This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This post explores how to start using Delta Lake UniForm on Amazon Web Services (AWS). Note that the extra package ( delta-iceberg ) is required to create a UniForm table in AWS Glue Data Catalog. Amazon S3 and AWS Glue Data Catalog : These are used to manage the underlying files and the catalog of the Delta Lake UniForm table.
To implement this solution, complete the following steps: Set up Zero-ETL integration from the AWS Management Console for Amazon Relational Database Service (Amazon RDS). An AWS Identity and Access Management (IAM) user with sufficient permissions to interact with the AWS Management Console and related AWS services.
Enterprise data is brought into data lakes and data warehouses to carry out analytical, reporting, and data science use cases using AWS analytical services like Amazon Athena , Amazon Redshift , Amazon EMR , and so on. These examples use synthetic datasets created in AWS Glue and Amazon S3. Table metadata is fetched from AWS Glue.
Cloud certifications, specifically in AWS and Microsoft Azure, were most strongly associated with salary increases. 64% of the respondents took part in training or obtained certifications in the past year, and 31% reported spending over 100 hours in training programs, ranging from formal graduate degrees to reading blog posts.
In this post, we dive into the newly released feature of Amazon Redshift Data API support for SSO, Amazon Redshift RBAC for row-level security (RLS) and column-level security (CLS), and trusted identity propagation with AWS IAM Identity Center to let corporate identities connect to AWS services securely.
The performance data you can use on the Amazon Redshift console falls into two categories: Amazon CloudWatch metrics – Helps you monitor the physical aspects of your cluster or serverless, such as resource utilization, latency, and throughput. Ekta Ahuja is an Amazon Redshift Specialist Solutions Architect at AWS.
Read the complete blog below for a more detailed description of the vendors and their capabilities. Because it is such a new category, both overly narrow and overly broad definitions of DataOps abound. AWS Code Deploy. AWS Code Pipeline. Download the 2021 DataOps Vendor Landscape here. DataOps is a hot topic in 2021.
In this post, we showcase how to use AWS Glue with AWS Glue Data Quality , sensitive data detection transforms , and AWS Lake Formation tag-based access control to automate data governance. We use AWS CloudFormation to provision the resources. This gets tedious and delays the data adoption across the enterprise.
Amazon AppFlow , a fully managed data integration service, has been at the forefront of streamlining data transfer between AWS services, software as a service (SaaS) applications, and now Google BigQuery. Next, provide AWS Glue Data Catalog settings to create a table for further analysis. Choose Create bucket. Choose Create bucket.
In 2022, we announced that you can enforce fine-grained access control policies using AWS Lake Formation and query data stored in any supported file format using table formats such as Apache Iceberg , Apache Hudi, and more using Amazon Athena queries. An AWS Glue crawler is integrated on top of S3 buckets to automatically detect the schema.
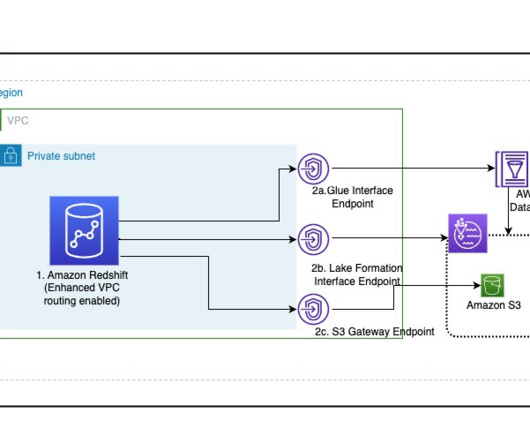
Redshift Spectrum uses the AWS Glue Data Catalog as a Hive metastore. AWS Lake Formation offers a straightforward and centralized approach to access management for S3 data sources. Lake Formation uses the AWS Glue Data Catalog to provide access control for Amazon S3. Lake Formation interface endpoint. Amazon S3 gateway endpoint.
Many AWS customers adopted Apache Hudi on their data lakes built on top of Amazon S3 using AWS Glue , a serverless data integration service that makes it easier to discover, prepare, move, and integrate data from multiple sources for analytics, machine learning (ML), and application development.
AWS Deep Learning Containers now support Tensorflow 2.0 AWS Deep Learning Containers are docker images which are preconfigured for deep learning tasks. Build a custom classifier using AWS Comprehend AWS Comprehend is a Natural Language Processing (NLP) service. This blog post acts more like a step-by-step tutorial.
