This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Athena provides interactive analytics service for analyzing the data in Amazon Simple Storage Service (Amazon S3). Amazon Redshift is used to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes. Table metadata is fetched from AWS Glue.
However, commits can still fail if the latest metadata is updated after the base metadata version is established. Iceberg uses a layered architecture to manage table state and data: Catalog layer Maintains a pointer to the current table metadata file, serving as the single source of truth for table state.
The landscape of bigdata management has been transformed by the rising popularity of open table formats such as Apache Iceberg, Apache Hudi, and Linux Foundation Delta Lake. These formats, designed to address the limitations of traditional data storage systems, have become essential in modern data architectures.
Eventually, transactional data lakes emerged to add transactional consistency and performance of a data warehouse to the data lake. Central to a transactional data lake are open table formats (OTFs) such as Apache Hudi , Apache Iceberg , and Delta Lake , which act as a metadata layer over columnar formats.
Open table formats are emerging in the rapidly evolving domain of bigdata management, fundamentally altering the landscape of data storage and analysis. For more details, refer to Iceberg Release 1.6.1. These are useful for flexible data lifecycle management. For more details, refer to Delta Lake Release 3.2.1.
Iceberg offers distinct advantages through its metadata layer over Parquet, such as improved data management, performance optimization, and integration with various query engines. Icebergs table format separates data files from metadata files, enabling efficient data modifications without full dataset rewrites.
Amazon Q generative SQL for Amazon Redshift uses generative AI to analyze user intent, query patterns, and schema metadata to identify common SQL query patterns directly within Amazon Redshift, accelerating the query authoring process for users and reducing the time required to derive actionable data insights.
Whether youre a data analyst seeking a specific metric or a data steward validating metadata compliance, this update delivers a more precise, governed, and intuitive search experience. Start using this enhanced search capability today and experience the difference it brings to your data discovery journey.
What Is Metadata? Metadata is information about data. A clothing catalog or dictionary are both examples of metadata repositories. Indeed, a popular online catalog, like Amazon, offers rich metadata around products to guide shoppers: ratings, reviews, and product details are all examples of metadata.
Solution overview By combining the powerful vector search capabilities of OpenSearch Service with the access control features provided by Amazon Cognito , this solution enables organizations to manage access controls based on custom user attributes and document metadata. Refer to Service Quotas for more details.
BladeBridge offers a comprehensive suite of tools that automate much of the complex conversion work, allowing organizations to quickly and reliably transition their data analytics capabilities to the scalable Amazon Redshift data warehouse. Amazon Redshift is a fully managed data warehouse service offered by Amazon Web Services (AWS).
If you’re a mystery lover, I’m sure you’ve read that classic tale: Sherlock Holmes and the Case of the Deceptive Data, and you know how a metadata catalog was a key plot element. In The Case of the Deceptive Data, Holmes is approached by B.I. He goes on to explain: Reasons for inaccurate data. Bigdata is BIG.
The Eightfold Talent Intelligence Platform integrates with Amazon Redshift metadata security to implement visibility of data catalog listing of names of databases, schemas, tables, views, stored procedures, and functions in Amazon Redshift. This post discusses restricting listing of data catalog metadata as per the granted permissions.
Pricing and availability Amazon MWAA pricing dimensions remains unchanged, and you only pay for what you use: The environment class Metadata database storage consumed Metadata database storage pricing remains the same. Refer to Amazon Managed Workflows for Apache Airflow Pricing for rates and more details.
We have enhanced data sharing performance with improved metadata handling, resulting in data sharing first query execution that is up to four times faster when the data sharing producers data is being updated. Industry-leading price-performance: Amazon Redshift launches RA3.large
We’re excited to announce a new feature in Amazon DataZone that offers enhanced metadata governance for your subscription approval process. With this update, domain owners can define and enforce metadata requirements for data consumers when they request access to data assets.
