This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Ali Tore, Senior Vice President of Advanced Analytics at Salesforce, highlighting the value of this integration, says “We’re excited to partner with Amazon to bring Tableau’s powerful data exploration and AI-driven analytics capabilities to customers managing data across organizational boundaries with Amazon DataZone.
Content includes reports, documents, articles, presentations, visualizations, video, and audio representations of the insights and knowledge that have been extracted from data. We could further refine our opening statement to say that our business users are too often in a state of being data-rich, but insights-poor, and content-hungry.
There are countless examples of bigdata transforming many different industries. It can be used for something as visual as reducing traffic jams, to personalizing products and services, to improving the experience in multiplayer video games. We would like to talk about datavisualization and its role in the bigdata movement.
In the era of bigdata, data lakes have emerged as a cornerstone for storing vast amounts of raw data in its native format. They support structured, semi-structured, and unstructured data, offering a flexible and scalable environment for data ingestion from multiple sources.
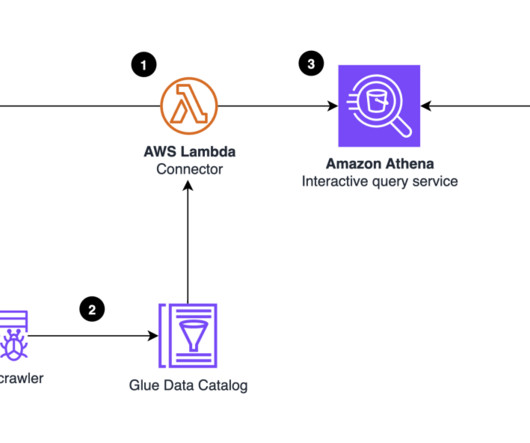
In addition to real-time analytics and visualization, the data needs to be shared for long-term data analytics and machine learning applications. From here, the metadata is published to Amazon DataZone by using AWS Glue Data Catalog. This process is shown in the following figure.
What Is Metadata? Metadata is information about data. A clothing catalog or dictionary are both examples of metadata repositories. Indeed, a popular online catalog, like Amazon, offers rich metadata around products to guide shoppers: ratings, reviews, and product details are all examples of metadata.
Customer relationship management (CRM) platforms are very reliant on bigdata. As these platforms become more widely used, some of the data resources they depend on become more stretched. CRM providers need to find ways to address the technical debt problem they are facing through new bigdata initiatives.
This approach simplifies your data journey and helps you meet your security requirements. The SageMaker Lakehouse data connection testing capability boosts your confidence in established connections. You can navigate to the projects Data page to visually verify the existence of the newly created table. Choose Save.
OpenSearch Service stores different types of stored objects, such as dashboards, visualizations, alerts, security roles, index templates, and more, within the domain. As your user base and number of Amazon OpenSearch Service domains grow, tracking activities and changes to those saved objects becomes increasingly difficult.
In order to figure out why the numbers in the two reports didn’t match, Steve needed to understand everything about the data that made up those reports – when the report was created, who created it, any changes made to it, which system it was created in, etc. Enterprise data governance. Metadata in data governance.
We are excited to announce the preview of API-driven, OpenLineage-compatible data lineage in Amazon DataZone to help you capture, store, and visualize lineage of data movement and transformations of data assets on Amazon DataZone. The lineage visualized includes activities inside the Amazon DataZone business data catalog.
Web developers utilized data to some capacity as well, but marketers rarely considered doing so. Bigdata has become critical to the evolution of digital marketing. Some of the benefits are detailed below: Optimizing metadata for greater reach and branding benefits. One of the most overlooked factors is metadata.
DynamoDB offers built-in security, continuous backups, automated multi-Region replication, in-memory caching, and data import and export tools. The scalability and flexible data schema of DynamoDB make it well-suited for a variety of use cases. Data stored in DynamoDB is the basis for valuable business intelligence (BI) insights.
