This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
One was to build a lot of state-handling services that each consisted of a few containers, each housing a fair bit of data. They don’t move easily, but because each service contains just a few containers, statistical variations in load create havoc for neighboring containers creating a need to move them. The implications for bigdata.
“Bigdata is at the foundation of all the megatrends that are happening.” – Chris Lynch, bigdata expert. We live in a world saturated with data. Zettabytes of data are floating around in our digital universe, just waiting to be analyzed and explored, according to AnalyticsWeek. At present, around 2.7
With so much data and so little time, knowing how to collect, curate, organize, and make sense of all of this potentially business-boosting information can be a minefield – but online data analysis is the solution. Conduct statistical analysis. One of the most pivotal types of data analysis methods is statistical analysis.
The world now runs on BigData. Defined as information sets too large for traditional statistical analysis, BigData represents a host of insights businesses can apply towards better practices. But what exactly are the opportunities present in bigdata? In manufacturing, this means opportunity.
Today, we’re making available a new capability of AWS Glue Data Catalog that allows generating column-level statistics for AWS Glue tables. These statistics are now integrated with the cost-based optimizers (CBO) of Amazon Athena and Amazon Redshift Spectrum , resulting in improved query performance and potential cost savings.
Bigdata is the lynchpin of new advances in cybersecurity. Datanami has talked about the ways that hackers use bigdata to coordinate attacks. Datanami has talked about the ways that hackers use bigdata to coordinate attacks. Sadowski said bigdata is to blame for a growing number of cyberattacks.
Operations data: Data generated from a set of operations such as orders, online transactions, competitor analytics, sales data, point of sales data, pricing data, etc. The gigantic evolution of structured, unstructured, and semi-structured data is referred to as Bigdata. BigData Ingestion.
The Data Scientist profession today is often considered to be one of the most promising and lucrative. The Bureau of Labor Statistics estimates that the number of data scientists will increase from 32,700 to 37,700 between 2019 and 2029. Previously, such problems were dealt with by specialists in mathematics and statistics.
An analytical report is a type of a business report that uses qualitative and quantitative company data to analyze as well as evaluate a business strategy or process while empowering employees to make data-driven decisions based on evidence and analytics.
But often that’s how we present statistics: we just show the notes, we don’t play the music.” – Hans Rosling, Swedish statistician. 14) “Visualize This: The Flowing Data Guide to Design, Visualization, and Statistics” by Nathan Yau. “Most of us need to listen to the music to understand how beautiful it is.
These data models predict outcomes of new data. Data science is one of the highest-paid jobs of the 21st century. Data science needs knowledge from a variety of fields including statistics, mathematics, programming, and transforming data. Here are the chronological steps for the data science journey.
On the flip side, if you enjoy diving deep into the technical side of things, with the right mix of skills for business intelligence you can work a host of incredibly interesting problems that will keep you in flow for hours on end. The Bureau of Labor Statistics also states that in 2015, the annual median salary for BI analysts was $81,320.
You can use the flexible connector framework and search flow pipelines in OpenSearch to connect to models hosted by DeepSeek, Cohere, and OpenAI, as well as models hosted on Amazon Bedrock and SageMaker. The connector is an OpenSearch construct that tells OpenSearch how to connect to an external model host.
In fact, according to eMarketer, 40% of executives surveyed in a study focused on data-driven marketing, expect to “significantly increase” revenue. Not to worry – we’ll not only explain the link between bigdata and business performance but also explore real-life performance dashboard examples and explain why you need one (or several).
They give online retailers high levels of control over their own internal data. They are not subject to data loss from hosting it in the cloud, which might have retention policies outside their control. E-commerce companies are using a lot of great data centers and hosting options.
This weeks guest post comes from KDD (Knowledge Discovery and Data Mining). Every year they host an excellent and influential conference focusing on many areas of data science. Honestly, KDD has been promoting data science way before data science was even cool. 1989 to be exact. The details are below.
An education in data science can help you land a job as a data analyst , data engineer , data architect , or data scientist. The course includes instruction in statistics, machine learning, natural language processing, deep learning, Python, and R. On-site courses are available in Munich. Cost: $1,099.
