This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Table of Contents 1) Benefits Of BigData In Logistics 2) 10 BigData In Logistics Use Cases Bigdata is revolutionizing many fields of business, and logistics analytics is no exception. The complex and ever-evolving nature of logistics makes it an essential use case for bigdata applications.
The need for streamlined datatransformations As organizations increasingly adopt cloud-based data lakes and warehouses, the demand for efficient datatransformation tools has grown. This approach helps in managing storage costs while maintaining the flexibility to analyze historical trends when needed.
There are countless examples of bigdatatransforming many different industries. There is no disputing the fact that the collection and analysis of massive amounts of unstructured data has been a huge breakthrough. We would like to talk about data visualization and its role in the bigdata movement.
For container terminal operators, data-driven decision-making and efficient data sharing are vital to optimizing operations and boosting supply chain efficiency. With a unified catalog, enhanced analytics capabilities, and efficient datatransformation processes, were laying the groundwork for future growth.
With Amazon AppFlow, you can run data flows at nearly any scale and at the frequency you chooseon a schedule, in response to a business event, or on demand. You can configure datatransformation capabilities such as filtering and validation to generate rich, ready-to-use data as part of the flow itself, without additional steps.
Together with price-performance, Amazon Redshift offers capabilities such as serverless architecture, machine learning integration within your data warehouse and secure data sharing across the organization. dbt Cloud is a hosted service that helps data teams productionize dbt deployments.
Let’s go through the ten Azure data pipeline tools Azure Data Factory : This cloud-based data integration service allows you to create data-driven workflows for orchestrating and automating data movement and transformation. You can use it for bigdata analytics and machine learning workloads.
Attempting to learn more about the role of bigdata (here taken to datasets of high volume, velocity, and variety) within business intelligence today, can sometimes create more confusion than it alleviates, as vital terms are used interchangeably instead of distinctly. Bigdata challenges and solutions.
This new JDBC connectivity feature enables our governed data to flow seamlessly into these tools, supporting productivity across our teams.” Use case Amazon DataZone addresses your data sharing challenges and optimizesdata availability.
Amazon Athena provides interactive analytics service for analyzing the data in Amazon Simple Storage Service (Amazon S3). Amazon Redshift is used to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes. You can add more such query optimization rules to the instructions.
With quality data at their disposal, organizations can form data warehouses for the purposes of examining trends and establishing future-facing strategies. Industry-wide, the positive ROI on quality data is well understood. This means there are no unintended data errors, and it corresponds to its appropriate designation (e.g.,
Whether you’re looking to earn a certification from an accredited university, gain experience as a new grad, hone vendor-specific skills, or demonstrate your knowledge of data analytics, the following certifications (presented in alphabetical order) will work for you. Check out our list of top bigdata and data analytics certifications.)
Maintaining reusable database sessions to help optimize the use of database connections, preventing the API server from exhausting the available connections and improving overall system scalability.
Data lakes provide a centralized repository for data from various sources, enabling organizations to unlock valuable insights and drive data-driven decision-making. However, as data volumes continue to grow, optimizingdata layout and organization becomes crucial for efficient querying and analysis.
Oracle GoldenGate for Oracle Database and BigData adapters Oracle GoldenGate is a real-time data integration and replication tool used for disaster recovery, data migrations, high availability. Configure GoldenGate for Oracle Database and extract data from the Oracle database to trail files.
Amazon EMR on EKS provides a deployment option for Amazon EMR that allows organizations to run open-source bigdata frameworks on Amazon Elastic Kubernetes Service (Amazon EKS). This performance-optimized runtime offered by Amazon EMR makes your Spark jobs run fast and cost-effectively. As of the Amazon EMR 6.5 Amazon EMR 6.10
For workloads such as datatransforms, joins, and queries, you can use G.1X With exponentially growing data sources and data lakes, customers want to run more data integration workloads, including their most demanding transforms, aggregations, joins, and queries. 1X (1 DPU) and G.2X DPU-hour ($) G.2X
BMW Group uses 4,500 AWS Cloud accounts across the entire organization but is faced with the challenge of reducing unnecessary costs, optimizing spend, and having a central place to monitor costs. The ultimate goal is to raise awareness of cloud efficiency and optimize cloud utilization in a cost-effective and sustainable manner.
