This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Snapshots are crucial for data backup and disaster recovery in Amazon OpenSearch Service. These snapshots allow you to generate backups of your domain indexes and cluster state at specific moments and save them in a reliable storage location such as Amazon Simple Storage Service (Amazon S3). Snapshots are not instantaneous.
This post focuses on introducing an active-passive approach using a snapshot and restore strategy. Snapshot and restore in OpenSearch Service The snapshot and restore strategy in OpenSearch Service involves creating point-in-time backups, known as snapshots , of your OpenSearch domain.
However, the data migration process can be daunting, especially when downtime and data consistency are critical concerns for your production workload. In this post, we will introduce a new mechanism called Reindexing-from-Snapshot (RFS), and explain how it can address your concerns and simplify migrating to OpenSearch.
Table of Contents 1) Benefits Of BigData In Logistics 2) 10 BigData In Logistics Use Cases Bigdata is revolutionizing many fields of business, and logistics analytics is no exception. The complex and ever-evolving nature of logistics makes it an essential use case for bigdata applications.
in Amazon OpenSearch Service , we introduced Snapshot Management , which automates the process of taking snapshots of your domain. Snapshot Management helps you create point-in-time backups of your domain using OpenSearch Dashboards, including both data and configuration settings (for visualizations and dashboards).
Snapshots – These implements type-2 slowly changing dimensions (SCDs) over mutable source tables. Seeds – These are CSV files in your dbt project (typically in your seeds directory), which dbt can load into your data warehouse using the dbt seed command. The table refresh can be full or incremental based on the configuration.
Number 6 on our list is a sales graph example that offers a detailed snapshot of sales conversion rates. With a host of interactive sales graphs and specialized charts, this sales graph template is a shining example of how to present sales data for your business. 6) Sales Conversion.
The OR1 instances use the new physical replication model, where data is indexed only on the primary copy and additional copies are created by copying data from the primary. With a high number of replica copies, the node hosting the primary copy requires significant network bandwidth, replicating the segment to all the copies.
In fact, according to eMarketer, 40% of executives surveyed in a study focused on data-driven marketing, expect to “significantly increase” revenue. Not to worry – we’ll not only explain the link between bigdata and business performance but also explore real-life performance dashboard examples and explain why you need one (or several).
With built-in features such as automated snapshots and cross-Region replication, you can enhance your disaster resilience with Amazon Redshift. Amazon Redshift supports two kinds of snapshots: automatic and manual, which can be used to recover data. Snapshots are point-in-time backups of the Redshift data warehouse.
Without bigdata analytics, companies are blind and deaf, wandering out onto the Web like deer on a freeway. Companies that use data analytics are five times more likely to make faster decisions, based on a survey conducted by Bain & Company. Geoffrey Moore, Author of Crossing the Chasm & Inside the Tornado.
Dashboards are hosted software applications that automatically pull together available data into charts and graphs that give a sense of the immediate state of the company. BI aims to deliver straightforward snapshots of the current state of affairs to business managers.
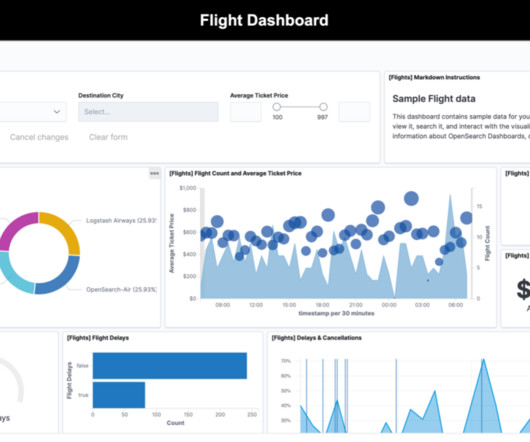
Choose the Sample flight data dataset and choose Add data. Under Generate the link as , select Snapshot and choose Copy iFrame code. f%2Cvalue%3A900000)%2Ctime%3A(from%3Anow-24h%2Cto%3Anow))" height="800" width="100%"> Host the HTML code The next step is to host the index.html file.
