This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
To achieve this, they aimed to break down data silos and centralize data from various business units and countries into the BMW Cloud Data Hub (CDH). However, the initial version of CDH supported only coarse-grained access control to entire data assets, and hence it was not possible to scope access to data asset subsets.
Amazon DataZone now launched authentication supports through the Amazon Athena JDBC driver, allowing data users to seamlessly query their subscribed data lake assets via popular business intelligence (BI) and analytics tools like Tableau, Power BI, Excel, SQL Workbench, DBeaver, and more.
Over the years, organizations have invested in creating purpose-built, cloud-based data lakes that are siloed from one another. A major challenge is enabling cross-organization discovery and access to data across these multiple data lakes, each built on different technology stacks.
Customers of all sizes and industries use Amazon Simple Storage Service (Amazon S3) to store data globally for a variety of use cases. Customers want to know how their data is being accessed, when it is being accessed, and who is accessing it. With exponential growth in data volume, centralized monitoring becomes challenging.
Today, we’re making available a new capability of AWS Glue DataCatalog that allows generating column-level statistics for AWS Glue tables. Data lakes are designed for storing vast amounts of raw, unstructured, or semi-structured data at a low cost, and organizations share those datasets across multiple departments and teams.
The Role of Catalog in Data Security. Recently, I dug in with CIOs on the topic of data security. Recently, I dug in with CIOs on the topic of data security. What came as no surprise was the importance CIOs place on taking a broader approach to data protection. The Role of the CISO in Data Governance and Security.
Apache Hudi is an open table format that brings database and data warehouse capabilities to data lakes. Apache Hudi helps data engineers manage complex challenges, such as managing continuously evolving datasets with transactions while maintaining query performance.
This is part of our series of blog posts on recent enhancements to Impala. Apache Impala is synonymous with high-performance processing of extremely large datasets, but what if our data isn’t huge? It turns out that Apache Impala scales down with data just as well as it scales up. The entire collection is available here.
The company uses AWS Cloud services to build data-driven products and scale engineering best practices. The company uses AWS Cloud services to build data-driven products and scale engineering best practices. Acast found itself with diverse business units and a vast amount of data generated across the organization.
It’s time to consider data-driven enterprise architecture. The traditional approach to enterprise architecture – the analysis, design, planning and implementation of IT capabilities for the successful execution of enterprise strategy – seems to be missing something … data. That’s right. Strategic Building Blocks.
To help develop a data-driven culture, everyone inside an organization can use Amazon DataZone. To help develop a data-driven culture, everyone inside an organization can use Amazon DataZone. This post guides you through the process of setting up Okta as an identity provider for signing in users to Amazon DataZone.
This blog post is co-written with Raj Samineni from ATPCO. In today’s data-driven world, companies across industries recognize the immense value of data in making decisions, driving innovation, and building new products to serve their customers.
With this update, domain owners can define and enforce metadata requirements for data consumers when they request access to data assets. By making it mandatory for data consumers to provide specific metadata, domain owners can achieve compliance, meet organizational standards, and support audit and reporting needs.
Amazon DataZone enables customers to discover, access, share, and govern data at scale across organizational boundaries, reducing the undifferentiated heavy lifting of making data and analytics tools accessible to everyone in the organization. This is challenging because access to data is managed differently by each of the tools.
Apache Flink is a scalable, reliable, and efficient data processing framework that handles real-time streaming and batch workloads (but is most commonly used for real-time streaming). AWS recently announced that Apache Flink is generally available for Amazon EMR on Amazon Elastic Kubernetes Service (EKS).
AWS Data Pipeline helps customers automate the movement and transformation of data. With Data Pipeline, customers can define data-driven workflows, so that tasks can be dependent on the successful completion of previous tasks. Some customers want a deeper level of control and specificity than possible using Data Pipeline.
Metadata management is key to wringing all the value possible from data assets. However, most organizations don’t use all the data at their disposal to reach deeper conclusions about how to drive revenue, achieve regulatory compliance or accomplish other strategic objectives. Quite simply, metadata is data about data.
In recent years, driven by the commoditization of data storage and processing solutions, the industry has seen a growing number of systematic investment management firms switch to alternative data sources to drive their investment decisions. It was first opened to investors in 1995. CFM assets under management are now $13 billion.
We also delve into details on how to configure data sources and subscription targets for a project using a custom AWS service blueprint. New feature: Custom AWS service blueprints Previously, Amazon DataZone provided default blueprints that created AWS resources required for data lake, data warehouse, and machine learning use cases.
In her current role as VP of UX, Design & Research at Sigma Computing, she deploys human-centric design to support data democratization and analysis. Less than 40 percent of Fortune 1000 companies are managing data as an asset and only 24 percent of executives consider their organization to be data-driven.
Building a data lake on Amazon Simple Storage Service (Amazon S3) provides numerous benefits for an organization. However, many use cases, like performing change data capture (CDC) from an upstream relational database to an Amazon S3-based data lake, require handling data at a record level.
Many organizations operate data lakes spanning multiple cloud data stores. In these cases, you may want an integrated query layer to seamlessly run analytical queries across these diverse cloud stores and streamline your data analytics processes. To achieve this, Oktank envisions a unified data query layer using Athena.
When you build your transactional data lake using Apache Iceberg to solve your functional use cases, you need to focus on operational use cases for your S3 data lake to optimize the production environment. When the catalog property s3.delete-enabled With the s3.delete.tags This property is set to true by default.
Companies are increasingly seeking ways to complement their data with external business partners’ data to build, maintain, and enrich their holistic view of their business at the consumer level. For the purpose of this blog, we will be focusing only on SQL queries.
