This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Table of Contents 1) Benefits Of BigData In Logistics 2) 10 BigData In Logistics Use Cases Bigdata is revolutionizing many fields of business, and logistics analytics is no exception. The complex and ever-evolving nature of logistics makes it an essential use case for bigdata applications.
Ali Tore, Senior Vice President of Advanced Analytics at Salesforce, highlighting the value of this integration, says “We’re excited to partner with Amazon to bring Tableau’s powerful data exploration and AI-driven analytics capabilities to customers managing data across organizational boundaries with Amazon DataZone.
There are countless examples of bigdatatransforming many different industries. It can be used for something as visual as reducing traffic jams, to personalizing products and services, to improving the experience in multiplayer video games. Data is useless without the opportunity to visualize what we are looking for.
This means you can refine your ETL jobs through natural follow-up questionsstarting with a basic data pipeline and progressively adding transformations, filters, and business logic through conversation. The DataFrame code generation now extends beyond AWS Glue DynamicFrame to support a broader range of data processing scenarios.
With the ability to browse metadata, you can understand the structure and schema of the data source, identify relevant tables and fields, and discover useful data assets you may not be aware of. You can navigate to the projects Data page to visually verify the existence of the newly created table. option("url", jdbcurl).option("dbtable",
Amazon DataZone is a data management service that makes it faster and easier for customers to catalog, discover, share, and govern data stored across AWS, on premises, and from third-party sources. When you’re connected, you can query, visualize, and share data—governed by Amazon DataZone—within Tableau.
Content includes reports, documents, articles, presentations, visualizations, video, and audio representations of the insights and knowledge that have been extracted from data. We could further refine our opening statement to say that our business users are too often in a state of being data-rich, but insights-poor, and content-hungry.
We are excited to announce a new capability of the AWS Glue Studio visual editor that offers a new visual user experience. Now you can author data preparation transformations and edit them with the AWS Glue Studio visual editor. Within the new experience, you can choose from hundreds of prebuilt transformations.
In addition to real-time analytics and visualization, the data needs to be shared for long-term data analytics and machine learning applications. This approach supports both the immediate needs of visualization tools such as Tableau and the long-term demands of digital twin and IoT data analytics.
Through a visual designer, you can configure custom AI search flowsa series of AI-driven data enrichments performed during ingestion and search. You can use the flow builder through APIs or a visual designer. The visual designer is recommended for helping you manage workflow projects.
AWS Glue Studio is a graphical interface that makes it easy to create, run, and monitor extract, transform, and load (ETL) jobs in AWS Glue. It allows you to visually compose datatransformation workflows using nodes that represent different data handling steps, which later are converted automatically into code to run.
AWS Glue Studio is a graphical interface that makes it easy to create, run, and monitor extract, transform, and load (ETL) jobs in AWS Glue. DataBrew is a visualdata preparation tool that enables you to clean and normalize data without writing any code. Choose Visual with a blank canvas and create the visual job.
With quality data at their disposal, organizations can form data warehouses for the purposes of examining trends and establishing future-facing strategies. Industry-wide, the positive ROI on quality data is well understood. He/she assists the organization by providing clarity and insight into advanced data technology solutions.
You can use AWS Glue Studio to set up data replication and mask PII with no coding required. AWS Glue Studio visual editor provides a low-code graphic environment to build, run, and monitor extract, transform, and load (ETL) scripts. Datatransformation – Adjusts and removes unnecessary fields.
Data analytics draws from a range of disciplines — including computer programming, mathematics, and statistics — to perform analysis on data in an effort to describe, predict, and improve performance. What are the four types of data analytics? Data analytics and data science are closely related.
Attempting to learn more about the role of bigdata (here taken to datasets of high volume, velocity, and variety) within business intelligence today, can sometimes create more confusion than it alleviates, as vital terms are used interchangeably instead of distinctly. Bigdata challenges and solutions.
Let’s go through the ten Azure data pipeline tools Azure Data Factory : This cloud-based data integration service allows you to create data-driven workflows for orchestrating and automating data movement and transformation. You can use it for bigdata analytics and machine learning workloads.
