This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Table of Contents 1) Benefits Of BigData In Logistics 2) 10 BigData In Logistics Use Cases Bigdata is revolutionizing many fields of business, and logistics analytics is no exception. The complex and ever-evolving nature of logistics makes it an essential use case for bigdata applications.
“You can have data without information, but you cannot have information without data.” – Daniel Keys Moran. When you think of bigdata, you usually think of applications related to banking, healthcare analytics , or manufacturing. Download our free summary outlining the best bigdata examples! Discover 10.
Making decisions based on data To ensure that the best people end up in management positions and diverse teams are created, HR managers should rely on well-founded criteria, and bigdata and analytics provide these. If a database already exists, the available data must be tested and corrected.
Testing and Data Observability. We have also included vendors for the specific use cases of ModelOps, MLOps, DataGovOps and DataSecOps which apply DataOps principles to machine learning, AI, data governance, and data security operations. . Genie — Distributed bigdata orchestration service by Netflix.
The gaming industry is among those most affected by breakthroughs in data analytics. A growing number of gaming developers are utilizing bigdata to make their content more engaging. It is no wonder these companies are leveraging bigdata, since gamers produce over 50 terabytes of data a day.
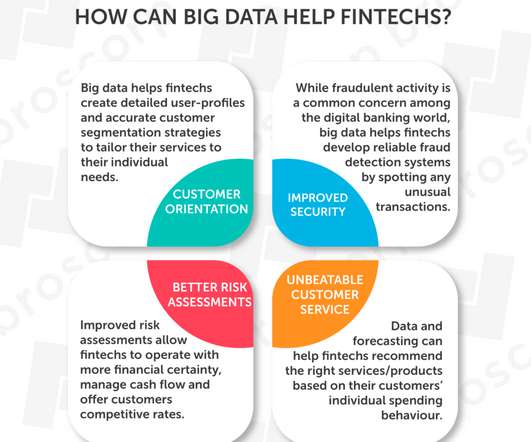
Bigdata has led to many important breakthroughs in the Fintech sector. And BigData is one such excellent opportunity ! BigData is the collection and processing of huge volumes of different data types, which financial institutions use to gain insights into their business processes and make key company decisions.
In June of 2020, Database Trends & Applications featured DataKitchen’s end-to-end DataOps platform for its ability to coordinate data teams, tools, and environments in the entire data analytics organization with features such as meta-orchestration , automated testing and monitoring , and continuous deployment : DataKitchen [link].
Data and bigdata analytics are the lifeblood of any successful business. Getting the technology right can be challenging but building the right team with the right skills to undertake data initiatives can be even harder — a challenge reflected in the rising demand for bigdata and analytics skills and certifications.
To assess the Spark engines performance with the Iceberg table format, we performed benchmark tests using the 3 TB TPC-DS dataset, version 2.13 (our results derived from the TPC-DS dataset are not directly comparable to the official TPC-DS results due to setup differences). 4xlarge instances, for testing both open source Spark 3.5.3
response = client.create( key="test", value="Test value", description="Test description" ) print(response) print("nListing all variables.") variables = client.list() print(variables) print("nGetting the test variable.") Creating a test variable. Creating a test variable. Creating a test variable.
Table of Contents Introduction Machine Learning Pipeline Data Preprocessing Flow of pipeline 1. Loading data into Cloud Storage 3. Loading Data Into Big Query Training the model Evaluating the Model Testing the model Summary Shutting down the […]. Creating the Project in Google Cloud 2.
With this launch of JDBC connectivity, Amazon DataZone expands its support for data users, including analysts and scientists, allowing them to work in their preferred environments—whether it’s SQL Workbench, Domino, or Amazon-native solutions—while ensuring secure, governed access within Amazon DataZone. Choose Test connection.
You’re now ready to sign in to both Aurora MySQL cluster and Amazon Redshift Serverless data warehouse and run some basic commands to test them. Choose Test Connection. This verifies that dbt Cloud can access your Redshift data warehouse. Choose Next if the test succeeded.
Each time, the underlying implementation changed a bit while still staying true to the larger phenomenon of “Analyzing Data for Fun and Profit.” ” They weren’t quite sure what this “data” substance was, but they’d convinced themselves that they had tons of it that they could monetize.
For several years now, the elephant in the room has been that data and analytics projects are failing. Gartner estimated that 85% of bigdata projects fail. We surveyed 600 data engineers , including 100 managers, to understand how they are faring and feeling about the work that they are doing. Automate manual processes.
With a demo hosted on the popular AI platform Huggingface, users can now explore and test JARVIS’s extraordinary capabilities. The AI can connect and collaborate with multiple artificial intelligence models, such as ChatGPT and t5-base, to deliver a final result.
However, attempting to repurpose pre-existing data can muddy the water by shifting the semantics from why the data was collected to the question you hope to answer. ” One of his more egregious errors was to continually test already collected data for new hypotheses until one stuck, after his initial hypothesis failed [4].
Upon checking the S3 data target, we can see the S3 path is now a placeholder and the output format is Parquet. We can ask the following question in Amazon Q: update the s3 sink node to write to s3://xxx-testing-in-356769412531/output/ in CSV format in the same way to update the Amazon S3 data target.
Tens of thousands of customers use Amazon Redshift to process exabytes of data every day to power their analytics workloads. Redshift Test Drive is a tool hosted on the GitHub repository that let customers evaluate which data warehouse configurations options are best suited for their workload.
Testing these upgrades involves running the application and addressing issues as they arise. Each test run may reveal new problems, resulting in multiple iterations of changes. About the Authors Noritaka Sekiyama is a Principal BigData Architect on the AWS Glue team. Python 3.7) to Spark 3.3.0
This allows developers to test their application with a Kafka cluster that has the same configuration as production and provides an identical infrastructure to the actual environment without needing to run Kafka locally. Test the connection to the Amazon MSK server by entering the following command. Trying 127.0.0.1. amazonaws.com.