In this blog post, we will highlight how ZS Associates used multiple AWS services to build a highly scalable, highly performant, clinical document search platform. We use leading-edge analytics, data, and science to help clients make intelligent decisions.
This is a guest blog post co-written with Sumesh M R from Cargotec and Tero Karttunen from Knowit Finland. Cargotec captures terabytes of IoT telemetry data from their machinery operated by numerous customers across the globe. Cargotec’s use cases also required them to create views that span tables and views across catalogs.
AWS Glue is a serverless data integration service that makes it straightforward to discover, prepare, move, and integrate data from multiple sources for analytics, machine learning (ML), and application development. Furthermore, each node (driver or worker) in an AWS Glue job requires an IP address assigned from the subnet.
With the rapid growth of technology, more and more data volume is coming in many different formats—structured, semi-structured, and unstructured. Data analytics on operational data at near-real time is becoming a common need. a new version of AWS Glue that accelerates data integration workloads in AWS.
Amazon Redshift and Tableau empower data analysis. Amazon Redshift is a cloud data warehouse that processes complex queries at scale and with speed. Tableau’s extensive capabilities and enterprise connectivity help analysts efficiently prepare, explore, and share data insights company-wide.
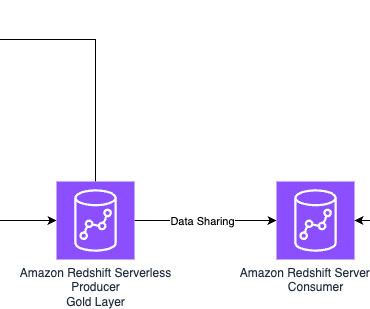
In February 2024, we announced the release of the Data Solutions Framework (DSF) , an opinionated open source framework for building data solutions on AWS. In this post, we demonstrate how to use the AWS CDK and DSF to create a multi-data warehouse platform based on Amazon Redshift Serverless.
There was a time when most CIOs would never consider putting their crown jewels — AKA customer data and associated analytics — into the cloud. And what must organizations overcome to succeed at cloud data warehousing ? What Are the Biggest Drivers of Cloud Data Warehousing? The cloud is no longer synonymous with risk.
With data becoming the driving force behind many industries today, having a modern data architecture is pivotal for organizations to be successful. In this post, we describe Orca’s journey building a transactional data lake using Amazon Simple Storage Service (Amazon S3), Apache Iceberg, and AWS Analytics.
The legacy IT infrastructure to run the business operations — mainly data centers — has a deadline to shift to cloud-based services. The public cloud is increasingly becoming the preferred platform to host data analytics – related projects, such as business intelligence, machine learning (ML), and AI applications. Why FinOps?
Enterprise dataarchitects, data engineers, and business leaders from around the globe gathered in New York last week for the 3-day Strata Data Conference , which featured new technologies, innovations, and many collaborative ideas. 2) When data becomes information, many (incremental) use cases surface.
On Thursday January 6th I hosted Gartner’s 2022 Leadership Vision for Data and Analytics webinar. – In the webinar and Leadership Vision deck for Data and Analytics we called out AI engineering as a big trend. I would take a look at our Top Trends for Data and Analytics 2021 for additional AI, ML and related trends.
The opportunity to work with many clients on their data fabric journey continues to drive and inspire us to achieve even greater heights with our solutions. Key attributes of IBM’s approach to data fabric . Let’s take a look at IBM’s take on some of the specific strengths recognized in Forrester’s Wave below. . Providing the semantic.
Lots of innovation is happening, with new technologies emerging in areas such as data and AI, payments, cybersecurity and risk management, to name a few. Lots of innovation is happening, with new technologies emerging in areas such as data and AI, payments, cybersecurity and risk management, to name a few.
Amazon SageMaker Lakehouse is a unified, open, and secure data lakehouse that now seamlessly integrates with Amazon S3 Tables , the first cloud object store with built-in Apache Iceberg support. You can then query, analyze, and join the data using Redshift, Amazon Athena , Amazon EMR , and AWS Glue.
They help our customers architect their modern data stack , tying in Snowflake or Fivetran where they’re needed, for example. They’re also instrumental in connecting us to the key decision-makers that need a data intelligence platform. Please tell us about your background. They can trust us.
Yesterday, we announced Amazon SageMaker Unified Studio (Preview), an integrated experience for all your data and AI and Amazon SageMaker Lakehouse to unify data – from Amazon Simple Storage Service (S3) to third-party sources such as Snowflake. First, end-users often have to set up connections to data sources on their own.
Organizations are building data-driven applications to guide business decisions, improve agility, and drive innovation. Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services.
In our previous thought leadership blog post Why a Cloud Operating Model we defined a COE Framework and showed why MuleSoft implemented it and the benefits they received from it. We also implemented a layered approach that included collection, preparation, and enrichment making it straightforward to identify areas that affect data accuracy.
To further enhance their B2B marketing capabilities, organizations are now looking to fully use their marketing data for more informed decision-making and strategy optimization. The agile, serverless nature of AWS Glue meets a range of data analytics needs while reducing costs.
This is a joint blog post co-authored with Martin Mikoleizig from Volkswagen Autoeuropa. Volkswagen Autoeuropa aims to become a data-driven factory and has been using cutting-edge technologies to enhance digitalization efforts. The lead time to access data was often from several days to weeks.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















































Let's personalize your content