In addition to using native managed AWS services that BMS didn’t need to worry about upgrading, BMS was looking to offer an ETL service to non-technical business users that could visually compose datatransformation workflows and seamlessly run them on the AWS Glue Apache Spark-based serverless data integration engine.
AWS Glue is a serverless data integration service that helps analytics users to discover, prepare, move, and integrate data from multiple sources for analytics, machine learning (ML), and application development. For this example, you use AWS Glue Studio to develop a visual ETL pipeline. Select Visual ETL in the central pane.
Whether you’re looking to earn a certification from an accredited university, gain experience as a new grad, hone vendor-specific skills, or demonstrate your knowledge of data analytics, the following certifications (presented in alphabetical order) will work for you. Check out our list of top bigdata and data analytics certifications.)
AWS Glue provides all the capabilities needed for data integration, so you can start analyzing your data and putting it to use in minutes instead of months. AWS Glue provides both visual and code-based interfaces to make data integration easier. Users can more easily find and access data using the AWS Glue Data Catalog.
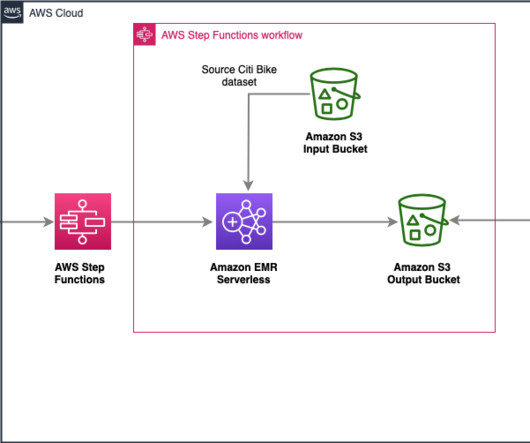
AWS Step Functions is a serverless orchestration service that enables developers to build visual workflows for applications as a series of event-driven steps. The integration between AWS Step Functions and Amazon EMR Serverless makes it easier to manage and orchestrate bigdata workflows. Now, with the support for “Run a Job (.sync)”
But the features in Power BI Premium are now more powerful than the functionality in Azure Analysis Services, so while the service isn’t going away, Microsoft will offer an automated migration tool in the second half of this year for customers who want to move their data models into Power BI instead. Azure Data Factory.
For workloads such as datatransforms, joins, and queries, you can use G.1X With exponentially growing data sources and data lakes, customers want to run more data integration workloads, including their most demanding transforms, aggregations, joins, and queries. 1X (1 DPU) and G.2X You can enable G.4X
This allows business analysts and decision-makers to gain valuable insights, visualize key metrics, and explore the data in depth, enabling informed decision-making and strategic planning for pricing and promotional strategies. On the Visual tab, choose Add nodes. Choose Data source – Snowflake in the AWS Glue Studio canvas.
This dynamic tool, powered by AWS and CARTO, provided robust visualizations of which regions and populations were interacting with our survey, enabling us to zoom in quickly and address gaps in coverage. Figure 1: Workflow illustrating data ingesting, transformation, and visualization using Redshift and CARTO.
The availability of machine-readable files opens up new possibilities for data analytics, allowing organizations to analyze large amounts of pricing data. Using machine learning (ML) and datavisualization tools, these datasets can be transformed into actionable insights that can inform decision-making.
They can use their own toolsets or rely on provided blueprints to ingest the data from source systems. Once released, consumers use datasets from different providers for analysis, machine learning (ML) workloads, and visualization. The difference lies in when and where datatransformation takes place.
The main driving factors include lower total cost of ownership, scalability, stability, improved ingestion connectors (such as Data Prepper , Fluent Bit, and OpenSearch Ingestion), elimination of external cluster managers like Zookeeper, enhanced reporting, and rich visualizations with OpenSearch Dashboards.