Language understanding benefits from every part of the fast-improving ABC of software: AI (freely available deep learning libraries like PyText and language models like BERT ), bigdata (Hadoop, Spark, and Spark NLP ), and cloud (GPU's on demand and NLP-as-a-service from all the major cloud providers). IBM Watson NLU.
Query documents with different personas Now let’s test the application using different personas. Modify user access As depicted in the solution diagram, we’ve added a feature in the web interface to allow you to modify user access, which you could use to perform further tests. Refer to Service Quotas for more details.
Prerequisites To walk through the examples in this post, you need the following prerequisites: You can test the incremental refresh of materialized views on standard data lake tables in your account using an existing Redshift data warehouse and data lake. The sample files are ‘|’ delimited text files.
The following is the code for vanilla Parquet: spark.read.parquet(s3://example-s3-bucket/path/to/data).filter((f.col("adapterTimestamp_ts_utc") Test results insights These test results offered the following insights: Accelerated query performance Iceberg improved read operations by up to 52% for unsorted data and 51% for sorted data.
For each service, you need to learn the supported authorization and authentication methods, data access APIs, and framework to onboard and testdata sources. This approach simplifies your data journey and helps you meet your security requirements. Noritaka Sekiyama is a Principal BigData Architect on the AWS Glue team.
To address this, we used the AWS performance testing framework for Apache Kafka to evaluate the theoretical performance limits. We conducted performance and capacity tests on the test MSK clusters that had the same cluster configurations as our development and production clusters.
Bigdata technology is driving major changes in the healthcare profession. In particular, bigdata is changing the state of nursing. Nursing professionals will need to appreciate the importance of bigdata and know how to use it effectively. Bigdata is especially important for the nursing sector.
Here is a list of my top moments, learnings, and musings from this year’s Splunk.conf : Observability for Unified Security with AI (Artificial Intelligence) and Machine Learning on the Splunk platform empowers enterprises to operationalize data for use-case-specific functionality across shared datasets. is here, now!
You can now test the newly created application by running the following command: npm run dev By default, the application is available on port 5173 on your local machine. All Data This tab contains a table that contains all the rows and columns in the table (the unfiltered data).
In case you don’t have sample data available for testing, we provide scripts for generating sample datasets on GitHub. Data and metadata are shown in blue in the following detail diagram. Before that he was a lead developer at the German manufacturer KraussMaffei Technologies, responsible for the development of data platforms.
It is advised to discourage contributors from making changes directly to the production OpenSearch Service domain and instead implement a gatekeeper process to validate and test the changes before moving them to OpenSearch Service. es.amazonaws.com' # e.g. my-test-domain.us-east-1.es.amazonaws.com, 1)[0] data = open(path, 'r').read()
Fujitsu, in collaboration with NVIDIA and NetApp launched AI Test Drive to help address this specific problem and assist data scientists in validating business cases for investment. AI Test Drive functions as an effective AI-as-a-Service solution, and it is already demonstrating strong results. Artificial Intelligence
As Fitch Group continues to innovate and grow, their robust Kafka infrastructure provides a solid foundation for future expansion and the development of new data-driven services, ultimately enhancing their ability to deliver timely and accurate financial insights to their clients.
In essence, data reporting is a specific form of business intelligence that has been around for a while. However, the use of dashboards, bigdata, and predictive analytics is changing the face of this kind of reporting. Ask other key stakeholders within the organization to test your report and offer their feedback.
Also, we designed our test environment without setting the Amazon Redshift Serverless workgroup max capacity parametera key configuration that controls the maximum RPUs available to your data warehouse. By removing this limit, we could clearly showcase how different configurations affect scaling behavior in our test endpoints.
Bigdata is at the heart of all successful, modern marketing strategies. Companies that engage in email marketing have discovered that bigdata is particularly effective. When you are running a data-driven company, you should seriously consider investing in email marketing campaigns.
Are you interested in a career in bigdata? As we said before, there are many careers you can go into with a degree in data science. The BLS reports that there are 113,000 data scientists in the country. Education & Teaching You can use bigdata technology to help improve the field of academia.
Fortunately, bigdata and smart technology are helping hospitalists overcome these issues. Here are some fascinating ways data and smart technology are helping hospitalists. Bigdata and smart technology are helping hospitalists improve billing accuracy in many ways. Improving Billing Processes and Accuracy.
Now, with support for dbt Cloud, you can access a managed, cloud-based environment that automates and enhances your data transformation workflows. This upgrade allows you to build, test, and deploy data models in dbt with greater ease and efficiency, using all the features that dbt Cloud provides.
These organizations often maintain multiple AWS accounts for development, testing, and production stages, leading to increased complexity and cost. Additionally, it can accommodate up to 25 DAGs, providing ample capacity for organizing and managing various data pipelines and processes.
Cloud technology can help students prepare for the test, but they have to use it appropriately. The SAT exam is a paper-based test that’s administered at hundreds of schools and sites around the country (and throughout the year). The good news is that cloud technology makes it easier to understand the format of the test.
Database developers should have experience with NoSQL databases, Oracle Database, bigdata infrastructure, and bigdata engines such as Hadoop. These candidates will be skilled at troubleshooting databases, understanding best practices, and identifying front-end user requirements.
Digital data not only provides astute insights into critical elements of your business but if presented in an inspiring, digestible, and logical format, it can tell a tale that everyone within the organization can get behind. Data visualization methods refer to the creation of graphical representations of information.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content