Row type – Enable this option to display only rows that have at least one cell with authorized data. Unfiltered Table Metadata This tab displays the response of the AWS Glue API GetUnfilteredTableMetadata policies for the selected table. About the Authors Stefano Sandonà is a Senior BigData Specialist Solution Architect at AWS.
reduces the Amazon DynamoDB cost associated with KCL by optimizing read operations on the DynamoDB table storing metadata. KCL uses DynamoDB to store metadata such as shard-worker mapping and checkpoints. x benefits, refer to Use features of the AWS SDK for Java 2.x. Refer to Step 4 of Migrating from KCL 2.x x to KCL 3.x
Reporting being part of an effective DQM, we will also go through some data quality metrics examples you can use to assess your efforts in the matter. But first, let’s define what data quality actually is. What is the definition of data quality? Why Do You Need Data Quality Management? 2 – Data profiling.
The book is awesome, an absolute must-have reference volume, and it is free (for now, downloadable from Neo4j ). Any node and its relationship to a particular node becomes a type of contextual metadata for that particular note. Graph Algorithms book. Context may include time, location, related events, nearby entities, and more.
For instructions, refer to How to Set Up a MongoDB Cluster. Configure PrivateLink by following the steps described in Connecting Applications Securely to a MongoDB Atlas Data Plane with AWS PrivateLink. Choose the table to view the schema and other metadata. Sandeep Adwankar is a Senior Technical Product Manager at AWS.
The following are the key components and steps in the integration process: Zero-ETL extracts and loads the data into Amazon S3 , a highly scalable object storage service. The data is also registered in the Glue Data Catalog , a metadata repository. BigData and ETL Solutions Architect, Amazon MWAA and AWS Glue ETL expert.
Data poisoning attacks. Data poisoning refers to someone systematically changing your training data to manipulate your model’s predictions. Data poisoning attacks have also been called “causative” attacks.) To poison data, an attacker must have access to some or all of your training data.
Governed Tables metadata will continue to exist within the AWS Glue Data Catalog, and the Governed Tables data will remain in your S3 buckets. In this case, refer to Use CTAS and INSERT INTO to work around the 100 partition limit. About the author Mert Hocanin is a Principal BigData Architect with AWS Lake Formation.
Cloud data architect: The cloud data architect designs and implements data architecture for cloud-based platforms such as AWS, Azure, and Google Cloud Platform. Data security architect: The data security architect works closely with security teams and IT teams to design data security architectures.
SageMaker brings together widely adopted AWS ML and analytics capabilities—virtually all of the components you need for data exploration, preparation, and integration; petabyte-scale bigdata processing; fast SQL analytics; model development and training; governance; and generative AI development.
We use AWS Glue , a fully managed, serverless, ETL (extract, transform, and load) service, and the Google BigQuery Connector for AWS Glue (for more information, refer to Migrating data from Google BigQuery to Amazon S3 using AWS Glue custom connectors ). If you don’t have one, refer to Amazon Redshift Serverless. An S3 bucket.
Since its inception, Apache Kafka has depended on Apache Zookeeper for storing and replicating the metadata of Kafka brokers and topics. the Kafka community has adopted KRaft (Apache Kafka on Raft), a consensus protocol, to replace Kafka’s dependency on ZooKeeper for metadata management. For Metadata mode , select KRaft.
The AWS Glue Data Catalog now enhances managed table optimization of Apache Iceberg tables by automatically removing data files that are no longer needed. Iceberg creates a new version called a snapshot for every change to the data in the table. The customer table data and metadata are stored in the S3 bucket.
But most important of all, the assumed dormant value in the unstructured data is a question mark, which can only be answered after these sophisticated techniques have been applied. Therefore, there is a need to being able to analyze and extract value from the data economically and flexibly. The solution integrates data in three tiers.
Let’s briefly describe the capabilities of the AWS services we referred above: AWS Glue is a fully managed, serverless, and scalable extract, transform, and load (ETL) service that simplifies the process of discovering, preparing, and loading data for analytics. Amazon Athena is used to query, and explore the data.
