This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Athena provides interactive analytics service for analyzing the data in Amazon Simple Storage Service (Amazon S3). Amazon Redshift is used to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes. Table metadata is fetched from AWS Glue.
Amazon EMR on EKS provides a deployment option for Amazon EMR that allows organizations to run open-source bigdata frameworks on Amazon Elastic Kubernetes Service (Amazon EKS). To learn more and get started with EMR on EKS, try out the EMR on EKS Workshop and visit the EMR on EKS Best Practices Guide page. Amazon EMR 6.10
Distributed systems and models : For better or worse, we live in the age of bigdata. Many organizations are now using distributed data processing and machine learning systems. Proceedings of the 11th ACM Workshop on Artificial Intelligence and Security. ACM (2018). URL: [link]. Conclusion.
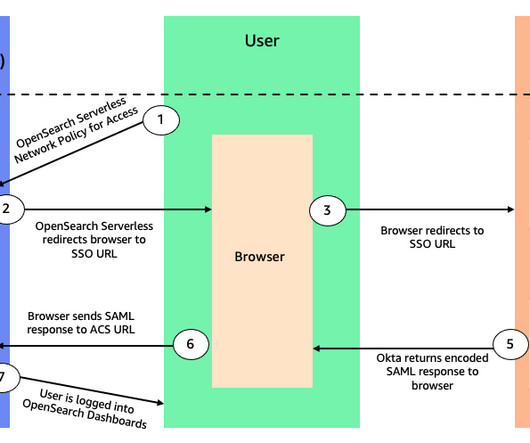
aoss.amazonaws.com/_saml/acs (replace with the corresponding Region) to generate the IdP metadata. After an app is created, choose the sign-on tab, scroll down to the metadata details, and copy the value for Metadata URL. Open a new tab and enter the copied metadata URL into your browser. Select I’m a software vendor.
The Orca Platform is powered by a state-of-the-art anomaly detection system that uses cutting-edge ML algorithms and bigdata capabilities to detect potential security threats and alert customers in real time, ensuring maximum security for their cloud environment. Why did Orca choose Apache Iceberg?
Under IAM Identity Center metadata , choose Download under IAM Identity Center SAML metadata file. We use this metadata file to create a SAML provider under OpenSearch Serverless. Under Application metadata , select Manually type your metadata values. Enter the metadata from your IdP that you downloaded earlier.
Remote runtime data integration as-a-service execution capabilities for on-premises and multi-cloud execution. Multi-directional data movement topology with high volume and low-latency integration. Support for data governance. Metadata exchange with third party metadata management and governance tools.
It ingests data from both streaming and batch sources and organizes it into logical tables distributed across multiple nodes in a Pinot cluster, ensuring scalability. Pinot provides functionality similar to other modern bigdata frameworks, supporting SQL queries, upserts, complex joins, and various indexing options.
For additional details on this feature, refer to AWS Lake Formation-managed Redshift datashares (preview) and How Redshift data share can be managed by Lake Formation. Amazon EMR is a managed cluster platform to run bigdata applications using Apache Spark, Apache Hive, Apache HBase, Apache Flink, Apache Hudi, and Presto at scale.
To run the scripts, refer to the Amazon MWAA analytics workshop. To learn more and get hands-on experience, start with the Amazon MWAA analytics workshop and then use the scripts in the GitHub repo to gain more observability of your DAG run. DAG definitions In this section, we look at snippets of the additions needed to the DAG file.
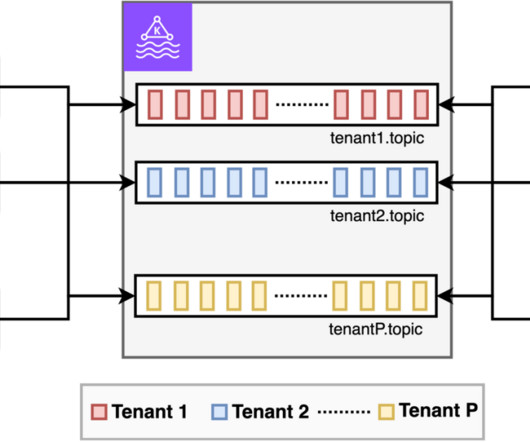
The options available with Kafka are passing the tenant ID either as event metadata (header) or part of the payload itself as an explicit field. Carefully weighing your streaming outcomes and customer needs will help determine the correct trade-offs you can make while making sure your customer data is secure and auditable.
