.
Dating back to the 1970s, the data warehousing market emerged when computer scientist Bill Inmon first coined the term ‘datawarehouse’. Created as on-premise servers, the early datawarehouses were built to perform on just a gigabyte scale. Bigdata and data warehousing.
With Amazon Redshift, you can use standard SQL to query data across your datawarehouse, operational data stores, and data lake. Migrating a datawarehouse can be complex. You have to migrate terabytes or petabytes of data from your legacy system while not disrupting your production workload.
“Without bigdata, you are blind and deaf and in the middle of a freeway.” – Geoffrey Moore, management consultant, and author. In a world dominated by data, it’s more important than ever for businesses to understand how to extract every drop of value from the raft of digital insights available at their fingertips.
Tens of thousands of customers use Amazon Redshift for modern data analytics at scale, delivering up to three times better price-performance and seven times better throughput than other cloud datawarehouses. About the Authors Songzhi Liu is a Principal BigData Architect with the AWS Identity Solutions team.
The applications are hosted in dedicated AWS accounts and require a BI dashboard and reporting services based on Tableau. AWS Database Migration Service (AWS DMS) is used to securely transfer the relevant data to a central Amazon Redshift cluster. Lakshmi Nair is a Senior Specialist Solutions Architect for Data Analytics at AWS.
Amazon Redshift is the most widely used datawarehouse in the cloud, best suited for analyzing exabytes of data and running complex analytical queries. Amazon QuickSight is a fast business analytics service to build visualizations, perform ad hoc analysis, and quickly get business insights from your data.
Seeds – These are CSV files in your dbt project (typically in your seeds directory), which dbt can load into your datawarehouse using the dbt seed command. This includes the host, port, database name, user name, and password. An Amazon Simple Storage (Amazon S3) bucket to host documentation files. project-dir.
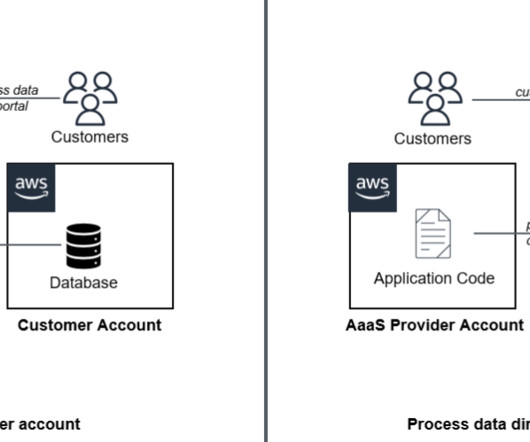
The AaaS model accelerates data-driven decision-making through advanced analytics, enabling organizations to swiftly adapt to changing market trends and make informed strategic choices. times better price-performance than other cloud datawarehouses. Data processing jobs enrich the data in Amazon Redshift.
In today’s world, datawarehouses are a critical component of any organization’s technology ecosystem. The rise of cloud has allowed datawarehouses to provide new capabilities such as cost-effective data storage at petabyte scale, highly scalable compute and storage, pay-as-you-go pricing and fully managed service delivery.
Moreover, a host of ad hoc analysis or reporting platforms boast integrated online data visualization tools to help enhance the data exploration process. Without bigdata, you are blind and deaf and in the middle of a freeway.” – Geoffrey Moore. The Benefits Of Ad Hoc Reporting And Analysis. ” – John Dryden.
The Bureau of Labor Statistics estimates that the number of data scientists will increase from 32,700 to 37,700 between 2019 and 2029. Unfortunately, despite the growing interest in bigdata careers, many people don’t know how to pursue them properly. It hosts a data analysis competition. Use Kaggle.
In this post, we delve into the key aspects of using Amazon EMR for modern data management, covering topics such as data governance, data mesh deployment, and streamlined data discovery. Organizations have multiple Hive datawarehouses across EMR clusters, where the metadata gets generated.
Large-scale datawarehouse migration to the cloud is a complex and challenging endeavor that many organizations undertake to modernize their data infrastructure, enhance data management capabilities, and unlock new business opportunities. This makes sure the new data platform can meet current and future business goals.
Access to an SFTP server with permissions to upload and download data. If the SFTP server is hosted on Amazon Elastic Compute Cloud (Amazon EC2) , we recommend that the network communication between the SFTP server and the AWS Glue job happens within the virtual private cloud (VPC) as pictured in the preceding architecture diagram.
Amazon Redshift is a fully managed, petabyte-scale datawarehouse service in the cloud. You can start with just a few hundred gigabytes of data and scale to a petabyte or more. This enables you to use your data to acquire new insights for your business and customers. Document the entire disaster recovery process.
Amazon Redshift is a fast, fully managed, petabyte-scale datawarehouse that provides the flexibility to use provisioned or serverless compute for your analytical workloads. Modern analytics is much wider than SQL-based data warehousing. You can get faster insights without spending valuable time managing your datawarehouse.
Since the deluge of bigdata over a decade ago, many organizations have learned to build applications to process and analyze petabytes of data. Data lakes have served as a central repository to store structured and unstructured data at any scale and in various formats.
Typically, you have multiple accounts to manage and run resources for your data pipeline. About the Authors Noritaka Sekiyama is a Principal BigData Architect on the AWS Glue team. He is passionate about building scalable distributed systems for bigdata processing, analytics, and management.
Because Gilead is expanding into biologics and large molecule therapies, and has an ambitious goal of launching 10 innovative therapies by 2030, there is heavy emphasis on using data with AI and machine learning (ML) to accelerate the drug discovery pipeline. This data volume is expected to increase monthly and is fully refreshed each month.