This approach streamlines data access while ensuring proper governance. To learn more about working with events using EventBridge, refer to Events via Amazon EventBridge default bus. After you create the asset, you can add glossaries or metadata forms, but its not necessary for this post. Enter a name for the asset.
Understanding the data governance trends for the year ahead will give business leaders and data professionals a competitive edge … Happy New Year! Regulatory compliance and data breaches have driven the data governance narrative during the past few years.
It shows a call center streaming data source that sends the latest call center feed in every 15 seconds. The second streaming data source constitutes metadata information about the call center organization and agents that gets refreshed throughout the day. We use two datasets in this post.
In our previous post Improve operational efficiencies of Apache Iceberg tables built on Amazon S3 data lakes , we discussed how you can implement solutions to improve operational efficiencies of your Amazon Simple Storage Service (Amazon S3) data lake that is using the Apache Iceberg open table format and running on the Amazon EMR bigdata platform.
Metadata management performs a critical role within the modern data management stack. It helps blur data silos, and empowers data and analytics teams to better understand the context and quality of data. This, in turn, builds trust in data and the decision-making to follow. Improve data discovery.
Benchmark setup In our testing, we used the 3 TB dataset stored in Amazon S3 in compressed Parquet format and metadata for databases and tables is stored in the AWS Glue Data Catalog. This benchmark uses unmodified TPC-DS data schema and table relationships. He has been focusing in the bigdata analytics space since 2014.
The Business Application Research Center (BARC) warns that data governance is a highly complex, ongoing program, not a “big bang initiative,” and it runs the risk of participants losing trust and interest over time. The program must introduce and support standardization of enterprise data.
This approach simplifies your data journey and helps you meet your security requirements. The SageMaker Lakehouse data connection testing capability boosts your confidence in established connections. To learn more, refer to Amazon SageMaker Unified Studio.
They chose AWS Glue as their preferred data integration tool due to its serverless nature, low maintenance, ability to control compute resources in advance, and scale when needed. To share the datasets, they needed a way to share access to the data and access to catalog metadata in the form of tables and views.
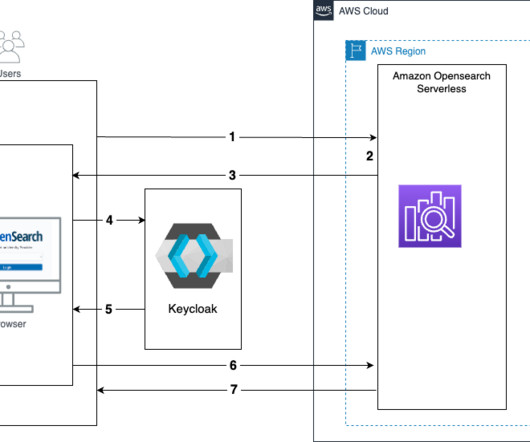
aoss:UpdateSecurityConfig – Modify a given SAML provider configuration, including the XML metadata. For more details, refer to Considerations. IdP Metadata by choosing the link on the Realm settings page. You need this metadata, when you create the SAML provider in OpenSearch Serverless. Choose Create SAML provider.
These formats enable ACID (atomicity, consistency, isolation, durability) transactions, upserts, and deletes, and advanced features such as time travel and snapshots that were previously only available in data warehouses. For more information, refer to Amazon S3: Allows read and write access to objects in an S3 Bucket.
Backup and restore architecture The backup and restore strategy involves periodically backing up Amazon MWAA metadata to Amazon Simple Storage Service (Amazon S3) buckets in the primary Region. Refer to the detailed deployment steps in the README file to deploy it in your own accounts. The steps are as follows: [1.a]
Amazon Managed Workflows for Apache Airflow (Amazon MWAA) is a managed orchestration service for Apache Airflow that you can use to set up and operate data pipelines in the cloud at scale. Apache Airflow is an open source tool used to programmatically author, schedule, and monitor sequences of processes and tasks, referred to as workflows.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content