Bigdata plays a crucial role in online data analysis , business information, and intelligent reporting. Companies must adjust to the ambiguity of data, and act accordingly. click to enlarge**.
The Orca Platform is powered by a state-of-the-art anomaly detection system that uses cutting-edge ML algorithms and bigdata capabilities to detect potential security threats and alert customers in real time, ensuring maximum security for their cloud environment. Why did Orca choose Apache Iceberg?
When a cyberattack strikes, the ransomware code gathers information about target networks and key resources such as databases, critical files, snapshots and backups. Showing minimal activity, the threat can remain dormant for weeks or months, infecting hourly and daily snapshots and monthly full backups.
Amazon Redshift is a widely used, fully managed, petabyte-scale data warehouse service. Tens of thousands of customers use Amazon Redshift to process exabytes of data every day to power their analytics workloads. Configure Amazon Redshift Data Warehouse Create a snapshot following the guidance in the Amazon Redshift Management Guide.
Since the deluge of bigdata over a decade ago, many organizations have learned to build applications to process and analyze petabytes of data. Data lakes have served as a central repository to store structured and unstructured data at any scale and in various formats.
By managing customer data the right way, you stand to reap incredible rewards. Download right here your quick summary of the customers’ data world! Customer data management is the key to sustainable commercial success. What Is Customer Data Management (CDM)? click to enlarge**. Cost-per-Click (CPC).
An in-place migration can be performed in either of two ways: Using add_files : This procedure adds existing data files to an existing Iceberg table with a new snapshot that includes the files. Unlike migrate or snapshot, add_files can import files from a specific partition or partitions and doesn’t create a new Iceberg table.
The connectors were only able to reference hostnames in the connector configuration or plugin that are publicly resolvable and couldn’t resolve private hostnames defined in either a private hosted zone or use DNS servers in another customer network. Many customers ensure that their internal DNS applications are not publicly resolvable.
Are there any constraints on the number of databases that can be hosted on an instance? If you require hosting multiple databases per instance, connect with an IBM or AWS representative to discuss your needs and request a proof of concept. At what level are snapshot-based backups taken? Backup and restore 11. 13.
But in this digital age, dynamic modern IT reports created with a state-of-the-art online reporting tool are here to help you provide viable answers to a host of burning departmental questions. Bigdata is at the foundation of all of the megatrends that are happening today, from social to mobile to the cloud to gaming.” – Chris Lynch.
You can install OpenSearch Benchmark directly on a host running Linux or macOS , or you can run OpenSearch Benchmark in a Docker container on any compatible host. In this post, we deployed OpenSearch Benchmark in an AWS Cloud9 host using an Amazon Linux 2 instance type m6i.2xlarge
This means that there is out of the box support for Ozone storage in services like Apache Hive , Apache Impala, Apache Spark, and Apache Nifi, as well as in Private Cloud experiences like Cloudera Machine Learning (CML) and Data Warehousing Experience (DWX). awsAccessKey=s3-spark-user/HOST@REALM.COM. awsSecret=08b6328818129677247d51.
This solution uses Amazon Aurora MySQL hosting the example database salesdb. Valid values for OP field are: c = create u = update d = delete r = read (applies to only snapshots) The following diagram illustrates the solution architecture: The solution workflow consists of the following steps: Amazon Aurora MySQL has a binary log (i.e.,
Automated backup Amazon Redshift automatically takes incremental snapshots that track changes to the data warehouse since the previous automated snapshot. Automated snapshots retain all of the data required to restore a data warehouse from a snapshot.
Solution overview Typically, you have multiple accounts to manage and provision resources for your data pipeline. About the author Noritaka Sekiyama is a Principal BigData Architect on the AWS Glue team. rename_field('id', 'org_id').rename_field('name', He works based in Tokyo, Japan.