For the purposes of this post, we use a local machine based on MacOS and Visual Studio Code as our integrated development environment (IDE), but you could use your preferred development environment and IDE. Row type – Enable this option to display only rows that have at least one cell with authorized data.
Institutional Data & AI Platform architecture The Institutional Division has implemented a self-service data platform to enable the domain teams to build and manage data products autonomously. The following diagram illustrates the building blocks of the Institutional Data & AI Platform.
QuickSight makes it straightforward for business users to visualizedata in interactive dashboards and reports. An AWS Glue crawler scans data on the S3 bucket and populates table metadata on the AWS Glue Data Catalog. Looking at the Skewness Job per Job visualization, there was spike on November 1, 2023.
Review the MongoDB AWS Glue database and table We can navigate to the AWS Glue Data Catalog to examine the tables that were created by the crawler. Choose the table to view the schema and other metadata. Note that the crawler captured nested data as a STRUCT and correctly listed the ARRAY fields. Choose Create job.
After you create a connection once, you can choose to use the same connection across various AWS Glue components including Glue ETL, Glue Visual ETL and zero-ETL. The following are the key components and steps in the integration process: Zero-ETL extracts and loads the data into Amazon S3 , a highly scalable object storage service.
SageMaker brings together widely adopted AWS ML and analytics capabilities—virtually all of the components you need for data exploration, preparation, and integration; petabyte-scale bigdata processing; fast SQL analytics; model development and training; governance; and generative AI development.
Through a visual designer, you can configure custom AI search flowsa series of AI-driven data enrichments performed during ingestion and search. You can use the flow builder through APIs or a visual designer. The visual designer is recommended for helping you manage workflow projects. that can operate on text and images.
Working with massive structured and unstructured data sets can turn out to be complicated. It’s obvious that you’ll want to use bigdata, but it’s not so obvious how you’re going to work with it. So, let’s have a close look at some of the best strategies to work with large data sets. It’s a good idea to record metadata.
You can use AWS Glue Studio to set up data replication and mask PII with no coding required. AWS Glue Studio visual editor provides a low-code graphic environment to build, run, and monitor extract, transform, and load (ETL) scripts. This helps you to discover and work with the data to build ETL jobs.
Advancement in bigdata technology has made the world of business even more competitive. The proper use of business intelligence and analytical data is what drives big brands in a competitive market. Business intelligence tools can include data warehousing, datavisualizations, dashboards, and reporting.
Data architect role Data architects are senior visionaries who translate business requirements into technology requirements and define data standards and principles, often in support of data or digital transformations. Data architect vs. data engineer The data architect and data engineer roles are closely related.
They realized that the search results would probably not provide an answer to my question, but the results would simply list websites that included my words on the page or in the metadata tags: “Texas”, “Cows”, “How”, etc.
The next generation of SageMaker also introduces new capabilities, including Amazon SageMaker Unified Studio (preview) , Amazon SageMaker Lakehouse , and Amazon SageMaker Data and AI Governance. These metadata tables are stored in S3 Tables, the new S3 storage offering optimized for tabular data. With AWS Glue 5.0,
With quality data at their disposal, organizations can form data warehouses for the purposes of examining trends and establishing future-facing strategies. Industry-wide, the positive ROI on quality data is well understood. He/she assists the organization by providing clarity and insight into advanced data technology solutions.
Data engineers use Apache Iceberg because it’s fast, efficient, and reliable at any scale and keeps records of how datasets change over time. Apache Iceberg offers integrations with popular data processing frameworks such as Apache Spark, Apache Flink, Apache Hive, Presto, and more.
We have enhanced data sharing performance with improved metadata handling, resulting in data sharing first query execution that is up to four times faster when the data sharing producers data is being updated.
Let’s briefly describe the capabilities of the AWS services we referred above: AWS Glue is a fully managed, serverless, and scalable extract, transform, and load (ETL) service that simplifies the process of discovering, preparing, and loading data for analytics. Amazon Athena is used to query, and explore the data.
