This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
BladeBridge offers a comprehensive suite of tools that automate much of the complex conversion work, allowing organizations to quickly and reliably transition their data analytics capabilities to the scalable Amazon Redshift datawarehouse. times better price performance than other cloud datawarehouses.
While you may think that you understand the desires of your customers and the growth rate of your company, data-driven decision making is considered a more effective way to reach your goals. The use of bigdata analytics is, therefore, worth considering—as well as the services that have come from this concept, such as Google BigQuery.
The landscape of bigdata management has been transformed by the rising popularity of open table formats such as Apache Iceberg, Apache Hudi, and Linux Foundation Delta Lake. These formats, designed to address the limitations of traditional data storage systems, have become essential in modern data architectures.
Amazon AppFlow automatically encrypts data in motion, and allows you to restrict data from flowing over the public internet for SaaS applications that are integrated with AWS PrivateLink , reducing exposure to security threats. Refer to the Amazon Redshift Database Developer Guide for more details.
Unifying these necessitates additional data processing, requiring each business unit to provision and maintain a separate datawarehouse. This burdens business units focused solely on consuming the curated data for analysis and not concerned with data management tasks, cleansing, or comprehensive data processing.
Amazon Redshift , launched in 2013, has undergone significant evolution since its inception, allowing customers to expand the horizons of data warehousing and SQL analytics. Industry-leading price-performance Amazon Redshift offers up to three times better price-performance than alternative cloud datawarehouses.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud datawarehouse that makes it simple and cost-effective to analyze your data using standard SQL and your existing business intelligence (BI) tools. Data ingestion is the process of getting data to Amazon Redshift.
Data lakes and datawarehouses are two of the most important data storage and management technologies in a modern data architecture. Data lakes store all of an organization’s data, regardless of its format or structure. Delta Lake doesn’t have a specific concept for incremental queries.
Amazon Redshift is a fully managed, AI-powered cloud datawarehouse that delivers the best price-performance for your analytics workloads at any scale. Refer to Easy analytics and cost-optimization with Amazon Redshift Serverless to get started. For this post, we use Redshift Serverless. Choose Run all on each notebook tab.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis.
This post was co-written with Dipankar Mazumdar, Staff Data Engineering Advocate with AWS Partner OneHouse. Data architecture has evolved significantly to handle growing data volumes and diverse workloads. For more examples and references to other posts, refer to the following GitHub repository.
Dating back to the 1970s, the data warehousing market emerged when computer scientist Bill Inmon first coined the term ‘datawarehouse’. Created as on-premise servers, the early datawarehouses were built to perform on just a gigabyte scale. Bigdata and data warehousing.
Amazon Redshift is a fast, scalable, and fully managed cloud datawarehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. Solution overview Amazon Redshift is an industry-leading cloud datawarehouse.
You can now generate data integration jobs for various data sources and destinations, including Amazon Simple Storage Service (Amazon S3) data lakes with popular file formats like CSV, JSON, and Parquet, as well as modern table formats such as Apache Hudi , Delta , and Apache Iceberg.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud datawarehouse that you can use to analyze your data at scale. With Data API session reuse, you can use a single long-lived session at the start of the ETL pipeline and use that persistent context across all ETL phases.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud datawarehouse that lets you analyze your data at scale. Amazon Redshift Serverless lets you access and analyze data without the usual configurations of a provisioned datawarehouse. For more information, refer to Amazon Redshift clusters.
“Without bigdata, you are blind and deaf and in the middle of a freeway.” – Geoffrey Moore, management consultant, and author. In a world dominated by data, it’s more important than ever for businesses to understand how to extract every drop of value from the raft of digital insights available at their fingertips.
SageMaker brings together widely adopted AWS ML and analytics capabilities—virtually all of the components you need for data exploration, preparation, and integration; petabyte-scale bigdata processing; fast SQL analytics; model development and training; governance; and generative AI development.
To succeed in todays landscape, every company small, mid-sized or large must embrace a data-centric mindset. This article proposes a methodology for organizations to implement a modern data management function that can be tailored to meet their unique needs.
One-time and complex queries are two common scenarios in enterprise data analytics. Complex queries, on the other hand, refer to large-scale data processing and in-depth analysis based on petabyte-level datawarehouses in massive data scenarios. Here, data modeling uses dbt on Amazon Redshift.
With Amazon Redshift, you can use standard SQL to query data across your datawarehouse, operational data stores, and data lake. Migrating a datawarehouse can be complex. You have to migrate terabytes or petabytes of data from your legacy system while not disrupting your production workload.
The elasticity of Kinesis Data Streams enables you to scale the stream up or down, so you never lose data records before they expire. Analytical data storage The next service in this solution is Amazon Redshift, a fully managed, petabyte-scale datawarehouse service in the cloud.
Amazon Redshift Serverless makes it simple to run and scale analytics without having to manage your datawarehouse infrastructure. For more details on tagging, refer to Tagging resources overview. For more tagging best practices, refer to Tagging AWS resources. Choose Save changes. About the Authors Sandeep Bajwa is a Sr.
These types of queries are suited for a datawarehouse. The goal of a datawarehouse is to enable businesses to analyze their data fast; this is important because it means they are able to gain valuable insights in a timely manner. Amazon Redshift is fully managed, scalable, cloud datawarehouse.
Enterprise data is brought into data lakes and datawarehouses to carry out analytical, reporting, and data science use cases using AWS analytical services like Amazon Athena , Amazon Redshift , Amazon EMR , and so on. About the author Naidu Rongal i is a BigData and ML engineer at Amazon.
