This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis.
Testing and Data Observability. We have also included vendors for the specific use cases of ModelOps, MLOps, DataGovOps and DataSecOps which apply DataOps principles to machine learning, AI, data governance, and data security operations. . Genie — Distributed bigdata orchestration service by Netflix.
While you may think that you understand the desires of your customers and the growth rate of your company, data-driven decision making is considered a more effective way to reach your goals. The use of bigdata analytics is, therefore, worth considering—as well as the services that have come from this concept, such as Google BigQuery.
Amazon Redshift is a fast, fully managed cloud datawarehouse that makes it cost-effective to analyze your data using standard SQL and business intelligence tools. However, if you want to test the examples using sample data, download the sample data. The sample files are ‘|’ delimited text files.
Now, with support for dbt Cloud, you can access a managed, cloud-based environment that automates and enhances your data transformation workflows. This upgrade allows you to build, test, and deploy data models in dbt with greater ease and efficiency, using all the features that dbt Cloud provides.
Now with Amazon Bedrock Knowledge Bases integration with structured data, you can use simple, natural language prompts to query complex financial datasets. From customer portals to internal dashboards and mobile apps, this API-driven approach makes enterprise-grade data analysis accessible to everyone in your organization. Choose Test.
Amazon Redshift , launched in 2013, has undergone significant evolution since its inception, allowing customers to expand the horizons of data warehousing and SQL analytics. Industry-leading price-performance Amazon Redshift offers up to three times better price-performance than alternative cloud datawarehouses.
Although traditional scaling primarily responds to query queue times, the new AI-driven scaling and optimization feature offers a more sophisticated approach by considering multiple factors including query complexity and data volume. The following screenshots show the elapsed time breakdown for each test.
Amazon Redshift is a fast, scalable, and fully managed cloud datawarehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. Solution overview Amazon Redshift is an industry-leading cloud datawarehouse.
Data and bigdata analytics are the lifeblood of any successful business. Getting the technology right can be challenging but building the right team with the right skills to undertake data initiatives can be even harder — a challenge reflected in the rising demand for bigdata and analytics skills and certifications.
You can now generate data integration jobs for various data sources and destinations, including Amazon Simple Storage Service (Amazon S3) data lakes with popular file formats like CSV, JSON, and Parquet, as well as modern table formats such as Apache Hudi , Delta , and Apache Iceberg.
This post was co-written with Dipankar Mazumdar, Staff Data Engineering Advocate with AWS Partner OneHouse. Data architecture has evolved significantly to handle growing data volumes and diverse workloads. In case you don’t have sample data available for testing, we provide scripts for generating sample datasets on GitHub.
With Amazon Redshift, you can use standard SQL to query data across your datawarehouse, operational data stores, and data lake. Migrating a datawarehouse can be complex. You have to migrate terabytes or petabytes of data from your legacy system while not disrupting your production workload.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud datawarehouse that lets you analyze your data at scale. Amazon Redshift Serverless lets you access and analyze data without the usual configurations of a provisioned datawarehouse. In her spare time, Blessing loves travels and adventures.
It’s been one decade since the “ BigData Era ” began (and to much acclaim!). Analysts asked, What if we could manage massive volumes and varieties of data? Yet the question remains: How much value have organizations derived from bigdata? BigData as an Enabler of Digital Transformation.
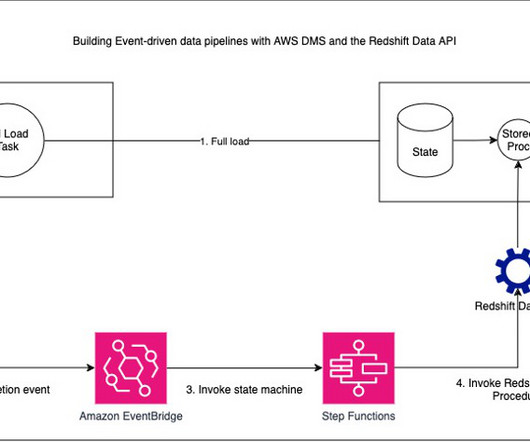
With the launch of Amazon Redshift Serverless and the various provisioned instance deployment options , customers are looking for tools that help them determine the most optimal datawarehouse configuration to support their Amazon Redshift workloads. The following image shows the process flow.
Testing these upgrades involves running the application and addressing issues as they arise. Each test run may reveal new problems, resulting in multiple iterations of changes. About the Authors Noritaka Sekiyama is a Principal BigData Architect on the AWS Glue team. Python 3.7) to Spark 3.3.0
They must also select the data processing frameworks such as Spark, Beam or SQL-based processing and choose tools for ML. Based on business needs and the nature of the data, raw vs structured, organizations should determine whether to set up a datawarehouse, a Lakehouse or consider a data fabric technology.
Amazon Redshift is a fully managed, AI-powered cloud datawarehouse that delivers the best price-performance for your analytics workloads at any scale. This will take a few minutes to run and will establish a query history for the tpcds data. To test this, let’s ask Amazon Q to “delete data from web_sales table.”
Amazon Redshift is a widely used, fully managed, petabyte-scale cloud datawarehouse. Tens of thousands of customers use Amazon Redshift to process exabytes of data every day to power their analytics workloads. Amazon Redshift RA3 with managed storage is the newest instance type for Provisioned clusters.
“Without bigdata, you are blind and deaf and in the middle of a freeway.” – Geoffrey Moore, management consultant, and author. In a world dominated by data, it’s more important than ever for businesses to understand how to extract every drop of value from the raft of digital insights available at their fingertips.
