This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Table of Contents 1) Benefits Of BigData In Logistics 2) 10 BigData In Logistics Use Cases Bigdata is revolutionizing many fields of business, and logistics analytics is no exception. The complex and ever-evolving nature of logistics makes it an essential use case for bigdata applications.
The healthcare industry is happily embracing bigdata. Hospitals around the world are finding that data can have a profound impact on their operations. BigData is the Key to Improving the Efficiency of Hospital Management Systems? A 2015 article by Evariant showed some of the positive implications of bigdata.
response = client.create( key="test", value="Test value", description="Test description" ) print(response) print("nListing all variables.") variables = client.list() print(variables) print("nGetting the test variable.") Creating a test variable. Creating a test variable. Creating a test variable.
With this launch of JDBC connectivity, Amazon DataZone expands its support for data users, including analysts and scientists, allowing them to work in their preferred environments—whether it’s SQL Workbench, Domino, or Amazon-native solutions—while ensuring secure, governed access within Amazon DataZone. Choose Test connection.
Together with price-performance, Amazon Redshift offers capabilities such as serverless architecture, machine learning integration within your data warehouse and secure data sharing across the organization. dbt Cloud is a hosted service that helps data teams productionize dbt deployments. Choose Test Connection.
The need for streamlined datatransformations As organizations increasingly adopt cloud-based data lakes and warehouses, the demand for efficient datatransformation tools has grown. This approach helps in managing storage costs while maintaining the flexibility to analyze historical trends when needed.
Your generated jobs can use a variety of datatransformations, including filters, projections, unions, joins, and aggregations, giving you the flexibility to handle complex data processing requirements. In this post, we discuss how Amazon Q data integration transforms ETL workflow development.
For each service, you need to learn the supported authorization and authentication methods, data access APIs, and framework to onboard and testdata sources. This approach simplifies your data journey and helps you meet your security requirements. Noritaka Sekiyama is a Principal BigData Architect on the AWS Glue team.
With quality data at their disposal, organizations can form data warehouses for the purposes of examining trends and establishing future-facing strategies. Industry-wide, the positive ROI on quality data is well understood. This means there are no unintended data errors, and it corresponds to its appropriate designation (e.g.,
Let’s go through the ten Azure data pipeline tools Azure Data Factory : This cloud-based data integration service allows you to create data-driven workflows for orchestrating and automating data movement and transformation. You can use it for bigdata analytics and machine learning workloads.
Amazon DataZone recently announced the expansion of data analysis and visualization options for your project-subscribed data within Amazon DataZone using the Amazon Athena JDBC driver. Joel has led datatransformation projects on fraud analytics, claims automation, and Master Data Management.
Whether you’re looking to earn a certification from an accredited university, gain experience as a new grad, hone vendor-specific skills, or demonstrate your knowledge of data analytics, the following certifications (presented in alphabetical order) will work for you. Check out our list of top bigdata and data analytics certifications.)
Data analytics draws from a range of disciplines — including computer programming, mathematics, and statistics — to perform analysis on data in an effort to describe, predict, and improve performance. What are the four types of data analytics? Data analytics and data science are closely related.
Amazon EMR on EKS provides a deployment option for Amazon EMR that allows organizations to run open-source bigdata frameworks on Amazon Elastic Kubernetes Service (Amazon EKS). The solution uses the TPC-DS dataset and unmodified data schema and table relationships, but derives queries from TPC-DS to support the SparkSQL test cases.
Amazon Athena provides interactive analytics service for analyzing the data in Amazon Simple Storage Service (Amazon S3). Amazon Redshift is used to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes.
SELECT * FROM svv_attached_masking_policy; Now you can test that different users can see the same data masked differently based on their roles. The OBJECT_TRANSFORM function in Amazon Redshift is designed to facilitate datatransformations by allowing you to manipulate JSON data directly within the database.
The advent of rapid adoption of serverless data lake architectures—with ever-growing datasets that need to be ingested from a variety of sources, followed by complex datatransformation and machine learning (ML) pipelines—can present a challenge. Disable the rules after testing to avoid repeated messages.
To run HiveQL-based data workloads with Spark on Kubernetes mode, engineers must embed their SQL queries into programmatic code such as PySpark, which requires additional effort to manually change code. Navigate to the side menu Virtual clusters , then select the HiveDemo cluster , You can see an entry for the SparkSQL test job.
A modern data platform entails maintaining data across multiple layers, targeting diverse platform capabilities like high performance, ease of development, cost-effectiveness, and DataOps features such as CI/CD, lineage, and unit testing. It does this by helping teams handle the T in ETL (extract, transform, and load) processes.
However, you might face significant challenges when planning for a large-scale data warehouse migration. This will enable right-sizing the Redshift data warehouse to meet workload demands cost-effectively. Additional considerations – Factor in additional tasks beyond schema conversion.
dbt is an open source, SQL-first templating engine that allows you to write repeatable and extensible datatransforms in Python and SQL. dbt is predominantly used by data warehouses (such as Amazon Redshift ) customers who are looking to keep their datatransform logic separate from storage and engine.
For example, the following creates a collection called test with one shard and no replicas. For the updateRequestProcessorChain , OpenSearch provides the ingest pipeline , allowing the enrichment or transformation of data before indexing. Multiple processor stages can be chained to form a pipeline for datatransformation.
Each CDH dataset has three processing layers: source (raw data), prepared (transformeddata in Parquet), and semantic (combined datasets). It is possible to define stages (DEV, INT, PROD) in each layer to allow structured release and test without affecting PROD.
In addition to using native managed AWS services that BMS didn’t need to worry about upgrading, BMS was looking to offer an ETL service to non-technical business users that could visually compose datatransformation workflows and seamlessly run them on the AWS Glue Apache Spark-based serverless data integration engine.