Priority 2 logs, such as operating system security logs, firewall, identity provider (IdP), email metadata, and AWS CloudTrail , are ingested into Amazon OpenSearch Service to enable the following capabilities. Previously, P2 logs were ingested into the SIEM.
. // It serves as a simple API Gateway to Kafka Proxy, accepting requests and forwarding them to a Kafka topic. withBody("Message successfully pushed to kafka"); } catch (Exception e) { // In case of exception, log the error message and return a 500 status code log.error(e.getMessage(), e); return response.withBody(e.getMessage()).withStatusCode(500);
At a high level, the core of Langley’s architecture is based on a set of Amazon Simple Queue Service (Amazon SQS) queues and AWS Lambda functions, and a dedicated RDS database to store ETL job data and metadata. Amazon MWAA offers one-click updates of the infrastructure for minor versions, like moving from Airflow version x.4.z
If not, refer to the Setting up Prometheus and Grafana for monitoring the cluster section of the Running batch workloads on Amazon EKS workshop to get them up and running on your cluster. To cleanup your EMR on EKS cluster after trying out the vertical autoscaling feature, refer to the clean-up section of the EMR on EKS workshop.
With a unified data catalog, you can quickly search datasets and figure out data schema, data format, and location. The AWS Glue Data Catalog provides a uniform repository where disparate systems can store and find metadata to keep track of data in data silos. Refer to Catalogs for more information.
OpenSearch Serverless caches the most recent log data, typically the first 24 hours, on ephemeral disk. For data older than 24 hours, OpenSearch Serverless only caches metadata and fetches the necessary data blocks from Amazon S3 based on query access. This model also helps pack more data while controlling the costs.
Step 3: For six to eight weeks leading up to the presentation date, offer applied training to the teams on developing these artifacts through workshops on their specific use cases. Bolster development teams by inviting diverse, multidisciplinary teams to join them in these workshops as they assess ethics and model risk.
ans from Nick Elprin, CEO and co-founder of Domino Data Lab, about the importance of model-driven business: “Being data-driven is like navigating by watching the rearview mirror. If your business is using bigdata and putting dashboards in front of analysts, you’re missing the point.”. I consider that a healthy trend.
SS4O is inspired by both OpenTelemetry and the Elastic Common Schema (ECS) and uses Amazon Elastic Container Service ( Amazon ECS ) event logs and OpenTelemetry (OTel) metadata. You can get started by having hands-on experience with the publicly available workshops for semantic search , microservice observability , and OpenSearch Serverless.
Data ingestion/integration services. Data orchestration tools. These tools are used to manage bigdata, which is defined as data that is too large or complex to be processed by traditional means. How Did the Modern Data Stack Get Started? What Are the Benefits of a Modern Data Stack?
Since much of the work is siloed, there are entire markets focused on, for example, data privacy tools, data security tools, data quality tools and more. We cannot of course forget metadata management tools, of which there are many different. But for them, bigdata evolved into all data and all formats.
Paco Nathan’s latest article covers data practices from the National Oceanic and Atmospheric Administration (NOAA) Environment Data Management (EDM) workshop as well as updates from the AI Conference. Data Science meets Climate Science. At the EDM workshop, I gave a keynote about AI adoption in industry.
By virtue of that, if you take those log files of customers interactions, you aggregate them, then you take that aggregated data, run machine learning models on them, you can produce data products that you feed back into your web apps, and then you get this kind of effect in business. That was the origin of bigdata.
Aligning the solution with the data strategy At an early stage of the project, the Volkswagen Autoeuropa and AWS team identified that a data mesh architecture for the data solution aligns with the Volkswagen Autoeuropa’s vision of becoming a data-driven factory.
To learn more about how to process Firehose records using Lambda, see Transform source data in Amazon Data Firehose. After executing your Lambda function, Firehose looks for routing information and operations in the metadata fields (in the following format) provided by your Lambda function. b64decode(record['data']).decode('utf-8')
When Firehose delivers data to the S3 table, it uses the AWS Glue Data Catalog to store and manage table metadata. This metadata includes schema information, partition details, and file locations, enabling seamless data discovery and querying across AWS analytics services.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content