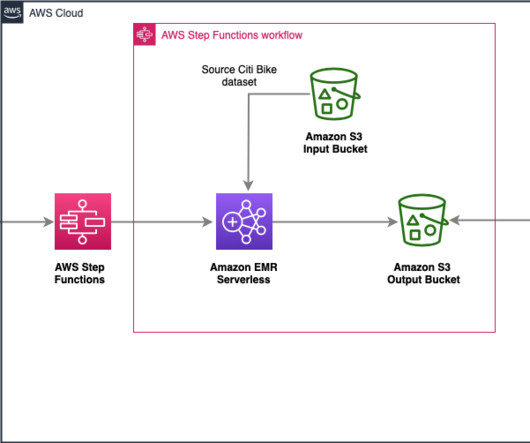
With EMR Serverless, you don’t have to configure, optimize, secure, or operate clusters to run applications with these frameworks. You can run analytics workloads at any scale with automatic scaling that resizes resources in seconds to meet changing data volumes and processing requirements. Now, with the support for “Run a Job (.sync)”
The Orca Platform is powered by a state-of-the-art anomaly detection system that uses cutting-edge ML algorithms and bigdata capabilities to detect potential security threats and alert customers in real time, ensuring maximum security for their cloud environment. This ensures that the data is suitable for training purposes.
However, you might face significant challenges when planning for a large-scale data warehouse migration. This includes the ETL processes that capture source data, the functional refinement and creation of data products, the aggregation for business metrics, and the consumption from analytics, business intelligence (BI), and ML.
In this post, we explore how AWS Glue can serve as the data integration service to bring the data from Snowflake for your data integration strategy, enabling you to harness the power of your data ecosystem and drive meaningful outcomes across various use cases. Store the extracted and transformeddata in Amazon S3.
With our strategy in mind, we factored in our consumers and consuming services, which primarily are Sisense Fusion Analytics and Cloud Data Teams. Interestingly, this ad hoc analysis benefits from a single source of truth that is easy to query to allow for quickly querying of raw data alongside the cleanest data (i.e.,
If you can’t make sense of your business data, you’re effectively flying blind. Insights hidden in your data are essential for optimizing business operations, finetuning your customer experience, and developing new products — or new lines of business, like predictive maintenance. Azure Data Factory. Azure Data Explorer.
Additionally, a TCO calculator generates the TCO estimation of an optimized EMR cluster for facilitating the migration. For optimizing EMR cluster cost effectiveness, the following table provides general guidelines of choosing the proper type of EMR cluster and Amazon Elastic Compute Cloud (Amazon EC2) family.
The data lakehouse architecture combines the flexibility, scalability and cost advantages of data lakes with the performance, functionality and usability of data warehouses to deliver optimal price-performance for a variety of data, analytics and AI workloads.
Notably, a partner with global reach can be particularly valuable to an organisation with operations with a global presence; since the structure of most multinational organisations is optimised to support their core business rather than initiatives like digital transformation.
We choose AWS Glue mainly due to its serverless nature, which simplifies infrastructure management with automatic provisioning and worker management, and the ability to perform complex datatransformations at scale. With data democratization, many users lacked the knowledge to right-size their AWS Glue jobs.
Within the ANZ enterprise data mesh strategy, aligning data mesh nodes with the ANZ Group’s divisional structure provides optimal alignment between data mesh principles and organizational structure, as shown in the following diagram.
To create and manage the data products, smava uses Amazon Redshift , a cloud data warehouse. In this post, we show how smava optimized their data platform by using Amazon Redshift Serverless and Amazon Redshift data sharing to overcome right-sizing challenges for unpredictable workloads and further improve price-performance.
