This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Athena provides interactive analytics service for analyzing the data in Amazon Simple Storage Service (Amazon S3). Amazon Redshift is used to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes.
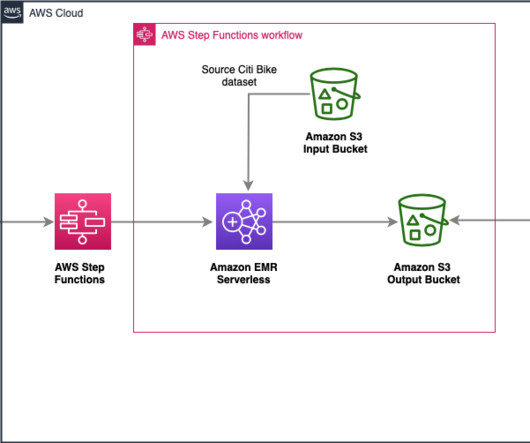
The integration between AWS Step Functions and Amazon EMR Serverless makes it easier to manage and orchestrate bigdata workflows. Karthik Prabhakar is a Senior BigData Solutions Architect for Amazon EMR at AWS. Now, with the support for “Run a Job (.sync)” Summarized output is then written to Amazon S3 bucket.
Amazon EMR on EKS provides a deployment option for Amazon EMR that allows organizations to run open-source bigdata frameworks on Amazon Elastic Kubernetes Service (Amazon EKS). To learn more and get started with EMR on EKS, try out the EMR on EKS Workshop and visit the EMR on EKS Best Practices Guide page. Amazon EMR 6.10
ElastiCache manages the real-time application data caching, allowing your customers to experience microsecond response times while supporting high-throughput handling of hundreds of millions of operations per second. In the inventory management and forecasting solution, AWS Glue is recommended for datatransformation.
The Orca Platform is powered by a state-of-the-art anomaly detection system that uses cutting-edge ML algorithms and bigdata capabilities to detect potential security threats and alert customers in real time, ensuring maximum security for their cloud environment. This ensures that the data is suitable for training purposes.
To run the scripts, refer to the Amazon MWAA analytics workshop. format(S3_BUCKET_NAME), 's3://{}/data/aggregated/green'.format(S3_BUCKET_NAME), To learn more and get hands-on experience, start with the Amazon MWAA analytics workshop and then use the scripts in the GitHub repo to gain more observability of your DAG run.
It has not been specifically designed for heavy datatransformation tasks. It’s scalable and cost-effective, and can be adapted to other ETL and data processing use cases. You can find hands-on labs to improve your knowledge with AWS Workshops. You also use AWS Glue to consolidate the files produced by the parallel tasks.
With these features, you can now build data pipelines completely in standard SQL that are serverless, more simple to build, and able to operate at scale. Typically, datatransformation processes are used to perform this operation, and a final consistent view is stored in an S3 bucket or folder.
Extract, load, Transform (ELT) tools. Data ingestion/integration services. Data orchestration tools. These tools are used to manage bigdata, which is defined as data that is too large or complex to be processed by traditional means. How Did the Modern Data Stack Get Started? Reverse ETL tools.
We also orchestrated the data pipeline using Amazon MWAA, which ran tasks related to datatransformation as well as Snowflake queries. We used Secrets Manager to store Snowflake connection information and credentials and Amazon SNS to publish the data output for end consumption.
The Amazon EMR Flink CDC connector reads the binlog data and processes the data. Transformeddata can be stored in Amazon S3. We use the AWS Glue Data Catalog to store the metadata such as table schema and table location. the Flink table API/SQL can integrate with the AWS Glue Data Catalog.
These include managing complex extract, transform, and load (ETL) processes, handling schema validation, providing reliable delivery, and maintaining custom code for datatransformations. Firehose delivers streaming data with configurable buffering options that can be optimized for near-zero latency.
In Transform records , select Turn on datatransformation. To learn more about using Amazon Data Firehose with Apache Iceberg, see the Firehose Developer Guide or try the Immersion day workshop. For Source , select Direct PUT. For Destination , select Apache Iceberg Tables. For Version select $LATEST.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















Let's personalize your content