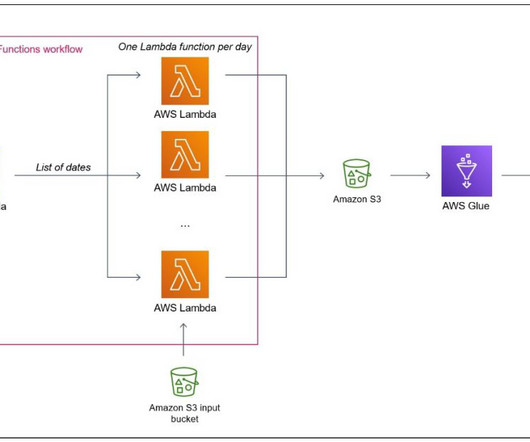
It has not been specifically designed for heavy datatransformation tasks. Configure the Step Functions workflow After you create the two Lambda functions, you can design the Step Functions workflow in the visual editor by using the Lambda Invoke and Map blocks, as shown in the following diagram. Add a data source block.
AWS Glue is a serverless data integration service that makes it straightforward to discover, prepare, and combine data for analytics, machine learning (ML), and application development. AWS Glue provides both visual and code-based interfaces to make data integration effortless. Choose Create job and Visual ETL.
The advent of rapid adoption of serverless data lake architectures—with ever-growing datasets that need to be ingested from a variety of sources, followed by complex datatransformation and machine learning (ML) pipelines—can present a challenge.
Amazon OpenSearch Ingestion is a fully managed serverless pipeline that allows you to ingest, filter, transform, enrich, and route data to an Amazon OpenSearch Service domain or Amazon OpenSearch Serverless collection. You can now view the configurations in JSON format in addition to the YAML format and edit them in place.
In this post, we dive deep into the tool, walking through all steps from log ingestion, transformation, visualization, and architecture design to calculate TCO. With QuickSight, you can visualize YARN log data and conduct analysis against the datasets generated by pre-built dashboard templates and a widget.
Traditionally, such a legacy call center analytics platform would be built on a relational database that stores data from streaming sources. Datatransformations through stored procedures and use of materialized views to curate datasets and generate insights is a known pattern with relational databases.
Let’s look at the key services that enable the federated platform to operate at scale: Data storage and processing: Apache Iceberg on Amazon Simple Storage Service (Amazon S3) offers an optimized way to store data assets and products and promotes interoperability across other services Amazon Redshift allows domain teams to create and manage fit-for-purpose (..)
In addition, more data is becoming available for processing / enrichment of existing and new use cases e.g., recently we have experienced a rapid growth in data collection at the edge and an increase in availability of frameworks for processing that data. As a result, alternative data integration technologies (e.g.,
Attempting to learn more about the role of bigdata (here taken to datasets of high volume, velocity, and variety) within business intelligence today, can sometimes create more confusion than it alleviates, as vital terms are used interchangeably instead of distinctly. Bigdata challenges and solutions. Dig into AI.
You can visualize the PCA insights in the business intelligence (BI) tool Amazon QuickSight for advanced analysis. In this post, we show you how to use PCA’s data to build automated QuickSight dashboards for advanced analytics to assist in quality assurance (QA) and quality management (QM) processes.
With Amazon AppFlow, you can run data flows at nearly any scale at the frequency you choose—on a schedule, in response to a business event, or on demand. You can configure datatransformation capabilities such as filtering and validation to generate rich, ready-to-use data as part of the flow itself, without additional steps.
Kinesis Data Firehose is a fully managed service for delivering near-real-time streaming data to various destinations for storage and performing near-real-time analytics. You can perform analytics on VPC flow logs delivered from your VPC using the Kinesis Data Firehose integration with Datadog as a destination.
Also, such a concept helps admin to visualize the jobs which are scheduled for debugging purposes. Natively support BigData workloads. YuniKorn is designed for BigData app workloads, and it natively supports to run Spark/Flink/Tensorflow, etc efficiently in K8s. Resource fairness. Scale & Performance.
Furthermore, it allows for necessary actions to be taken, such as rectifying errors in the data source, refining datatransformation processes, and updating data quality rules. The following sample email provides operational metrics for the AWS Glue Data Quality ruleset evaluation.
Every time the business requirement changes (such as adding data sources or changing datatransformation logic), you make changes on the AWS Glue app stack and re-provision the stack to reflect your changes. Prerequisites You need the following resources: Python 3.9 jobs locally using a Docker container. aws:/home/glue_user/.aws
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content