In this post, we provide a detailed overview of streaming messages with Amazon Managed Streaming for Apache Kafka (Amazon MSK) and Amazon ElastiCache for Redis , covering technical aspects and design considerations that are essential for achieving optimal results. We also discuss the key features, considerations, and design of the solution.
With auto-copy, automation enhances the COPY command by adding jobs for automatic ingestion of data. If storing operational data in a data warehouse is a requirement, synchronization of tables between operational data stores and Amazon Redshift tables is supported.
Natively support BigData workloads. YuniKorn is designed for BigData app workloads, and it natively supports to run Spark/Flink/Tensorflow, etc efficiently in K8s. YuniKorn is optimized for performance, it is suitable for high throughput and large scale environments. Scale & Performance. Acknowledgments.
We will create a glue studio job, add events and venue data from the SFTP server, carry out datatransformations and load transformeddata to s3. BigData and ETL Solutions Architect, MWAA and AWS Glue ETL expert. Select Visual ETL in the central pane. Kamen Sharlandjiev is a Sr.
After all, we invented the whole idea of BigData. So what’s our next big idea? Well, at Cloudera, we envision a world where everyone can quickly and easily access the data-powered information and insights they need – in just a few clicks. . Open source matters. And only Cloudera delivers on every dimension.
If you want deeper control over your infrastructure for cost and latency optimization, you can choose OpenSearch Service’s managed clusters deployment option. With managed clusters, you get granular control over the instances you would like to use, indexing and data-sharding strategy, and more.
dbt is an open source, SQL-first templating engine that allows you to write repeatable and extensible datatransforms in Python and SQL. dbt is predominantly used by data warehouses (such as Amazon Redshift ) customers who are looking to keep their datatransform logic separate from storage and engine.
Accurately predicting demand for products allows businesses to optimize inventory levels, minimize stockouts, and reduce holding costs. Solution overview In today’s highly competitive business landscape, it’s essential for retailers to optimize their inventory management processes to maximize profitability and improve customer satisfaction.
After the read query validation stage was complete and we were satisfied with the performance, we reconnected our orchestrator so that the datatransformation queries could be run in the new cluster. At this point, only one-time queries and those made by Amazon QuickSight reached the new cluster.
The main driving factors include lower total cost of ownership, scalability, stability, improved ingestion connectors (such as Data Prepper , Fluent Bit, and OpenSearch Ingestion), elimination of external cluster managers like Zookeeper, enhanced reporting, and rich visualizations with OpenSearch Dashboards.
There are three technological advances driving this data consumption and, in turn, the ability for employees to leverage this data to deliver business value 1) exploding data production 2) scalable bigdata computation, and 3) the accessibility of advanced analytics, machine learning (ML) and artificial intelligence (AI).
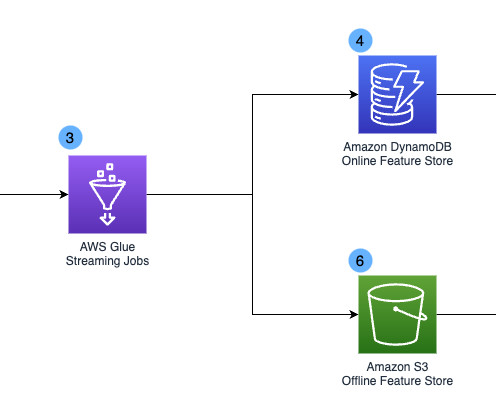
Pattern 1: Datatransformation, load, and unload Several of our data pipelines included significant datatransformation steps, which were primarily performed through SQL statements executed by Amazon Redshift. The following Diagram 2 shows this workflow.
The key idea behind incremental queries is to use metadata or change tracking mechanisms to identify the new or modified data since the last query. By identifying these changes, the query engine can optimize the query to process only the relevant data, significantly reducing the processing time and resource requirements.
In addition, more data is becoming available for processing / enrichment of existing and new use cases e.g., recently we have experienced a rapid growth in data collection at the edge and an increase in availability of frameworks for processing that data. As a result, alternative data integration technologies (e.g.,
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content