Amazon Redshift is a widely used, fully managed, petabyte-scale cloud datawarehouse. Tens of thousands of customers use Amazon Redshift to process exabytes of data every day to power their analytics workloads. Amazon Redshift RA3 with managed storage is the newest instance type for Provisioned clusters.
Amazon Redshift is a fast, petabyte-scale, cloud datawarehouse that tens of thousands of customers rely on to power their analytics workloads. With its massively parallel processing (MPP) architecture and columnar data storage, Amazon Redshift delivers high price-performance for complex analytical queries against large datasets.
Azure Data Lake Storage Gen2 is based on Azure Blob storage and offers a suite of bigdata analytics features. If you don’t understand the concept, you might want to check out our previous article on the difference between data lakes and datawarehouses. Conclusion.
Improved employee satisfaction: Providing business users access to data without having to contact analysts or IT can reduce friction, increase productivity, and facilitate faster results. Increased competitive advantage: A sound BI strategy can help businesses monitor their changing market and anticipate customer needs.
Apache Hive is a distributed, fault-tolerant datawarehouse system that enables analytics at a massive scale. Spark SQL is an Apache Spark module for structured data processing. host') export PASSWORD=$(aws secretsmanager get-secret-value --secret-id $secret_name --query SecretString --output text | jq -r '.password')
It also makes it easier for engineers, data scientists, product managers, analysts, and business users to access data throughout an organization to discover, use, and collaborate to derive data-driven insights. Leonardo Gómez is a Principal BigData / ETL Solutions Architect at AWS, based in Florida, US.
This will be used temporarily to hold the data from Amazon DocumentDB for data synchronization. OpenSearch hosts – Provide the OpenSearch Service domain endpoint for the host and provide the preferred index name to store the data. He has worked with building databases and datawarehouse solutions for over 15 years.
The currently available choices include: The Amazon Redshift COPY command can load data from Amazon Simple Storage Service (Amazon S3), Amazon EMR , Amazon DynamoDB , or remote hosts over SSH. This native feature of Amazon Redshift uses massive parallel processing (MPP) to load objects directly from data sources into Redshift tables.
A CDC-based approach captures the data changes and makes them available in datawarehouses for further analytics in real-time. usually a datawarehouse) needs to reflect those changes in near real-time. This post showcases how to use streaming ingestion to bring data to Amazon Redshift.
With quality data at their disposal, organizations can form datawarehouses for the purposes of examining trends and establishing future-facing strategies. Industry-wide, the positive ROI on quality data is well understood. In that case, you can face an even bigger blowup: making costly decisions based on inaccurate data.
Amazon Redshift is a popular cloud datawarehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) data lake, real-time streams, machine learning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x
The amount of data being collected grew, and the first datawarehouses were developed. BigData” became a topic of conversations and the term “Cloud” was coined. . As businesses began to embrace digital transformation, more and more data was collected and stored. In 2008, Cloudera was born.
On the flip side, if you enjoy diving deep into the technical side of things, with the right mix of skills for business intelligence you can work a host of incredibly interesting problems that will keep you in flow for hours on end. This could involve anything from learning SQL to buying some textbooks on datawarehouses.
As the queries finish running, an UNLOAD operation is invoked from the Redshift datawarehouse to the S3 bucket in Account A. Cross-account access has been set up between S3 buckets in Account A with resources in Account B to be able to load and unload data. role_arn={5}&database={6}®ion={7}'.format(conn_type,
The connectors were only able to reference hostnames in the connector configuration or plugin that are publicly resolvable and couldn’t resolve private hostnames defined in either a private hosted zone or use DNS servers in another customer network. Many customers ensure that their internal DNS applications are not publicly resolvable.
With the launch of Amazon Redshift Serverless and the various provisioned instance deployment options , customers are looking for tools that help them determine the most optimal datawarehouse configuration to support their Amazon Redshift workloads. Enable audit logging following the guidance in Amazon Redshift Management Guide.
Amazon EMR on EC2 is a managed service that makes it straightforward to run bigdata processing and analytics workloads on AWS. With Amazon EMR, you can take advantage of the power of these bigdata tools to process, analyze, and gain valuable business intelligence from vast amounts of data.
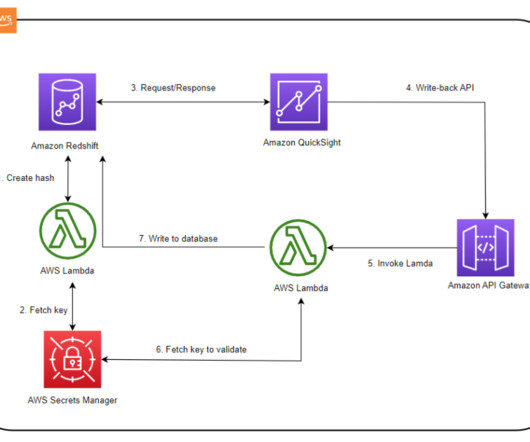
A write-back is the ability to update a data mart, datawarehouse, or any other database backend from within BI dashboards and analyze the updated data in near-real time within the dashboard itself. AnyCompany currently uses Amazon Redshift as their enterprise datawarehouse platform and QuickSight as their BI solution.
And knowing the business purpose translates into actively governing personal data against potential privacy and security violations. Do You Know Where Your Sensitive Data Is? Data is a valuable asset used to operate, manage and grow a business.
Apache Hive is a SQL-based datawarehouse system for processing highly distributed datasets on the Apache Hadoop platform. The Hive metastore is a repository of metadata about the SQL tables, such as database names, table names, schema, serialization and deserialization information, data location, and partition details of each table.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content