It is considered a “complex to license and expensive tool” that often overlaps with other products in this category. AWS Data Pipeline : AWS Data Pipeline can be used to schedule regular processing activities such as SQL transforms, custom scripts, MapReduce applications, and distributed data copy. Conclusion.
Apache Iceberg integration is supported by AWS analytics services including Amazon EMR , Amazon Athena , and AWS Glue. In early 2022, AWS announced general availability of Athena ACID transactions, powered by Apache Iceberg. AWS Glue 3.0 The following is an example Iceberg catalog with AWS Glue implementation.
With OCSF support, the service can normalize and combine security data from AWS and a broad range of enterprise security data sources. We also walk you through how to use a series of prebuilt visualizations to view events across multiple AWS data sources provided by Security Lake.
You can also use the list-recommendations command in the AWS Command Line Interface (AWS CLI) to invoke the Advisor recommendations from the command line and automate the workflow through scripts. For Stack name , enter a name for the stack, for example, blog-redshift-advisor-recommendations.
AWS Glue is a serverless data integration service that makes it straightforward to discover, prepare, move, and integrate data from multiple sources for analytics, machine learning (ML), and application development. Furthermore, each node (driver or worker) in an AWS Glue job requires an IP address assigned from the subnet.
AWS Glue interactive sessions allow you to run interactive AWS Glue workloads on demand, which enables rapid development by issuing blocks of code on a cluster and getting prompt results. This feature existed for AWS Glue jobs and is now available for interactive sessions.
You can find more information in this release announcement blog post and in this technical deep dive blog post. Functions as a Service (FaaS) is a category of cloud computing services that all main cloud providers are offering (AWS Lambda, Azure Functions, Google Cloud Functions, etc). Functions as a Service.
AWS Lake Formation is a fully managed service that simplifies building, securing, and managing data lakes. In this post, we share the solution using Amazon Redshift role based access control (RBAC) and AWS Lake Formation tag-based access control for federated users to query your data lake using Amazon Redshift Spectrum.
The company uses AWS Cloud services to build data-driven products and scale engineering best practices. It’s worth mentioning that they also have other product and tech teams, including operational or business teams, without AWS accounts. Each team owns at least two AWS accounts, up to 10 accounts, depending on the ownership.
This blog post provides a step-by-step guide for building a multimodal search solution using OpenSearch Service. This direct integration eliminates the need for an additional component (for example, AWS Lambda ) to facilitate the exchange between the two services. Select Map and confirm the user or role shows up under Mapped users.
Still, to make your data lake workloads highly available in an unlikely outage situation, you can replicate your S3 data to another AWS Region as a backup. The following examples are also available in the sample notebook in the aws-samples GitHub repo for quick experimentation. availability. parquet 2021-11-01 06:00:10 6.1
In our previous blog, we talked about the four paths to Cloudera Data Platform. . If you haven’t read that yet, we invite you to take a moment and run through the scenarios in that blog. As we touched on in the previous blog, the decision to upgrade or migrate may seem difficult to evaluate at first glance. In-place Upgrade.
At Cloudera, supporting our customers through their complete data journey also means providing access to game-changing technologies with trusted partners like Amazon Web Services (AWS). . Cloudera and AWS: Harnessing the Power of Data and Cloud . Customer use cases can be grouped into three categories. .
AWS offers a broad selection of managed real-time data streaming services to effortlessly run these workloads at any scale. Experiencing business hyper-growth, Nexthink migrated to AWS to overcome the scaling limitations of on-premises solutions. Simone Pomata is Senior Solutions Architect at AWS.
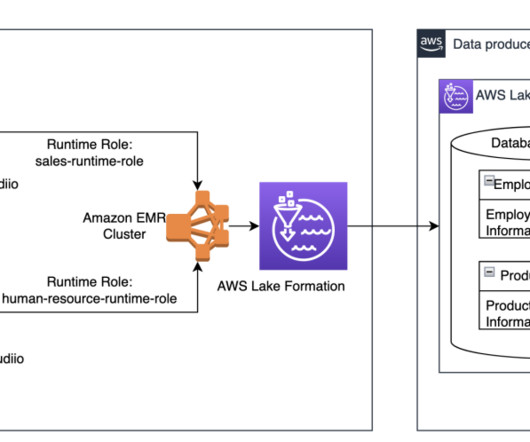
Data is often stored in data lakes managed by AWS Lake Formation , enabling you to apply fine-grained access control through a simple grant or revoke mechanism. The jobs on the EMR cluster will use this runtime role to access AWS resources. Raw data is stored in S3 buckets and catalogued in the AWS Glue Data Catalog.