You need to use the user name and password for cloning the OSCAR data: GIT_LFS_SKIP_SMUDGE=1 git clone [link] cd OSCAR-2301 git lfs pull --include en_meta cd en_meta for F in `ls *.zst`; After you review the cluster configuration, select the jump host as the target for the run command. zst`; do zstd -d $F; done rm *.zst
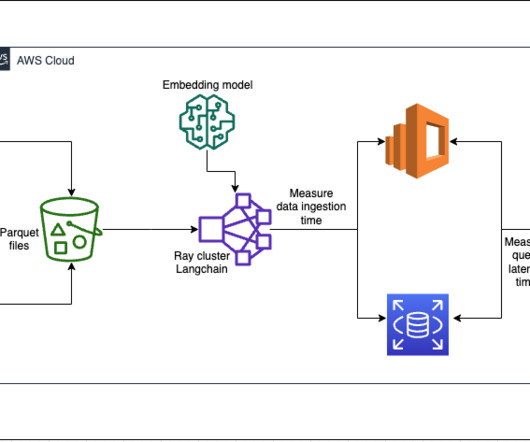
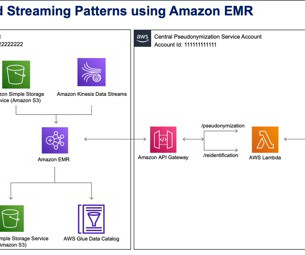
The account on the right hosts the pseudonymization service, which you can deploy using the instructions provided in the Part 1 of this series. Amazon EMR empowers you to create, operate, and scale bigdata frameworks such as Apache Spark quickly and cost-effectively. Run ID Dataset Size Total Invocations A 9.53 MB per minute.
Today, data visualization encompasses all manners of presenting data visually, from dashboards to reports, statistical graphs, heat maps, plots, infographics, and more. What is the business value of data visualization? Data visualization helps people analyze data, especially large volumes of data, quickly and efficiently.
Dashboards are hosted software applications that automatically pull together available data into charts and graphs that give a sense of the immediate state of the company. BI analysts use data analytics, data visualization, and data modeling techniques and technologies to identify trends.
With quality data at their disposal, organizations can form data warehouses for the purposes of examining trends and establishing future-facing strategies. Industry-wide, the positive ROI on quality data is well understood. 2 – Data profiling. Data profiling is an essential process in the DQM lifecycle.
Currently, popular approaches include statistical methods, computational intelligence, and traditional symbolic AI. Some more examples of AI applications can be found in various domains: in 2020 we will experience more AI in combination with bigdata in healthcare. One of the IT buzzwords you must take note of in 2020.
Let’s consider the differences between the two, and why they’re both important to the success of data-driven organizations. Digging into quantitative data. This is quantitative data. It’s “hard,” structured data that answers questions such as “how many?” First, data isn’t created in a uniform, consistent format.
The challenge is to do it right, and a crucial way to achieve it is with decisions based on data and analysis that drive measurable business results. This was the key learning from the Sisense event heralding the launch of Periscope Data in Tel Aviv, Israel — the beating heart of the startup nation. What VCs want from startups.
Exclusive Bonus Content: Ready to use data analytics in your restaurant? Get our free bite-sized summary for increasing your profits through data! A sobering statistic if ever we saw one. Data offers the power to gain an objective, accurate, and comprehensive view of your restaurant’s daily functions.
If you play fantasy football, you are no stranger to data-driven decision-making. Every week during football season, an estimated 60 million Americans pore over player statistics, point projections and trade proposals, looking for those elusive insights to guide their roster decisions and lead them to victory.
According to statistics, an astonishing 62% of managers are reluctant to talk to their employees about anything, while one in five business leaders feel uncomfortable when it comes to recognizing employees’ achievements. And you’ll be doing this every year without any clear purpose or benefit for your employees or clients.
But in this digital age, dynamic modern IT reports created with a state-of-the-art online reporting tool are here to help you provide viable answers to a host of burning departmental questions. The purpose is not to track every statistic possible, as you risk being drowned in data and losing focus.
IBM Storage FlashSystem also offers inline data corruption detection through its new Flash Core Modules 4 (FCM4), which continuously monitors statistics gathered from every single I/O using machine learning models to early detect anomalies at block level.