During the upgrade process, Amazon MWAA captures a snapshot of your environment metadata; upgrades the workers, schedulers, and web server to the new Airflow version; and finally restores the metadata database using the snapshot, backing it with an automated rollback mechanism.
Redshift Test Drive also provides additional features such as a self-hosted analysis UI and the ability to replicate external objects that a Redshift workload may interact with. Compare replay performance Redshift Test Drive also provides the ability to compare the replay runs visually using a self-hosted UI tool.
Modern analytics is much wider than SQL-based data warehousing. With Amazon Redshift, you can build lake house architectures and perform any kind of analytics, such as interactive analytics , operational analytics , bigdata processing , visual data preparation , predictive analytics, machine learning , and more.
A host with the installed MySQL utility, such as an Amazon Elastic Compute Cloud (Amazon EC2) instance, AWS Cloud9 , your laptop, and so on. The host is used to access an Amazon Aurora MySQL-Compatible Edition cluster that you create and to run a Python script that sends sample records to the Kinesis data stream. mode("append").save(s3_output_folder)
Frequent materialized view refreshes on top of constantly changing base tables due to streamed data can lead to snapshot isolation errors. Also, a data model that allows table truncations at a regular frequency (for example, every 15 seconds) to store only relevant data in tables can cause locking and performance issues.
With each crawler run, the crawler inspects each of the S3 paths and catalogs the schema information, such as new tables, deletes, and updates to schemas in the Data Catalog. Crawlers support schema merging across all snapshots and update the latest metadata file location in the Data Catalog that AWS analytical engines can directly use.
The data from the Kinesis data stream is consumed by two applications: A Spark streaming application on Amazon EMR is used to write data from the Kinesis data stream to a data lake hosted on Amazon Simple Storage Service (Amazon S3) in a partitioned way.
The following figure shows a daily query volume snapshot (queries per day and queued queries per day, which waited a minimum of 5 seconds). Redshift Test Drive also provides additional features such as a self-hosted analysis UI and the ability to replicate external objects that a Redshift workload may interact with.
Kubernetes schedules and automates container-related tasks throughout the application lifecycle, including: Deployment Kubernetes can deploy a specific number of containers to a specific host and keep them running in their desired state. Rollouts A rollout is a Kubernetes deployment modification.
You can then apply transformations and store data in Delta format for managing inserts, updates, and deletes. Amazon EMR Serverless is a serverless option in Amazon EMR that makes it easy for data analysts and engineers to run open-source bigdata analytics frameworks without configuring, managing, and scaling clusters or servers.
salesdb.sql Connect to the RDS for MySQL database and run the salesdb.sql command to initialize the database, providing the host name and user name according to your RDS for MySQL database configuration: mysql -h -u -p mysql> source salesdb.sql Create an EMR cluster with the AWS Glue Data Catalog From Amazon EMR 6.9.0,
Presently, the Kinesis Data Analytics for Apache Flink application requires the creation of a new Kinesis Data Analytics for Apache Flink application. The team then will host business logic provided by other departments in Klarna such as Fraud Prevention.
At present, 53% of businesses are in the process of adopting bigdata analytics as part of their core business strategy – and it’s no coincidence. To win on today’s information-rich digital battlefield, turning insight into action is a must, and online data analysis tools are the very vessel for doing so.
HBase can run on Hadoop Distributed File System (HDFS) or Amazon Simple Storage Service (Amazon S3) , and can host very large tables with billions of rows and millions of columns. Running HBase on Amazon S3 has several added benefits, including lower costs, data durability, and easier scalability.
For Available load balancers , select the load balancer you created in the last step From Supported Regions, select an additional region if Data Cloud isnt hosted in the same AWS region as the Redshift instance. For Load balancer type , choose Network. For additional settings leave Acceptance required.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content