To grow the power of data at scale for the long term, it’s highly recommended to design an end-to-end development lifecycle for your data integration pipelines. The following are common asks from our customers: Is it possible to develop and test AWS Glue data integration jobs on my local laptop?
The techniques for managing organisational data in a standardised approach that minimises inefficiency. Extraction, Transform, Load (ETL). The extraction of raw data, transforming to a suitable format for business needs, and loading into a data warehouse. Datatransformation. Microsoft Azure.
Natively support BigData workloads. YuniKorn is designed for BigData app workloads, and it natively supports to run Spark/Flink/Tensorflow, etc efficiently in K8s. The Test and Development queue have fixed resource limits. Resource fairness. Default scheduler focuses for long-running services. Acknowledgments.
Our approach The migration initiative consisted of two main parts: building the new architecture and migrating data pipelines from the existing tool to the new architecture. Often, we would work on both in parallel, testing one component of the architecture while developing another at the same time.
AWS offers Redshift Test Drive to validate whether the configuration chosen for Amazon Redshift is ideal for your workload before migrating the production environment. At this point, only one-time queries and those made by Amazon QuickSight reached the new cluster. We removed the DC2 cluster and completed the migration.
Datatransforms businesses. That’s where the data lifecycle comes into play. Managing data and its flow, from the edge to the cloud, is one of the most important tasks in the process of gaining data intelligence. .
It has not been specifically designed for heavy datatransformation tasks. To load the time series for a specific point into a pandas data frame, you can use the awswrangler library from your Python code: import awswrangler as wr import pandas as pd # Retrieving the data directly from Amazon S3 df = wr.s3.read_parquet("s3://
The data products from the Business Vault and Data Mart stages are now available for consumers. smava decided to use Tableau for business intelligence, data visualization, and further analytics. The datatransformations are managed with dbt to simplify the workflow governance and team collaboration.
Duplicating data from a production database to a lower or lateral environment and masking personally identifiable information (PII) to comply with regulations enables development, testing, and reporting without impacting critical systems or exposing sensitive customer data. PII detection and scrubbing.
Clean up After you complete all the steps and finish testing, complete the following steps to delete resources to avoid incurring costs: On the AWS CloudFormation console, choose the stack you created. He has a specialty in bigdata services and technologies and an interest in building customer business outcomes together.
Tricentis is the global leader in continuous testing for DevOps, cloud, and enterprise applications. Speed changes everything, and continuous testing across the entire CI/CD lifecycle is the key. Tricentis instills that confidence by providing software tools that enable Agile Continuous Testing (ACT) at scale.
As we review datatransformation and modernization strategies with our clients, we find many are investigating Snowflake as a data warehouse solution due to its ease of use, speed, and increased flexibility over a traditional data warehouse offering. Validate and test through the entire migration. Sirius can help.
DataBrew is a visual data preparation tool that enables you to clean and normalize data without writing any code. The over 200 transformations it provides are now available to be used in an AWS Glue Studio visual job. BigData Architect on the AWS Glue team. Gonzalo Herreros is a Sr.
Kinesis Data Firehose is a fully managed service for delivering near-real-time streaming data to various destinations for storage and performing near-real-time analytics. You can perform analytics on VPC flow logs delivered from your VPC using the Kinesis Data Firehose integration with Datadog as a destination.
Creating an external schema from the data share database on the consumer, mirroring that of the producer cluster with identical names. Testing: Conducting an internal week-long regression testing and auditing process to meticulously validate all data points by running the same workload and twice the workload.
Jessicamouth 2964 Queensland Load the dataset First, create a new table in your Redshift Serverless endpoint and copy the testdata into it by doing the following: Open the Query Editor V2 and log in using the admin user name and details defined when the endpoint was created.
In perhaps a preview of things to come next year, we decided to test how a Data Catalog might work with Tableau on the same data. You can check out a self service data prep flow from catalog to viz in this recorded version here. Rita Sallam Introduces the Data Prep Rodeo. To Coming Home, Home on the Range.
AWS Glue Studio is a graphical interface that makes it easy to create, run, and monitor extract, transform, and load (ETL) jobs in AWS Glue. It allows you to visually compose datatransformation workflows using nodes that represent different data handling steps, which later are converted automatically into code to run.
Extract, load, Transform (ELT) tools. Data ingestion/integration services. Data orchestration tools. These tools are used to manage bigdata, which is defined as data that is too large or complex to be processed by traditional means. How Did the Modern Data Stack Get Started? Reverse ETL tools.
Alternatively, you can use AWS Glue for Apache Spark, which provides built-in support for bucketing configurations during the datatransformation process. AWS Glue allows you to define bucketing parameters, such as the number of buckets and the columns to bucket on, providing an optimized data layout for efficient querying with Athena.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































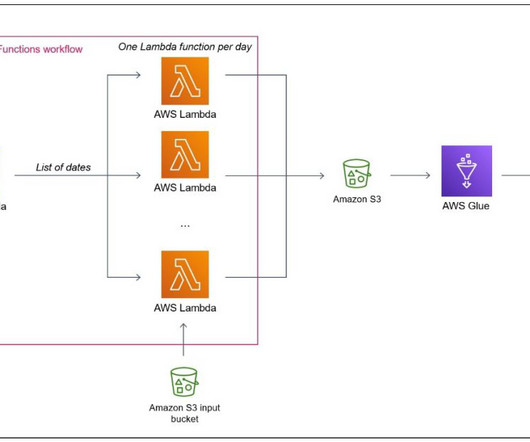




















Let's personalize your content