But most important of all, the assumed dormant value in the unstructured data is a question mark, which can only be answered after these sophisticated techniques have been applied. Therefore, there is a need to being able to analyze and extract value from the data economically and flexibly. The solution integrates data in three tiers.
What is Data Modeling? Data modeling is a process that enables organizations to discover, design, visualize, standardize and deploy high-quality data assets through an intuitive, graphical interface. Data models provide visualization, create additional metadata and standardize data design across the enterprise.
And it exists across these hybrid architectures in different formats: big and unstructured and traditional structured business data may physically sit in different places. What’s desperately needed is a way to understand the relationships and interconnections between so many entities in data sets in detail.
In addition to using native managed AWS services that BMS didn’t need to worry about upgrading, BMS was looking to offer an ETL service to non-technical business users that could visually compose data transformation workflows and seamlessly run them on the AWS Glue Apache Spark-based serverless data integration engine.
It shows a call center streaming data source that sends the latest call center feed in every 15 seconds. The second streaming data source constitutes metadata information about the call center organization and agents that gets refreshed throughout the day. client("s3") S3_BUCKET = ' ' kinesis_client = boto3.client("kinesis")
To interact with and analyze data stored in Amazon Redshift, AWS provides the Amazon Redshift Query Editor V2 , a web-based tool that allows you to explore, analyze, and share data using SQL. The Query Editor V2 offers a user-friendly interface for connecting to your Redshift clusters, executing queries, and visualizing results.
AWS Glue Data Catalog stores information as metadata tables, where each table specifies a single data store. The AWS Glue crawler writes metadata to the Data Catalog by classifying the data to determine the format, schema, and associated properties of the data. BigData Architect.
To address the issue of data quality, Amazon DataZone now integrates directly with AWS Glue Data Quality, allowing you to visualizedata quality scores for AWS Glue Data Catalog assets directly within the Amazon DataZone web portal. Amazon DataZone natively supports data sharing for Amazon Redshift data assets.
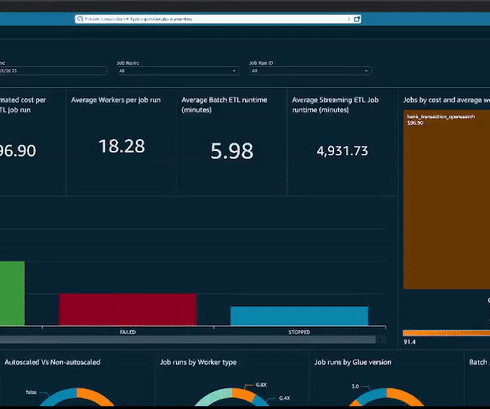
In this post, we explore how to combine AWS Glue usage information and metrics with centralized reporting and visualization using QuickSight. You have metrics available per job run within the AWS Glue console, but they don’t cover all available AWS Glue job metrics, and the visuals aren’t as interactive compared to the QuickSight dashboard.
Understanding the data governance trends for the year ahead will give business leaders and data professionals a competitive edge … Happy New Year! Regulatory compliance and data breaches have driven the data governance narrative during the past few years.
Cargotec captures terabytes of IoT telemetry data from their machinery operated by numerous customers across the globe. This data needs to be ingested into a data lake, transformed, and made available for analytics, machine learning (ML), and visualization. The target accounts read data from the source account S3 buckets.
The program must introduce and support standardization of enterprise data. Programs must support proactive and reactive change management activities for reference data values and the structure/use of master data and metadata.
Both the investment community and the IT circle are paying close attention to bigdata and business intelligence. Metadata management. Users can centrally manage metadata, including searching, extracting, processing, storing, sharing metadata, and publishing metadata externally. Analytics dashboards.
The publishing and subscription workflows of DataZone enhance collaboration between various roles in your organization and speed up the time to derive business insights from your data. You can enhance the technical metadata of the Data Catalog using AI-powered assistants into business metadata of DataZone, making it more easily discoverable.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content