Learn more: How Moderna uses lipid nanoparticles (LNPs) to deliver mRNA and help fight disease Given the value of their platform approach, perhaps quantum might further push their ability to perform mRNA research, providing a host of novel mRNA vaccines more efficiently than ever before. This is where IBM can help.
While data science and machine learning are related, they are very different fields. In a nutshell, data science brings structure to bigdata while machine learning focuses on learning from the data itself. What is data science? It’s also necessary to understand data cleaning and processing techniques.
For example, imagine a fantasy football site is considering displaying advanced player statistics. A ramp-up strategy may mitigate the risk of upsetting the site’s loyal users who perhaps have strong preferences for the current statistics that are shown. One reason to do ramp-up is to mitigate the risk of never before seen arms.
They recently needed to do a monthly load of 140 TB of uncompressed healthcare claims data in under 24 hours after receiving it to provide analysts and data scientists with up-to-date information on a patient’s healthcare journey. This data volume is expected to increase monthly and is fully refreshed each month.
Modern analytics is much wider than SQL-based data warehousing. With Amazon Redshift, you can build lake house architectures and perform any kind of analytics, such as interactive analytics , operational analytics , bigdata processing , visual data preparation , predictive analytics, machine learning , and more.
This includes such things as datahosting locations, logging methods and logging tools. Organize the Log Data. While log data is valuable , it is very hard to extract that value if there isn’t some kind of structure to the data. You won’t be able to analyze it or get any meaningful statistics or reports out of it.
High variance in a model may indicate the model works with training data but be inadequate for real-world industry use cases. Limited data scope and non-representative answers: When data sources are restrictive, homogeneous or contain mistaken duplicates, statistical errors like sampling bias can skew all results.
This is the most basic validation step to make sure no data has been lost or duplicated during the migration process. Column-level validation – Validate individual columns by comparing column-level statistics (min, max, count, sum, average) for each column between the source and target databases.
Instead, consider a “full stack” tracing from the point of data collection all the way out through inference. At CMU I joined a panel hosted by Zachary Lipton where someone in the audience asked a question about machine learning model interpretation. Having more data is generally better; however, there are subtle nuances.
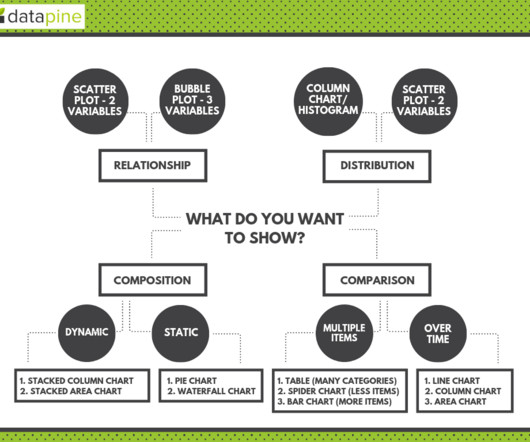
2) Charts And Graphs Categories 3) 20 Different Types Of Graphs And Charts 4) How To Choose The Right Chart Type Data and statistics are all around us. That is because graphical representations of data make it easier to convey important information to different audiences. Table of Contents 1) What Are Graphs And Charts?
Using IBM Cloud to transform global payments rails The need for continuously available payment processing requires a rethinking of end-of-day cycles and introduces the need for stand-in processing for the times when host applications are down for end-of-day cycles or unavailable due to system outages or maintenance.
One of the key challenges in distributed scale-out databases included how to deploy many hosts built with high availability and elasticity while keeping the familiar SQL interface. Co-developing with customers in gaming, banking and ridesharing. Databases offer a diversity of technical areas that are in constant flux.
But business leaders are facing a host of talent-related challenges, as a new global study from the IBM Institute for Business Value (IBV) reveals , from the skills gap to shifting employee expectations to the need for new operating models. billion people in the global workforce, according to World Bank statistics. billion of the 3.4
In Data-Powered Businesses , we dive into the ways that companies of all kinds are digitally transforming to make smarter data-driven decisions, monetize their data, and create companies that will thrive in our current era of BigData. This piece was originally published on Search Business Analytics. ”
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content