

How Gupshup built their multi-tenant messaging analytics platform on Amazon Redshift
AWS Big Data
FEBRUARY 12, 2024
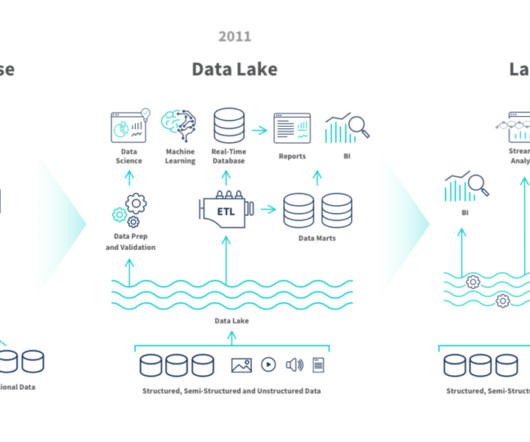
About Redshift and some relevant features for the use case Amazon Redshift is a fully managed, petabyte-scale, massively parallel data warehouse that offers simple operations and high performance. This compiled data is then imported into Aurora PostgreSQL Serverless for operational reporting.


























Let's personalize your content