This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A series of materialized view refreshes are used to calculate metrics, after which the incremental data from S3 is loaded into Redshift. This compiled data is then imported into Aurora PostgreSQL Serverless for operationalreporting. Incremental analytics is the main reason for Gupshup to use Redshift. “The
The application supports custom workflows to allow demand and supply planning teams to collaborate, plan, source, and fulfill customer orders, then track fulfillment metrics via persona-based operational and management reports and dashboards. In his spare time, he likes reading, exploring new places and watching movies.
Azure Data Lakes are highly complex and designed with a different fundamental purpose in mind than financial and operationalreporting. For more on Azure Data Lakes, download this guide: “ Diving into Data Lakes: Is Microsoft’s Modern Data Warehouse Architecture Right for Your Business? ”.
Conclusion In this post, we showed how to use AWS Glue and the new connector for ingesting data from Azure Blob Storage to Amazon S3. This connector provides access to Azure Blob Storage, facilitating cloud ETL processes for operationalreporting, backup and disaster recovery, data governance, and more.
Capacity monitoring dashboards As part of our platform management process, we conduct monthly operational reviews to maintain optimal performance. This involves analyzing an automated operationalreport that covers all the systems on the platform.
Conclusion In this post, we showed how to use AWS Glue and the new connector for ingesting data from Google Cloud Storage to Amazon S3. This connector provides access to Google Cloud Storage, facilitating cloud ETL processes for operationalreporting, backup and disaster recovery, data governance, and more.
Introducing the SFTP connector for AWS Glue The SFTP connector for AWS Glue simplifies the process of connecting AWS Glue jobs to extract data from SFTP storage and to load data into SFTP storage. Solution overview In this example, you use AWS Glue Studio to connect to an SFTP server, then enrich that data and upload it to Amazon S3.
Correlations across data domains, even if they are not traditionally stored together (e.g. real-time customer event data alongside CRM data; network sensor data alongside marketing campaign management data). The extreme scale of “bigdata”, but with the feel and semantics of “small data”.
The data products used inside the company include insights from user journeys, operationalreports, and marketing campaign results, among others. The data platform serves on average 60 thousand queries per day. The data volume is in double-digit TBs with steady growth as business and data sources evolve.
A 2023 New Vantage Partners/Wavestone executive survey highlights how being data-driven is not getting any easier as many blue-chip companies still struggle to maximize ROI from their plunge into data and analytics and embrace a real data-driven culture: 19.3% report they have established a data culture 26.5%
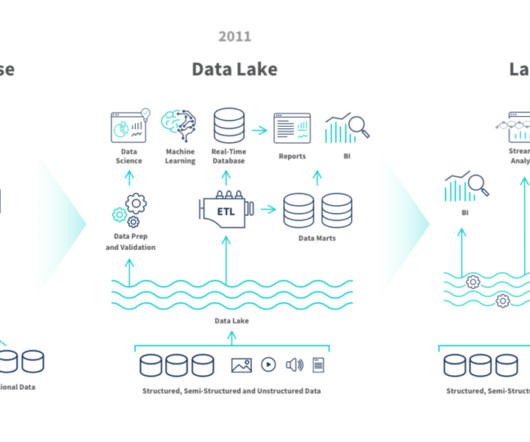
Reporting: A Few Technical Basics. Financial and operationalreports retrieve master data and transactional information from your ERP databases using something called “SQL.” Data lake” is a generic term that refers to a fairly new development in the world of bigdata analytics.
For more than 10 years, the publisher has used IBM Cognos Analytics to wrangle its internal and external operationalreporting needs. And in the last few years, the team realized there was an opportunity to expand beyond centralized operationalreporting to enable further business growth.
Δ The post 3 Easy Steps to Finding Patterns in BigData appeared first on insightsoftware. Enable cookies. How insightsoftware is using cookies. Still experiencing an issue? Please contact our website administration team. Δ
Because out-of-the-box features are limited, it’s all-too common for organizations to settle for static reports without deeper analytics or drill-down options. This means reporting stakeholders dont have access to real-time or refreshable data to delve deeper and answer their own questions.
Apache Iceberg is an open table format for huge analytic datasets designed to bring high-performance ACID (Atomicity, Consistency, Isolation, and Durability) transactions to bigdata. Some of the popular query engines include: Spark: Known for its speed and ease of use in bigdata processing.
Since then, technology has improved in leaps and bounds and data management has become more complicated. As a response to emerging technology, data lakes took off along with the rise of bigdata. To address this, the data lakehouse was born.
Financial services companies can use data pipelines to integrate and manage bigdata from multiple sources for historical trend analysis. Analyzing historical transaction data in financial reporting can help identify market trends and investment opportunities.
By integrating Vizlib, businesses can truly maximize their Qlik investment, improving decision-making efficiency and gaining deeper insights from their data. The Growing Importance of Data Visualization In the era of bigdata, the ability to visualize information has become a cornerstone of effective business analytics.
Logi Symphony Technical Brochure Download Now Logi Symphony & Google Cloud Marketplace This year, Logi Symphony became available on Google Cloud Marketplace to bring together the best of both worlds: a powerful, scalable cloud infrastructure and an industry-leading embedded analytics platform.
Ideally, your primary data source should belong in this group. Modern Data Sources Painlessly connect with modern data such as streaming, search, bigdata, NoSQL, cloud, document-based sources. Quickly link all your data from Amazon Redshift, MongoDB, Hadoop, Snowflake, Apache Solr, Elasticsearch, Impala, and more.
In the era of bigdata, it’s especially important to be mindful of that reality. That’s why today’s smart business leaders are using data-driven storytelling to make an impact on the people around them. He also found that speakers who merely present facts and figures only achieve a 5% recall rate among their audience.
Benefits for Your Application Team With Logi Symphony now available on Google Marketplace, you can optimize budgets, simplify procurement, and access cutting-edge AI and bigdata capabilities all through your Google Workspace application.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























Let's personalize your content