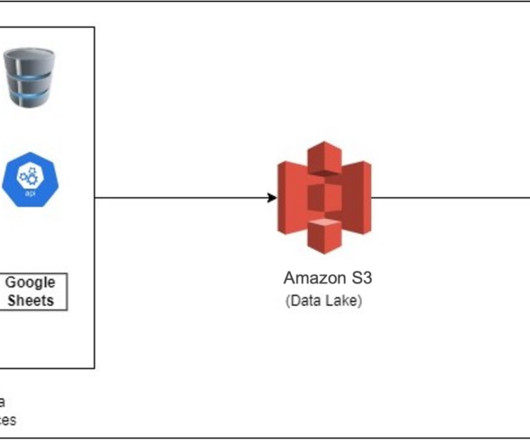
In this post, we discuss how the Kaplan data engineering team implemented data integration from the Salesforce application to Amazon Redshift. Solution overview The high-level data flow starts with the source data stored in Amazon S3 and then integrated into Amazon Redshift using various AWS services.
Bigdata is shaping our world in countless ways. Data powers everything we do. Exactly why, the systems have to ensure adequate, accurate and most importantly, consistent data flow between different systems. A point of data entry in a given pipeline. The destination is decided by the use case of the data pipeline.
Data architect Armando Vázquez identifies eight common types of data architects: Enterprise data architect: These data architects oversee an organization’s overall data architecture, defining data architecture strategy and designing and implementing architectures.
It does so by bringing the familiarity of SQL tables to bigdata and capabilities such as ACID transactions, row-level operations (merge, update, delete), partition evolution, data versioning, incremental processing, and advanced query scanning. He can be reached via LinkedIn. He can be reached via LinkedIn.
Amazon Redshift is the most widely used datawarehouse in the cloud, best suited for analyzing exabytes of data and running complex analytical queries. Amazon QuickSight is a fast business analytics service to build visualizations, perform ad hoc analysis, and quickly get business insights from your data.
Tens of thousands of customers use Amazon Redshift for modern data analytics at scale, delivering up to three times better price-performance and seven times better throughput than other cloud datawarehouses. Refer to IAM Identity Center identity source tutorials for the IdP setup. IAM Identity Center enabled.
Although traditional scaling primarily responds to query queue times, the new AI-driven scaling and optimization feature offers a more sophisticated approach by considering multiple factors including query complexity and data volume. Our findings serve as a reference point rather than a universal benchmark.
Amazon Redshift features like streaming ingestion, Amazon Aurora zero-ETL integration , and data sharing with AWS Data Exchange enable near-real-time processing for trade reporting, risk management, and trade optimization. This will be your OLTP data store for transactional data. version cluster. version cluster.
This blog is intended to give an overview of the considerations you’ll want to make as you build your Redshift datawarehouse to ensure you are getting the optimal performance. OLTP databases are best at queries where we are doing point scans or short scans of the data, think “return the number of deposits by X user this week.”.
For more information, refer SQL models. Seeds – These are CSV files in your dbt project (typically in your seeds directory), which dbt can load into your datawarehouse using the dbt seed command. During the run, dbt creates a Directed Acyclic Graph (DAG) based on the internal reference between the dbt components.
To do that, a data engineer needs to be skilled in a variety of platforms and languages. In our never-ending quest to make BI better, we took it upon ourselves to list the skills and tools every data engineer needs to tackle the ever-growing pile of BigData that every company faces today. Data Warehousing.
Reporting being part of an effective DQM, we will also go through some data quality metrics examples you can use to assess your efforts in the matter. But first, let’s define what data quality actually is. What is the definition of data quality? Why Do You Need Data Quality Management?
Amazon Redshift is a fast, fully managed petabyte-scale cloud datawarehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools. Amazon Redshift also supports querying nested data with complex data types such as struct, array, and map.
The recent announcement of the Microsoft Intelligent Data Platform makes that more obvious, though analytics is only one part of that new brand. Azure Data Factory. Azure Data Explorer. Azure Data Lake Analytics. Datawarehouses are designed for questions you already know you want to ask about your data, again and again.
However, computerization in the digital age creates massive volumes of data, which has resulted in the formation of several industries, all of which rely on data and its ever-increasing relevance. Data analytics and visualization help with many such use cases. It is the time of bigdata. Select a Storage Platform.
With this new functionality, customers can create up-to-date replicas of their data from applications such as Salesforce, ServiceNow, and Zendesk in an Amazon SageMaker Lakehouse and Amazon Redshift. SageMaker Lakehouse gives you the flexibility to access and query your data in-place with all Apache Iceberg compatible tools and engines.
Amazon Redshift is a widely used, fully managed, petabyte-scale cloud datawarehouse. Tens of thousands of customers use Amazon Redshift to process exabytes of data every day to power their analytic workloads. For more information, refer to Migrate Google BigQuery to Amazon Redshift using AWS Schema Conversion tool (SCT).
Amazon Redshift is a fully managed, petabyte-scale datawarehouse service in the cloud. With Amazon Redshift, you can analyze all your data to derive holistic insights about your business and your customers. Amazon Redshift now supports custom URLs or custom domain names for your datawarehouse. Choose Create.
For more details, refer to the What’s New Post. There are two broad approaches to analyzing operational data for these use cases: Analyze the data in-place in the operational database (e.g. For this illustration, we use a provisioned Aurora database and an Amazon Redshift Serverless datawarehouse.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content