This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Piperr.io — Pre-built data pipelines across enterprise stakeholders, from IT to analytics, tech, data science and LoBs. Prefect Technologies — Open-source data engineering platform that builds, tests, and runs data workflows. Genie — Distributed bigdata orchestration service by Netflix.
The bigdata market is expected to be worth $189 billion by the end of this year. A number of factors are driving growth in bigdata. Demand for bigdata is part of the reason for the growth, but the fact that bigdata technology is evolving is another. Unstructured. Structured.
Although Amazon DataZone automates subscription fulfillment for structured data assetssuch as data stored in Amazon Simple Storage Service (Amazon S3), cataloged with the AWS Glue Data Catalog , or stored in Amazon Redshift many organizations also rely heavily on unstructureddata. Enter a name for the asset.
Cloud technology results in lower costs, quicker service delivery, and faster network data streaming. It also allows companies to offload large amounts of data from their networks by hosting it on remote servers anywhere on the globe. Bigdata analytics. Multi-cloud computing.
Without the existence of dashboards and dashboard reporting practices, businesses would need to sift through colossal stacks of unstructureddata, which is both inefficient and time-consuming. This particular data dashboard example shows how bigdata and data analytics can impact the logistics industry.
We use leading-edge analytics, data, and science to help clients make intelligent decisions. We developed and host several applications for our customers on Amazon Web Services (AWS). Neptune ingests both structured and unstructureddata, simplifying the process to retrieve content across different sources and formats.
Not only does it support the successful planning and delivery of each edition of the Games, but it also helps each successive OCOG to develop its own vision, to understand how a host city and its citizens can benefit from the long-lasting impact and legacy of the Games, and to manage the opportunities and risks created.
This feature hierarchy and the filters that model significance in the data, make it possible for the layers to learn from experience. Thus, deep nets can crunch unstructureddata that was previously not available for unsupervised analysis. One of the IT buzzwords you must take note of in 2020.
Furthermore, TDC Digital had not used any cloud storage solution and experienced latency and downtime while hosting the application in its data center. TDC Digital is excited about its plans to host its IT infrastructure in IBM data centers, offering better scalability, performance and security.
This has led to the emergence of the field of BigData, which refers to the collection, processing, and analysis of vast amounts of data. With the right BigData Tools and techniques, organizations can leverage BigData to gain valuable insights that can inform business decisions and drive growth.
Over the past 5 years, bigdata and BI became more than just data science buzzwords. Without real-time insight into their data, businesses remain reactive, miss strategic growth opportunities, lose their competitive edge, fail to take advantage of cost savings options, don’t ensure customer satisfaction… the list goes on.
Bigdata exploded onto the scene in the mid-2000s and has continued to grow ever since. Today, the data is even bigger, and managing these massive volumes of data presents a new challenge for many organizations. Even if you live and breathe tech every day, it’s difficult to conceptualize how big “big” really is.
Open source frameworks such as Apache Impala, Apache Hive and Apache Spark offer a highly scalable programming model that is capable of processing massive volumes of structured and unstructureddata by means of parallel execution on a large number of commodity computing nodes. . public, private, hybrid cloud)?
With the rise of highly personalized online shopping, direct-to-consumer models, and delivery services, generative AI can help retailers further unlock a host of benefits that can improve customer care, talent transformation and the performance of their applications.
Since the deluge of bigdata over a decade ago, many organizations have learned to build applications to process and analyze petabytes of data. Data lakes have served as a central repository to store structured and unstructureddata at any scale and in various formats.
Despite its many uses, quantitative data presents two main challenges for a data-driven organization. First, data isn’t created in a uniform, consistent format. It’s generated by a host of sources in different ways. Better together: Working with qualitative data and quantitative data.
And next to those legacy ERP, HCM, SCM and CRM systems, that mysterious elephant in the room – that “BigData” platform running in the data center that is driving much of the company’s analytics and BI – looks like a great potential candidate. . BigData is an ecosystem as well as a philosophy.
The Orca Platform is powered by a state-of-the-art anomaly detection system that uses cutting-edge ML algorithms and bigdata capabilities to detect potential security threats and alert customers in real time, ensuring maximum security for their cloud environment. Why did Orca choose Apache Iceberg?
These applications are all hosted on the IBM Cloud to ensure uninterrupted availability. Managers can also use the AI models to analyze structured and unstructureddata to compare players, estimate the potential upside and downside of starting a particular player and assess the impact of an injury.