Using Snowpipe for data ingestion to AWS. Snowpipe data ingestion might be too slow for three use categories: real-time personalization, operational analytics, and security. AWS Glue to Snowflake ingestion. AWS Glue provides a fully managed environment that integrates easily with Snowflake’s data warehouse as a service.
In this blog, I’ll talk about the data catalog and data intelligence markets, and the future for Alation. While we’re widely credited with driving the creation of the data catalog category 1 , Alation isn’t just a data catalog company. We’re excited to continue to innovate and lead the data intelligence category for years to come!
In this blog post, we demonstrate how you can use DJL within Kinesis Data Analytics for Apache Flink for real-time machine learning inference. We provide sample code, architecture diagrams, and an AWS CloudFormation template so you can follow along and employ ResNet-18 as your classifier to make real-time predictions.
Automatic cloud platform backups, using tools from the CSP platforms, like AWS. Database backups: The third category of backups are database backups. zip` in AWS, making them portable and easy to transfer between different systems and environments. Manual backups, created at will by the user. S3 Cross-Region Replication (CRR) a.
It contains different categories of columns: Keys – It contains two types of keys: customer_sk is the primary key of this table. Use an AWS Glue crawler to parse the data files and register tables in the AWS Glue Data Catalog. Create an external schema in Amazon Redshift to point to the AWS Glue database containing these tables.
In this blog post, we will highlight how ZS Associates used multiple AWS services to build a highly scalable, highly performant, clinical document search platform. We developed and host several applications for our customers on Amazon Web Services (AWS). Specialist SA-Data working with AWS India Public sector customers.
Sirius continues to build on its strategic partnership with Amazon Web Services (AWS) by tirelessly working to elevate our technical expertise and our ability to help businesses succeed. Because of this, we are proud to announce that we have successfully achieved AWS Storage Competency status.
To address that, on this blog I've shared something I call the ladders of awesomeness – my view of what the entire evolutionary path looks like. It is very hard to capture an entire keynote, and a life-time of bruises that the wisdom above reflects, in a simple blog post. Why do I say irritating? I love this report.
In this blog we will take you through a persona-based data adventure, with short demos attached, to show you the A-Z data worker workflow expedited and made easier through self-service, seamless integration, and cloud-native technologies. The post An A-Z Data Adventure on Cloudera’s Data Platform appeared first on Cloudera Blog.
If you’d like to know more background about how we use Kafka at Stitch Fix, please refer to our previously published blog post, Putting the Power of Kafka into the Hands of Data Scientists. We have been using separate production and staging VPCs since we initially started using AWS.
For example, if you have a requirement such that one Product Category would have different Threshold values (e.g. KPI Configuration Table to store the upper and lower Yellow values for each Product Category, and for a defined set of periods. Use the AW-DimProductCategoryKPI.sql table creation script as a sample. Prerequisites.
In the first blog of the Universal Data Distribution blog series , we discussed the emerging need within enterprise organizations to take control of their data flows. In this second installment of the Universal Data Distribution blog series, we will discuss a few different data distribution use cases and deep dive into one of them. .
If you fall in the "Analyst unwilling to do the hard work" category, I'm afraid I can't help you. If you fall into the "Analyst really wanting to do the hard work but does not have the connection to Superiors, or other teams, and looking for any way out to identify business purpose" category. Aw, come on!
That’s why when it was announced that Alation achieved Amazon Web Services (AWS) Data and Analytics Competency in the data governance and security category, we were not only honored to receive this coveted designation, but we were also proud that it confirms the synergy — and customer benefits — of our AWS partnership.
The role of AWS and cloud security in life sciences However, with greater power comes great responsibility. Most life sciences companies are raising their security posture with AWS infrastructure and services. Organizations like Moderna and Bristol Myers Squibb have chosen AWS to run their regulated workloads.
For example, an AI system could be trained to classify emails into categories like “sensitive” or “restricted” based on patterns it has learned from a training dataset. It could be further trained to classify data into important categories such as PII, PHI and PCI, increasing efficiency in both data classification, and ultimately security.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content