Amazon Redshift is a fully managed, petabyte-scale datawarehouse service in the cloud that delivers powerful and secure insights on all your data with the best price-performance. With Amazon Redshift, you can analyze your data to derive holistic insights about your business and your customers.
Tens of thousands of customers use Amazon Redshift for modern data analytics at scale, delivering up to three times better price-performance and seven times better throughput than other cloud datawarehouses. The application has been tested successfully with versions v3.12.8 Create a Python virtual environment.
Enterprise data is brought into data lakes and datawarehouses to carry out analytical, reporting, and data science use cases using AWS analytical services like Amazon Athena , Amazon Redshift , Amazon EMR , and so on. About the author Naidu Rongal i is a BigData and ML engineer at Amazon.
Bigdata is shaping our world in countless ways. Data powers everything we do. Exactly why, the systems have to ensure adequate, accurate and most importantly, consistent data flow between different systems. A point of data entry in a given pipeline. The destination is decided by the use case of the data pipeline.
Amazon Redshift is a fast, petabyte-scale, cloud datawarehouse that tens of thousands of customers rely on to power their analytics workloads. With its massively parallel processing (MPP) architecture and columnar data storage, Amazon Redshift delivers high price-performance for complex analytical queries against large datasets.
Data architect Armando Vázquez identifies eight common types of data architects: Enterprise data architect: These data architects oversee an organization’s overall data architecture, defining data architecture strategy and designing and implementing architectures.
Large-scale datawarehouse migration to the cloud is a complex and challenging endeavor that many organizations undertake to modernize their data infrastructure, enhance data management capabilities, and unlock new business opportunities. This makes sure the new data platform can meet current and future business goals.
Amazon Redshift is the most widely used datawarehouse in the cloud, best suited for analyzing exabytes of data and running complex analytical queries. Amazon QuickSight is a fast business analytics service to build visualizations, perform ad hoc analysis, and quickly get business insights from your data.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud datawarehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing ETL (extract, transform, and load), business intelligence (BI), and reporting tools. For Name , enter a name (for example, dms-test ).
ActionIQ is a leading composable customer data (CDP) platform designed for enterprise brands to grow faster and deliver meaningful experiences for their customers. This post will demonstrate how ActionIQ built a connector for Amazon Redshift to tap directly into your datawarehouse and deliver a secure, zero-copy CDP.
dbt (DataBuildTool) offers this mechanism by introducing a well-structured framework for data analysis, transformation and orchestration. It also applies general software engineering principles like integrating with git repositories, setting up DRYer code, adding functional test cases, and including external libraries. project-dir.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud datawarehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing ETL (extract, transform, and load), business intelligence (BI), and reporting tools. All columns should masked for them.
To do that, a data engineer needs to be skilled in a variety of platforms and languages. In our never-ending quest to make BI better, we took it upon ourselves to list the skills and tools every data engineer needs to tackle the ever-growing pile of BigData that every company faces today. Data Warehousing.
times better price-performance than other cloud datawarehouses on real-world workloads using advanced techniques like concurrency scaling to support hundreds of concurrent users, enhanced string encoding for faster query performance, and Amazon Redshift Serverless performance enhancements. Amazon Redshift delivers up to 4.9
Source systems Aruba’s source repository includes data from three different operating regions in AMER, EMEA, and APJ, along with one worldwide (WW) data pipeline from varied sources like SAP S/4 HANA, Salesforce, Enterprise DataWarehouse (EDW), Enterprise Analytics Platform (EAP) SharePoint, and more.
As part of the Talent Intelligence Platform Eightfold also exposes a data hub where each customer can access their Amazon Redshift-based datawarehouse and perform ad hoc queries as well as schedule queries for reporting and data export. Many customers have implemented Amazon Redshift to support multi-tenant applications.
The details of each step are as follows: Populate the Amazon Redshift Serverless datawarehouse with company stock information stored in Amazon Simple Storage Service (Amazon S3). Redshift Serverless is a fully functional datawarehouse holding data tables maintained in real time. This is testing for hallucination.
In this post, we delve into the key aspects of using Amazon EMR for modern data management, covering topics such as data governance, data mesh deployment, and streamlined data discovery. Organizations have multiple Hive datawarehouses across EMR clusters, where the metadata gets generated.
Let’s go through the ten Azure data pipeline tools Azure Data Factory : This cloud-based data integration service allows you to create data-driven workflows for orchestrating and automating data movement and transformation. You can use it for bigdata analytics and machine learning workloads.
This can include a multitude of processes, like data profiling, data quality management, or data cleaning, but we will focus on tips and questions to ask when analyzing data to gain the most cost-effective solution for an effective business strategy. Today, bigdata is about business disruption.
Database-centric: In larger organizations, where managing the flow of data is a full-time job, data engineers focus on analytics databases. Database-centric data engineers work with datawarehouses across multiple databases and are responsible for developing table schemas.
Amazon Redshift is a widely used, fully managed, petabyte-scale cloud datawarehouse. Tens of thousands of customers use Amazon Redshift to process exabytes of data every day to power their analytic workloads. He has worked with building datawarehouses and bigdata solutions for over 13 years.
Amazon Redshift is a fast, fully managed, petabyte-scale datawarehouse that provides the flexibility to use provisioned or serverless compute for your analytical workloads. Modern analytics is much wider than SQL-based data warehousing. You can get faster insights without spending valuable time managing your datawarehouse.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content