In addition, IBM will host StarCoder, a large language model for code, including over 80+ programming languages, Git commits, GitHub issues and Jupyter notebooks. In addition to the new models, IBM is also launching new complementary capabilities in the watsonx.ai
It includes massive amounts of unstructureddata in multiple languages, starting from 2008 and reaching the petabyte level. In the training of GPT-3, the Common Crawl dataset accounts for 60% of its training data, as shown in the following diagram (source: Language Models are Few-Shot Learners ). It is continuously updated.
Organizations are collecting and storing vast amounts of structured and unstructureddata like reports, whitepapers, and research documents. By consolidating this information, analysts can discover and integrate data from across the organization, creating valuable data products based on a unified dataset.
With the rapid growth of technology, more and more data volume is coming in many different formats—structured, semi-structured, and unstructured. Data analytics on operational data at near-real time is becoming a common need.
Oalva brought years of bigdata, data warehouse and Hadoop expertise to the table. Today SMG can leverage tremendously more Data Science on both structured and unstructureddata. They advised SMG on best practices based on their experience with many Hadoop implementations across a variety of disciplines. .
A data lake is a centralized repository that you can use to store all your structured and unstructureddata at any scale. You can store your data as-is, without having to first structure the data and then run different types of analytics for better business insights. Open AWS Glue Studio. Choose ETL Jobs.
While data science and machine learning are related, they are very different fields. In a nutshell, data science brings structure to bigdata while machine learning focuses on learning from the data itself. What is data science? This post will dive deeper into the nuances of each field.
You can take all your data from various silos, aggregate that data in your data lake, and perform analytics and machine learning (ML) directly on top of that data. You can also store other data in purpose-built data stores to analyze and get fast insights from both structured and unstructureddata.
2007: Amazon launches SimpleDB, a non-relational (NoSQL) database that allows businesses to cheaply process vast amounts of data with minimal effort. The platform is built on S3 and EC2 using a hosted Hadoop framework. An efficient bigdata management and storage solution that AWS quickly took advantage of.
Cloud warehouses also provide a host of additional capabilities such as failover to different data centers, automated backup and restore, high availability, and advanced security and alerting measures. Additionally, some DBAs worry that moving to the cloud reduces the need for their expertise and skillset.
These embeddings are stored and managed efficiently using specialized vector stores such as Amazon OpenSearch Service , which is designed to store and retrieve large volumes of high-dimensional vectors alongside structured and unstructureddata.
This varies based on workload characteristics; for instance, in the media or streaming industry, data transmission over the network and storing large unstructureddata sets consume considerable energy.
Many organizations are building data lakes to store and analyze large volumes of structured, semi-structured, and unstructureddata. In addition, many teams are moving towards a data mesh architecture, which requires them to expose their data sets as easily consumable data products.
A general LLM won’t be calibrated for that, but you can recalibrate it—a process known as fine-tuning—to your own data. Fine-tuning applies to both hosted cloud LLMs and open source LLM models you run yourself, so this level of ‘shaping’ doesn’t commit you to one approach. And be realistic about what they can deliver, Paoli warns.
As part of our generative AI initiatives, we can demonstrate the ability to use a foundation model with prompt tuning to review the structured and unstructureddata within the insurance documents (data associated with the customer query) and provide tailored recommendations concerning the product, contract or general insurance inquiry.
Amazon EMR has long been the leading solution for processing bigdata in the cloud. Amazon EMR is the industry-leading bigdata solution for petabyte-scale data processing, interactive analytics, and machine learning using over 20 open source frameworks such as Apache Hadoop , Hive, and Apache Spark.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





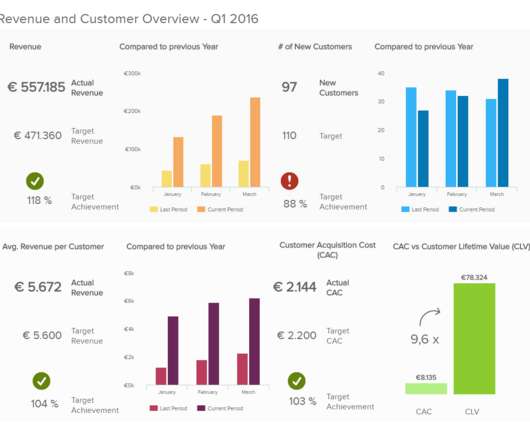





































Let's personalize your content